
Abstract
The emergent machine learning technique—extreme learning machines (ELMs)—has become a hot area of research over the past years, which is attributed to the growing research activities and significant contributions made by numerous researchers around the world. Recently, it has come to our attention that a number of misplaced notions and misunderstandings are being dissipated on the relationships between ELM and some earlier works. This paper wishes to clarify that (1) ELM theories manage to address the open problem which has puzzled the neural networks, machine learning and neuroscience communities for 60 years: whether hidden nodes/neurons need to be tuned in learning, and proved that in contrast to the common knowledge and conventional neural network learning tenets, hidden nodes/neurons do not need to be iteratively tuned in wide types of neural networks and learning models (Fourier series, biological learning, etc.). Unlike ELM theories, none of those earlier works provides theoretical foundations on feedforward neural networks with random hidden nodes; (2) ELM is proposed for both generalized single-hidden-layer feedforward network and multi-hidden-layer feedforward networks (including biological neural networks); (3) homogeneous architecture-based ELM is proposed for feature learning, clustering, regression and (binary/multi-class) classification. (4) Compared to ELM, SVM and LS-SVM tend to provide suboptimal solutions, and SVM and LS-SVM do not consider feature representations in hidden layers of multi-hidden-layer feedforward networks either.








Similar content being viewed by others


Notes
Professional controversies should be advocated in academic and research environments; however, irresponsible anonymous attack which intends to destroy harmony research environment and does not help maintain healthy controversies should be refused.
John von Neumann was also acknowledged as a “Father of Computers.”
Schmidt et al. [1] only reported some experimental results on three synthetic toy data as usually done by many researchers in 1980s–1990s; however, it may be difficult for machine learning community to make concrete conclusions based on experimental results on toy data in most cases.
Chen et al. [51, 52] provide some interesting learning algorithms for RVFL networks and suggested that regularization could be used to avoid overfitting. Their works are different from structural risk minimization and maximum margin concept adopted in SVM. ELM’s regularization objective moves beyond maximum margin concept, and ELM is able to unify neural network generalization theory, structural risk minimization, control theory, matrix theory and linear system theory in ELM learning models (refer to Huang [6, 23] for detail analysis).
Differences between Lowe’s RBF networks and ELM have been clearly given in our earlier reply [3] in response to another earlier comment letter on ELM [63]. It is not clear why several researchers in their anonymous letter refer to the comment letter on ELM [63] for Lowe [35]’s RBF network and RVFL but do not give readers right and clear information by referring to the response [3].
References
Schmidt WF, Kraaijveld MA, Duin RPW. Feed forward neural networks with random weights. In: Proceedings of 11th IAPR international conference on pattern recognition methodology and systems, Hague, Netherlands, p. 1–4, 1992.
Pao Y-H, Park G-H, Sobajic DJ. Learning and generalization characteristics of the random vector functional-link net. Neurocomputing. 1994;6:163–80.
Huang G-B. Reply to comments on ‘the extreme learning machine’. IEEE Trans Neural Netw. 2008;19(8):1495–6.
Huang G-B, Li M-B, Chen L, Siew C-K. Incremental extreme learning machine with fully complex hidden nodes. Neurocomputing. 2008;71:576–83.
Huang G-B, Chen L. Enhanced random search based incremental extreme learning machine. Neurocomputing. 2008;71:3460–8.
Huang G-B. An insight into extreme learning machines: random neurons, random features and kernels. Cogn Comput. 2014;6(3):376–90.
Huang G, Song S, Gupta JND, Wu C. Semi-supervised and unsupervised extreme learning machines. IEEE Trans Cybern. 2014;44(12):2405–17.
Huang G-B, Bai Z, Kasun LLC, Vong CM. Local receptive fields based extreme learning machine. IEEE Comput Intell Mag. 2015;10(2):18–29.
Rosenblatt F. The perceptron: a probabilistic model for information storage and organization in the brain. Psychol Rev. 1958;65(6):386–408.
Rahimi A, Recht B. Random features for large-scale kernel machines. In: Proceedings of the 2007 neural information processing systems (NIPS2007), p. 1177–1184, 3–6 Dec 2007.
Le Q, Sarlós T, Smola A. Fastfood approximating kernel expansions in loglinear time. In: Proceedings of the 30th international conference on machine learning, Atlanta, USA, p. 16–21, June 2013.
Huang P-S, Deng L, Hasegawa-Johnson M, He X. Random features for kernel deep convex network. In: Proceedings of the 38th international conference on acoustics, speech, and signal processing (ICASSP 2013), Vancouver, Canada, p. 26–31, May 2013.
