
Abstract
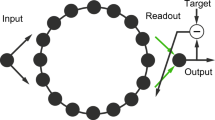
Recurrent neural networks of the reservoir computing (RC) type have been found useful in various time-series processing tasks with inherent non-linearity and requirements of variable temporal memory. Specifically for delayed response tasks involving the transient memorization of information (temporal memory), self-adaptation in RC is crucial for generalization to varying delays. In this work using information theory, we combine a generalized intrinsic plasticity rule with a local information dynamics based schema of reservoir neuron leak adaptation. This allows the RC network to be optimized in a self-adaptive manner with minimal parameter tuning. Local active information storage, measured as the degree of influence of previous activity on the next time step activity of a neuron, is used to modify its leak-rate. This results in RC network with non-uniform leak rate which depends on the time scales of the incoming input. Intrinsic plasticity (IP) is aimed at maximizing the mutual information between each neuron’s input and output while maintaining a mean level of activity (homeostasis). Experimental results on two standard benchmark tasks confirm the extended performance of this system as compared to the static RC (fixed leak and no IP) and RC with only IP. In addition, using both a simulated wheeled robot and a more complex physical hexapod robot, we demonstrate the ability of the system to achieve long temporal memory for solving a basic T-shaped maze navigation task with varying delay time scale.








Similar content being viewed by others


Notes
NARMA-30 is the 30th order non-linear auto-regressive moving average.
It is based on the Open Dynamics Engine (ODE). More details of the LPZRobot simulator can be found at http://robot.informatik.uni-leipzig.de/software/.
The real robot experiment showing the cue signal activation and the corresponding turning behavior is demonstrated in a video clip at http://manoonpong.com/STM/AMOSII_stm.wmv
References
Antonelo E, Schrauwen B, Stroobandt D (2008) Mobile robot control in the road sign problem using reservoir computing networks. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), pp 911–916
Bertschinger N, Natschläger T (2004) Real-time computation at the edge of chaos in recurrent neural networks. Neural Comput 16:1413–1436
Bernacchia A, Seo H, Lee D, Wang XJ (2011) A reservoir of time constants for memory traces in cortical neurons. Nat Neurosci 14(3):366–372
Boedecker J, Obst O, Mayer MN, Asada M (2009) Initialization and self-organized optimization of recurrent neural network connectivity. HFSP J 5:340–349
Buonomano DV, Laje R (2010) Population clocks: motor timing with neural dynamics. Trends Cogn Sci 14:520–527
Büsing L, Schrauwen B, Legenstein R (2010) Connectivity, dynamics, and memory in reservoir computing with binary and analog neurons. Neural Comput 22:1272–1311
Desai NS, Rutherford LC, Turrigiano GG (1999) Plasticity in the intrinsic excitability of cortical pyramidal neurons. Nat Neurosci 2:515–520
Ganguli S, Dongsung H, Sompolinsky H (2008) Memory traces in dynamical systems. Proc Natl Acad Sci USA 105:18970–18975
Jaeger H (2001) Short term memory in echo state networks. GMD Report 152, German National Research Center for Information Technology
Jaeger H (2003) Adaptive nonlinear system identification with echo state networks. In: Advances in Neural Information Processing Systems, pp 593–600
Jaeger H, Haas H (2004) Harnessing nonlinearity: predicting chaotic systems and saving energy in wireless communication. Science 2:78–80
Jaeger H, Lukosevicius M, Popovici D, Siewert U (2007) Optimization and applications of echo state networks with leaky-integrator neurons. Neural Netw 20:335–352
Jaeger H (2007) Discovering multiscale dynamical features with hierarchical echo state networks (Tech. Rep. No. 10). Jacobs University, Bremen
Li C (2011) A model of neuronal intrinsic plasticity. IEEE Trans Auton Ment Dev 3:277–284
Lizier TJ, Pritam M, Prokopenko M (2011) Information dynamics in small-world boolean networks. Artif Life 17:293–314
Lizier JT (2012) JIDT: an information-theoretic toolkit for studying the dynamics of complex systems. http://code.google.com/p/information-dynamics-toolkit/
Lizier TJ, Prokopenko M, Zomaya AY (2012) Local measures of information storage in complex distributed computation. Inf Sci 208:39–54
Lukosevicius M, Jaeger H (2009) Reservoir computing approaches to recurrent neural network training. Comput Sci Rev 3:127–149
Maass W, Natschläger T, Markram H (2004) Computational models for generic cortical microcircuits. In: Computational neuroscience: a comprehensive approach, chapter 18, pp 575–605
Manoonpong P, Kolodziejski C, Wörgötter F, Morimoto J (2013a) Combining correlation-based and reward-based learning in neural control for policy improvement. Adv Complex Syst (in press)
