
Abstract
In this paper, we present a cooperative primal-dual method to solve the uncapacitated facility location problem exactly. It consists of a primal process, which performs a variation of a known and effective tabu search procedure, and a dual process, which performs a lagrangian branch-and-bound search. Both processes cooperate by exchanging information which helps them find the optimal solution. Further contributions include new techniques for improving the evaluation of the branch-and-bound nodes: decision-variable bound tightening rules applied at each node, and a subgradient caching strategy to improve the bundle method applied at each node.



Similar content being viewed by others
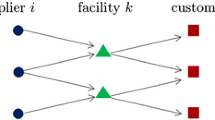
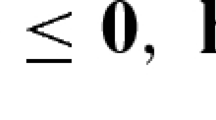

Notes
Naturally, in a practical setting, this argument may be completely irrelevant. Furthermore, our method may benefit from having more than just one primal process. We can easily imagine that better results may be achieved by running several different primal heuristics concurrently in addition to our tabu search procedure.
References
Barahona, F., Anbil, R.: The volume algorithm: producing primal solutions with a subgradient method. Math. Program. 87(3), 385–399 (2000)
Beasley, J. E.: Lagrangean heuristics for location problems. Eur. J. Oper. Res. 65(3), 383–399 (1993)
Beltran, C., Tadonki, C., Vial, J. P.: Solving the p-median problem with a semi-lagrangian relaxation. Comput. Optim. Appl. 35(2), 239–260 (2006)
Beltran-Royo, C., Vial, J.P., Alonso-Ayuso, A.: Semi-lagrangian relaxation applied to the uncapacitated facility location problem. Comput. Optim. Appl. 51(1), 387–409 (2012)
Bilde, O., Krarup, J.: Sharp lower bounds and efficient algorithms for the simple plant location problem. Ann. Discret. Math. 1, 79–97 (1977)
Bloom, B. H.: Space/time trade-offs in hash coding with allowable errors. Commun. ACM 13(7), 422–426 (1970)
Byrka, J., Aardal, K.: An optimal bifactor approximation algorithm for the metric uncapacitated facility location problem. SIAM J. Comput. 39(6), 2212–2231 (2010)
Conn, A. R., Cornuejols, G.: A projection method for the uncapacitated facility location problem. Math. Program. 46(1), 273–298 (1990)
Cornuejols, G., Nemhauser, G.L., Wolsey, L.A.: The uncapacitated facility location problem. In: Mirchandani, P.B., Francis, R.L. (eds.) Discrete Location Theory, pp. 1–54. Wiley, New York (1983)
Cura, T.: A parallel local search approach to solving the uncapacitated warehouse location problem. Comput. Ind. Eng. 59(4), 1000–1009 (2010)
Erlenkotter, D.: A dual-based procedure for uncapacitated facility location. Oper. Res. 26(6), 992–1009 (1978)
Flaxman, A. D., Frieze, A. M., Vera, J. C.: On the average case performance of some greedy approximation algorithms for the uncapacitated facility location problem. Comb. Probab. Comput. 16(05), 713–732 (2007)
Galvão, R. D., Raggi, L. A.: A method for solving to optimality uncapacitated location problems. Ann. Oper. Res. 18(1), 225–244 (1989)
Ghosh, D.: Neighborhood search heuristics for the uncapacitated facility location problem. Eur. J. Oper. Res. 150(1), 150–162 (2003)
Glover, F.: A template for scatter search and path relinking. In: Artificial evolution, pp. 1–51. Springer, Berlin (1998)
Goldengorin, B., Ghosh, D., Sierksma, G.: Branch and peg algorithms for the simple plant location problem. In: Computers and operations research. Comput. Oper. Res. 30(1), 967–981 (2003)
Goldengorin, B., Tijssen, G. A., Ghosh, D., Sierksma, G.: Solving the simple plant location problem using a data correcting approach. J. Global Optim. 25(4), 377–406 (2003)
Guner, A. R., Sevkli, M.: A discrete particle swarm optimization algorithm for uncapacitated facility location problem. J. Artif. Evol. Appl. 2008, 1–9 (2008)
Hansen, P., Brimberg, J., Urošević, D., Mladenović, N.: Primal-dual variable neighborhood search for the simple plant-location problem. INFORMS J. Comput. 19(4), 552 (2007)
Hiriart-Urruty, J.B., Lemaréchal, C.: Convex analysis and minimization algorithms: Fundamentals, vol. 305. Springer, Berlin (1996)
Homberger, J., Gehring, H.: A two-level parallel genetic algorithm for the uncapacitated warehouse location problem. In: Hawaii international conference on system sciences, proceedings of the 41st Annual, p. 67. IEEE (2008)
Julstrom, B.: A permutation coding with heuristics for the uncapacitated facility location problem. Recent advances in evolutionary computation for combinatorial optimization. pp. 295–307 (2008)
Körkel, M.: On the exact solution of large-scale simple plant location problems. Eur. J. Oper. Res. 39(2), 157–173 (1989)