Widrow B, Greenblatt A, Kim Y, Park D. The no-prop algorithm: a new learning algorithm for multilayer neural networks. Neural Netw. 2013;37:182–8.
Bartlett PL. The sample complexity of pattern classification with neural networks: the size of the weights is more important than the size of the network. IEEE Trans Inform Theory. 1998;44(2):525–36.
Cortes C, Vapnik V. Support vector networks. Mach Learn. 1995;20(3):273–97.
Suykens JAK, Vandewalle J. Least squares support vector machine classifiers. Neural Process Lett. 1999;9(3):293–300.
Minsky M, Papert S. Perceptrons: an introduction to computational geometry. Cambridge: MIT Press; 1969.
Huang G-B. Learning capability of neural networks. Ph.D. thesis, Nanyang Technological University, Singapore, 1998.
von Neumann J. Probabilistic logics and the synthesis of reliable organisms from unreliable components. In: Shannon CE, McCarthy J, editors. Automata studies. Princeton: Princeton University Press; 1956. p. 43–98.
von Neumann J. The general and logical theory of automata. In: Jeffress LA, editor. Cerebral mechanisms in behavior. New York: Wiley; 1951. p. 1–41.
Park J, Sandberg IW. Universal approximation using radial-basis-function networks. Neural Comput. 1991;3:246–57.
Leshno M, Lin VY, Pinkus A, Schocken S. Multilayer feedforward networks with a nonpolynomial activation function can approximate any function. Neural Netw. 1993;6:861–7.
Huang G-B, Zhou H, Ding X, Zhang R. Extreme learning machine for regression and multiclass classification. IEEE Trans Syst Man Cybern B. 2012;42(2):513–29.
Huang G-B, Zhu Q-Y, Siew C-K. Extreme learning machine: a new learning scheme of feedforward neural networks. In: Proceedings of international joint conference on neural networks (IJCNN2004), vol. 2, Budapest, Hungary, p. 985–990, 25–29 July 2004.
Huang G-B, Chen L, Siew C-K. Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Trans Neural Netw. 2006;17(4):879–92.
Huang G-B, Chen L. Convex incremental extreme learning machine. Neurocomputing. 2007;70:3056–62.
Sosulski DL, Bloom ML, Cutforth T, Axel R, Datta SR. Distinct representations of olfactory information in different cortical centres. Nature. 2011;472:213–6.
Eliasmith C, Stewart TC, Choo X, Bekolay T, DeWolf T, Tang Y, Rasmussen D. A large-scale model of the functioning brain. Science. 2012;338:1202–5.
Barak O, Rigotti M, Fusi S. The sparseness of mixed selectivity neurons controls the generalization–discrimination trade-off. J Neurosci. 2013;33(9):3844–56.
Rigotti M, Barak O, Warden MR, Wang X-J, Daw ND, Miller EK, Fusi S. The importance of mixed selectivity in complex cognitive tasks. Nature. 2013;497:585–90.
Baum E. On the capabilities of multilayer perceptrons. J Complex. 1988;4:193–215.
Igelnik B, Pao Y-H. Stochastic choice of basis functions in adaptive function approximation and the functional-link net. IEEE Trans Neural Netw. 1995;6(6):1320–9.
Tamura S, Tateishi M. Capabilities of a four-layered feedforward neural network: four layers versus three. IEEE Trans Neural Netw. 1997;8(2):251–5.
Principle J, Chen B. Universal approximation with convex optimization: gimmick or reality? IEEE Comput Intell Mag. 2015;10(2):68–77.
Lowe D. Adaptive radial basis function nonlinearities and the problem of generalisation. In: Proceedings of first IEE international conference on artificial neural networks, p. 171–175, 1989.
Huang G-B, Zhu Q-Y, Mao KZ, Siew C-K, Saratchandran P, Sundararajan N. Can threshold networks be trained directly? IEEE Trans Circuits Syst II. 2006;53(3):187–91.
Li M-B, Huang G-B, Saratchandran P, Sundararajan N. Fully complex extreme learning machine. Neurocomputing. 2005;68:306–14.
Tang J, Deng C, Huang G-B. Extreme learning machine for multilayer perceptron. IEEE Trans Neural Netw Learn Syst. 2015;. doi:10.1109/TNNLS.2015.2424995.
Kasun LLC, Zhou H, Huang G-B, Vong CM. Representational learning with extreme learning machine for big data. IEEE Intell Syst. 2013;28(6):31–4.
Jarrett K, Kavukcuoglu K, Ranzato M, LeCun Y. What is the best multi-stage architecture for object recognition. In: Proceedings of the 2009 IEEE 12th international conference on computer vision, Kyoto, Japan, 29 Sept–2 Oct 2009.