Manoonpong P, Parlitz U, Wörgötter F (2013b) Neural control and adaptive neural forward models for insect-like, energy-efficient, and adaptable locomotion of walking machines. Front Neural Circuits 7:12. doi:10.3389/fncir.2013.00012
Ozturk MC, Xu D, Prncipe JC (2007) Analysis and design of echo state networks. Neural Comput 19:111–138
Paleologu C, Benesty J, Ciochino S (2008) A robust variable forgetting factor recursive least-squares algorithm for system identification. IEEE Signal Process Lett 15:597–600
Ren G, Chen W, Kolodziejski C, Wörgötter F, Dasgupta S, Manoonpong P (2012) Multiple chaotic central pattern generators for locomotion generation and leg damage compensation in a hexapod robot. In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp 2756–2761
Schrauwen B, Wardermann M, Verstraeten D, Steil JJ, Stroobandt D (2008) Improving reservoirs using intrinsic plasticity. Neurocomputing 71:1159–1171
Shi Z, Han M (2007) Support vector echo-state machine for chaotic time-series prediction. IEEE Trans Neural Netw 18:359–372
Sompolinsky H, Crisanti A, Sommers HJ (1988) Chaos in random neural networks. Phys Rev Lett 61:259–262
Steingrube S, Timme M, Wörgötter F, Manoonpong P (2010) Self-organized adaptation of a simple neural circuit enables complex robot behaviour. Nat Phys 6:224–230
Sussillo D, Abbott LF (2009) Generating coherent patterns of activity from chaotic neural networks. Neuron 4:544–557
Tetzlaff C, Kolodziejski C, Markelic I, Wörgötter F (2012) Time scales of memory, learning, and plasticity. Biol Cybern 6:715–26
Triesch J (2007) Synergies between intrinsic and synaptic plasticity mechanisms. Neural Comput 4:885–909
Turrigiano G, Abbott LF, Marder E (1994) Activity-dependent changes in the intrinsic properties of cultured neurons. Science 264:974–977
Ungerleider LG, Courtney SM, Haxby JV (1998) A neural system for human visual working memory. Proc Natl Acad Sci USA 95:883–890
Yamashita Y, Tani J (2008) Emergence of Functional hierarchy in a multiple timescale neural network model: a humanoid robot experiment. PLoS Comput Biol 4(11):e1000220. doi:10.1371/journal.pcbi.1000220
Acknowledgments
The research leading to these results has received funding from the Emmy Noether Program DFG, MA4464/3-1, by the European Communitys Seventh Framework Programme FP7/2007-2013 (Specific Programme Cooperation, Theme3, Information and Communication Technologies) under grant agreement no.270273, Xperience, by the Federal Ministry of Education and Research(BMBF) by grants to the Bernstein Center for Computational Neuroscience (BCCN) Göttingen, grant number 01GQ1005A, project D1 and by the Max Planck Research School for Physics of Biological and Complex Systems.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
The activation of each reservoir neuron with a \(\tt{tanh}\) non-linearity with slope(a) and shape(b) parameters can be represented as \(\theta = \tt{tanh}(ax+b).\) The activations are time dependent as shown in Eq. (4), however here we neglect the time variable for mathematical convenience. The tanh non-linearity can be represented in an exponential form as follows:
Differentiating this w.r.t x, a and b and representing in terms of θ we get the following set of base equations:
The probability distribution of the two-parameter Weibull random variable θ is given as follows:
Inorder to find a stochastic rule for the calculation of the neuron transfer functin parameters a and b, we need to minimize the Kullback–Leibler (KL) divergence between the real output distribution f θ and the desired distribution f weib . The KL-divergence (D KL (f θ , f weib )) is given by:
Using the relation \(f_\theta(\theta) = \frac{f_x(x)}{\frac{\partial\theta}{\partial x}}\) for a single neuron with input x and output θ and representing the integrals in terms of the expectation(E) quantities, the above relation can be simplified to (here C is a constant):
Using the partial derivatives from Eq. (18) and differentiating D w.r.t the parameter b yields:
Similarly differentiating D w.r.t the parameter a results in:
From the above equations we get the following on-line learning rule with stochastic gradient descent with learning rate η
Note: This relationship between the neuron parameter update rules (\(\Updelta a\) and \(\Updelta b\)) is generic and valid irrespective of the neuron non-linearity or target probability distribution.
Rights and permissions
About this article
Cite this article
Dasgupta, S., Wörgötter, F. & Manoonpong, P. Information dynamics based self-adaptive reservoir for delay temporal memory tasks. Evolving Systems 4, 235–249 (2013). https://doi.org/10.1007/s12530-013-9080-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12530-013-9080-y