Krarup, J., Pruzan, P. M.: The simple plant location problem: survey and synthesis. Eur. J. Oper. Res. 12(1), 36–81 (1983)
Kratica, J., Tošic, D., Filipović, V., Ljubić, I.: Solving the simple plant location problem by genetic algorithm. Oper. Res. 35(1), 127–142 (2001)
Labbe, M., Louveaux, F.: Location problems. In: Dell’Amico, M., Maffioli, F., Martello, S. (eds.) Annotated bibliographies in combinatorial optimization, pp. 261–281. Wiley, New York (1997)
Letchford, A. N., Miller, S. J.: An aggressive reduction scheme for the simple plant location problem. Tech. rep., Department of Management Science, Lancaster University (2011)
Letchford, A. N., Miller, S. J.: Fast bounding procedures for large instances of the simple plant location problem. Comput. Oper. Res. 39(5), 985–990 (2012)
Li, S.: A 1.488 approximation algorithm for the uncapacitated facility location problem. Automata, languages and programming, pp. 77–88 (2011)
Mahdian, M., Ye, Y., Zhang, J.: Approximation algorithms for metric facility location problems. SIAM J. Comput. 36(2), 411–432 (2006)
Michel, L., Van Hentenryck, P.: A simple tabu search for warehouse location. Eur. J. Oper. Res. 157(3), 576–591 (2004)
Mladenović, N., Brimberg, J., Hansen, P.: A note on duality gap in the simple plant location problem. Eur. J. Oper. Res. 174(1), 11–22 (2006)
Muter, İ., Birbil, S. I., Sahin, G.: Combination of metaheuristic and exact algorithms for solving set covering-type optimization problems. INFORMS J. Comput. 22(4), 603–619 (2010)
Nesterov, Y.: Smooth minimization of non-smooth functions. Math. Program. 103(1), 127–152 (2005)
Resende, M. G.C., Werneck, R. F.: A hybrid multistart heuristic for the uncapacitated facility location problem. Eur. J. Oper. Res. 174(1), 54–68 (2006)
Sun, M.: Solving the uncapacitated facility location problem using tabu search. Comput. Oper. Res. 33(9), 2563–2589 (2006)
Acknowledgments
We wish to thank Paul-Virak Khuong who kindly helped us with our code, improving its performance significantly. We are also grateful to Antonio Frangioni for his bundle method implementation and for taking the time to answer our questions. Finally, we wish to thank the referees and editors which helped improve this paper.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: Cache implementation details
An efficient implementation of \(\mathcal {C}\) is crucial to its performance. In our implementation, \(\mathcal {C}\) is a FIFO queue whose maximal size is a predefined parameter. Consequently, an insertion of a new element into a full \(\mathcal {C}\) is preceded by the removal of its oldest element. When inserting a new element into \(\mathcal {C}\), our implementation does not examine the contents of \(\mathcal {C}\) to detect if it is already present, but instead it tests its presence using a counting Bloom filter. A Bloom filter is a data structure originally proposed by Bloom [6] which allows testing efficiently whether a set contains an element (with occasional false positives, but no false negatives). A counting Bloom filter is a variant defined using any vector \(\varvec{\mathbf {\beta }}\) of positive integers and a set \(H\) of different hash functions \(h \in H\) which each map any element possibly in \(\mathcal {C}\) to an index of \(\varvec{\mathbf {\beta }}\):
-
if an element \(e\) is added into \(\mathcal {C}\), then increment \(\varvec{\mathbf {\beta }}_{h(e)}\) by 1 for all \(h \in H\),
-
therefore an element \(e\) is certainly not in \(\mathcal {C}\) if there exists \(h \in H\) for which \(\varvec{\mathbf {\beta }}_{h(e)} = 0\),
-
if an element \(e\) is removed from \(\mathcal {C}\), then decrement \(\varvec{\mathbf {\beta }}_{h(e)}\) by 1 for all \(h \in H\).
Bloom filters are efficient in time and in space even for very large sets. By hard-coding the maximum size of \(\mathcal {C}\) to \(2^{16}-1\) elements, we implemented \(\varvec{\mathbf {\beta }}\) as an array of 16-bit unsigned integers. In our implementation, the dimension of this array is in the low hundred thousands, and \(|H| = 7\). As a consequence, the probability of false positives when testing whether \(e \in \mathcal {C}\) is less than 1%.
When trying to insert a new element \(e\) into \(\mathcal {C}\), the following steps are performed:
-
1.
If \(\varvec{\mathbf {\beta }}_{h(e)} > 0\) for all \(h \in H\), then \(e\) is probably already in \(\mathcal {C}\): go to step 4.
-
2.
If \(\mathcal {C}\) is full, then remove the oldest element \(e'\) in \(\mathcal {C}\) and decrement \(\varvec{\mathbf {\beta }}_{h(e')}\) by 1 for all \(h \in H\).
-
3.