Saxe AM, Koh PW, Chen Z, Bhand M, Suresh B, Ng AY. On random weights and unsupervised feature learning. In: Proceedings of the 28th international conference on machine learning, Bellevue, USA, 28 June–2 July 2011.
Cox D, Pinto N. Beyond simple features: a large-scale feature search approach to unconstrained face recognition. In: IEEE international conference on automatic face and gesture recognition and workshops. IEEE, p. 8–15, 2011.
McDonnell MD, Vladusich T. Enhanced image classification with a fast-learning shallow convolutional neural network. In: Proceedings of international joint conference on neural networks (IJCNN’2015), Killarney, Ireland, 12–17 July 2015.
Zeng Y, Xu X, Fang Y, Zhao K. Traffic sign recognition using extreme learning classifier with deep convolutional features. In: The 2015 international conference on intelligence science and big data engineering (IScIDE 2015), Suzhou, China, June 14–16, 2015.
Suykens JAK, Gestel TV, Brabanter JD, Moor BD, Vandewalle J. Least squares support vector machines. Singapore: World Scientific; 2002.
Rahimi A, Recht B. Uniform approximation of functions with random bases. In: Proceedings of the 2008 46th annual allerton conference on communication, control, and computing, p. 555–561, 23–26 Sept 2008
Daubechies I. Orthonormal bases of compactly supported wavelets. Commun Pure Appl Math. 1988;41:909–96.
Daubechies I. The wavelet transform, time-frequency localization and signal analysis. IEEE Trans Inform Theory. 1990;36(5):961–1005.
Miche Y, Sorjamaa A, Bas P, Simula O, Jutten C, Lendasse A. OP-ELM: optimally pruned extreme learning machine. IEEE Trans Neural Netw. 2010;21(1):158–62.
Kim T, Adali T. Approximation by fully complex multilayer perceptrons. Neural Comput. 2003;15:1641–66.
Chen CLP. A rapid supervised learning neural network for function interpolation and approximation. IEEE Trans Neural Netw. 1996;7(5):1220–30.
Chen CLP, Wan JZ. A rapid learning and dynamic stepwise updating algorithm for flat neural networks and the applications to time-series prediction. IEEE Trans Syst Man Cybern B Cybern. 1999;29(1):62–72.
Huang G-B, Zhu Q-Y, Siew C-K. Extreme learning machine: theory and applications. Neurocomputing. 2006;70:489–501.
White H. An additional hidden unit test for neglected nonlinearity in multilayer feedforward networks. In: Proceedings of the international conference on neural networks, p. 451–455, 1989.
Poggio T, Mukherjee S, Rifkin R, Rakhlin A, Verri A. “\(b\)”, A.I. Memo No. 2001–011, CBCL Memo 198, Artificial Intelligence Laboratory, Massachusetts Institute of Technology, 2001.
Steinwart I, Hush D, Scovel C. Training SVMs without offset. J Mach Learn Res. 2011;12(1):141–202.
Luo J, Vong C-M, Wong P-K. Sparse bayesian extreme learning machine for multi-classification. IEEE Trans Neural Netw Learn Syst. 2014;25(4):836–43.
Decherchi S, Gastaldo P, Leoncini A, Zunino R. Efficient digital implementation of extreme learning machines for classification. IEEE Trans Circuits Syst II. 2012;59(8):496–500.
Bai Z, Huang G-B, Wang D, Wang H, Westover MB. Sparse extreme learning machine for classification. IEEE Trans Cybern. 2014;44(10):1858–70.
Frénay B, van Heeswijk M, Miche Y, Verleysen M, Lendasse A. Feature selection for nonlinear models with extreme learning machines. Neurocomputing. 2013;102:111–24.
Broomhead DS, Lowe D. Multivariable functional interpolation and adaptive networks. Complex Syst. 1988;2:321–55.
Ferrari S, Stengel RF. Smooth function approximation using neural networks. IEEE Trans Neural Netw. 2005;16(1):24–38.
Wang LP, Wan CR. Comments on ‘the extreme learning machine’. IEEE Trans Neural Netw. 2008;19(8):1494–5.
Chen S, Cowan CFN, Grant PM. Orthogonal least squares learning algorithm for radial basis function networks. IEEE Trans Neural Netw. 1991;2(2):302–9.