Insert \(e\) into \(\mathcal {C}\) and increment \(\varvec{\mathbf {\beta }}_{h(e)}\) by 1 for all \(h \in H\).
-
4.
Done.
The counting Bloom filter thus ensures the unicity of the elements in \(\mathcal {C}\).
Appendix B: Bundle method iteration limits
Recall that the elements stored in \(\mathcal {C}\) are key-value pairs specifying first-order outer approximations of lagrangian dual functions, and the purpose of \(\mathcal {C}\) is to provide valid approximations to populate the bundle. Recall also that in our method we apply a bundle method during the evaluation of each node \((\varvec{\mathbf {p}}{},\underline{n}{},\overline{n}{},{\bar{\varvec{\mathbf {\mu }}}})\) selected in \(\mathcal {Q}\) by the Branch-and-bound procedure, and that the initial trial point \(\varvec{\mathbf {\mu }}^{(0)}\) is set to \(\bar{\varvec{\mathbf {\mu }}}\), i.e. the best vector of multipliers found for the parent node. Once our implementation has identified a subset \(S\) of valid \((\varvec{\mathbf {\sigma }}, \epsilon )\) pairs present in \(\mathcal {C}\), it does not immediately update the bundle with all pairs in \(S\). We have found it more convenient to update the bundle using at most \(b\) pairs in \(S\), with \(b\) being the maximum bundle size minus 1. This seemingly arbitrary choice was partly due to certain limitations of [B]TT (the bundle method implementation which we use), however it seems to be effective. In the case where the valid subset size exceeds this number, we update the bundle with the \(b\) pairs in \(S\) selected as follows: let \(\varvec{\mathbf {\mu }}^{(0)}\) be the initial trial point of the bundle method, we select \((\varvec{\mathbf {\sigma }}, \epsilon ) \in S\) minimizing the value \(\sum _{j=1}^m\varvec{\mathbf {\mu }}^{(0)} \varvec{\mathbf {\sigma }}_j + \epsilon \). In this manner, we select the most accurate first-order outer approximations, the value \(\sum _{j=1}^m\varvec{\mathbf {\mu }}^{(0)} \varvec{\mathbf {\sigma }}_j + \epsilon - \phi (\varvec{\mathbf {p}}{},\underline{n}{},\overline{n}{},{\varvec{\mathbf {\mu }}^{(0)}})\) being the error at \(\varvec{\mathbf {\mu }}^{(0)}\) of the approximation defined by \((\varvec{\mathbf {\sigma }}, \epsilon )\).
Recall that in our implementation, a hard limit on the number of iterations to be performed by an application of the bundle method is set. This is either iter_limit_initial for the very first application (at the beginning of which the cache is empty), or iter_limit_other for the others. In all applications other than the first, we use iter_limit_other - \(\min \{b, |S|\}\) as the actual iteration limit. In this manner, and provided that iter_limit_other >\(b\), the intensity of the search for the optimal multiplier is inversely proportional to the size of the initial bundle, and hence indirectly to the quality of the model of the lagrangian dual.
Appendix C: Fast floating point arithmetic
A large part of the computational effort is expended in the following computations within the bundle method:
-
computing reduced costs \(\bar{\varvec{\mathbf {c}}}^{\varvec{\mathbf {\mu }}}\),
-
generating a subgradient \(\varvec{\mathbf {\sigma }}^{(t)}\),
-
computing \(\sum _{j=1}^m\varvec{\mathbf {\mu }}_j^{(0)} \varvec{\mathbf {\sigma }}_j + \epsilon \).
While the theoretical complexity of these operations cannot be reduced, in practice we can speed these up by performing as many of them as possible in the SSE registers which are now standard on x86 processors. Consider the computation of the reduced costs given \(\varvec{\mathbf {\mu }}\in \mathbb {R}^m\):
The sum of the minima can be performed in the SSE registers several minima at a time. Similarly, the computation of \(\sum _{j=1}^m\varvec{\mathbf {\mu }}_j^{(0)} \varvec{\mathbf {\sigma }}_j + \epsilon \) for all suitable \((\varvec{\mathbf {\sigma }},\epsilon )\) pairs identified at the beginning of a bundle method consists mainly of a dot product. This operation can be performed by the BLAS function ddot, and recent implementations of BLAS will perform several products simultaneously.
The generation of the subgradient \(\varvec{\mathbf {\sigma }}^{(t)}\) was specified earlier as follows:
but can be rewritten using the following vectors \(\varvec{\mathbf {v}}^i \in \{0,1\}^m\), \(i \in \{1,\ldots ,n\}\):
Using SSE registers, we can compute several components of a vector \(\varvec{\mathbf {v}}^i\) simultaneously.
Rights and permissions
About this article
Cite this article
Posta, M., Ferland, J.A. & Michelon, P. An exact cooperative method for the uncapacitated facility location problem. Math. Prog. Comp. 6, 199–231 (2014). https://doi.org/10.1007/s12532-014-0065-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12532-014-0065-z