Acknowledgments
Minsky and Rosenblatt’s controversy may have indirectly inspired the reviving of artificial neural network research in 1980s. Their controversy turned out to show that hidden neurons are critical. Although the main stream of research has focused learning algorithms on tuning hidden neurons since 1980s, few pioneers independently studied alternative solutions (e.g., Halbert White for QuickNet, Yao-Han Pao, Boris Igelnik, and C. L. Philip Chen for RVFL, D. S. Broomhead and David Lowe for RBF networks, Corinna Cortes and Vladimir Vapnik for SVM, J. A. K. Suykens and J. Vandewalle for LS-SVM, E. Baum, Wouter F. Schmidt, Martin A. Kraaijveld and Robert P. W. Duin for Random Weights Sigmoid Network) in 1980s–1990s. Although few of those attempts did not take off finally due to various reasons and constrains, they have been playing significant and irreplaceable roles in the relevant research history. We would appreciate their historical contributions. As discussed in Huang [6], without BP and SVM/LS-SVM, the research and applications on neural networks would never have been so intensive and extensive. We would like to thank Bernard Widrow, Stanford University, USA, for sharing his vision in neural networks and precious historical experiences with us in the past years. It is always pleasant to discuss with him on biological learning, neuroscience and Rosenblatt’s work. We both feel confident that we have never been so close to natural biological learning. We would like to thank C. L. Philip Chen, University of Macau, China and Boris Igelnik, BMI Research, Inc., USA, for invaluable discussions on RVFL, Johan Suykens, Katholieke Universiteit Leuven, Belgium, for invaluable discussions on LS-SVM and Stefano Fusi, Columbia University, USA, for the discussion on the links between biological learning and ELM, and Wouter F. Schmidt and Robert P. W. Duin for the kind constructive feedback on the discussions between ELM and their 1992 work. We would also like to thank Jose Principe, University of Florida, USA, for nice discussions on neuroscience (especially on neuron layers/slices) and his invaluable suggestions on potential mathematical problems of ELM and M. Brandon Westover, Harvard Medical School, USA, for the constructive comments and suggestions on the potential links between ELM and biological learning in local receptive fields.
Author information
Authors and Affiliations
Corresponding author
Appendix: Further Clarification of Misunderstandings on the Relationship Between ELM and Some Earlier Works
Appendix: Further Clarification of Misunderstandings on the Relationship Between ELM and Some Earlier Works
Recently, it has drawn our attention that several researchers have been making some very negative and unhelpful comments on ELM in neither academic nor professional manner due to various reasons and intentions, which mainly state that ELM does not refer to some earlier works (e.g., Schmidt et al. [1] and RVFL), and ELM is the same as those earlier works. It should be pointed out that these earlier works have actually been referred in our different publications on ELM as early as in 2007. It is worth mentioning that ELM actually provides a unifying learning platform for wide types of neural networks and machine learning techniques by absorbing the common advantages of many seemingly isolated different research efforts made in the past 60 years, and thus, it may not be surprising to see apparent relationships between ELM and different techniques. As analyzed in this paper, the essential differences between ELM and those mentioned related works are subtle but crucial.
It is not rare to meet some cases in which intuitively speaking some techniques superficially seem similar to each other, but actually they are significantly different. ELM theories provide a unifying platform for wide types of neural networks, Fourier series [25], wavelets [47, 48], mathematical series [5, 25, 26], etc. Although the relationship and differences between ELM and those earlier works have clearly been discussed in the main context of this paper, in response to the anonymous malign letter, some more background and discussions need to be highlighted in this appendix further.
Misunderstanding on References
Several researchers thought that ELM community has not referred to those earlier related work, e.g., Schmidt et al. [1], RVFL [2] and Broomhead and Lowe [61]. We wish to draw their serious attention that our earlier work (2008) [4] has explicitly stated: “Several researchers, e.g., Baum [31], Igelnik and Pao [32], Lowe [35], Broomhead and Lowe [61], Ferrari and Stengel [62], have independently found that the input weights or centers \({\mathbf{a}}_i\) do not need to be tuned” (these works were published in different years, one did not refer to the others. The study by Ferrari and Stengel [62] has been kindly referred in our work although it was even published later than ELM [24]). In addition, in contrast to the misunderstanding that those earlier works were not referred, we have even referred to Baum [31]’s work and White’s QuickNet [54] in our 2008 works [4, 5], which we consider much earlier than Schmidt et al. [1] and RVFL [2] in the related research areas. There is also a misunderstanding that Park and Sandberg’s RBF theory [21] has not been referred in ELM work. In fact, Park and Sandberg’s RBF theory has been referred in the proof of ELM’s theories on RBF cases as early as 2006 [25].
Although we did not know Schmidt et al. [1] until 2012, we have referred to it in our work [6] immediately. We spent almost 10 years (back to 1996) on proving ELM theories and may have missed some related works. However, from literature survey point of view, Baum [31] may be the earliest related work we could find so far and has been referred at the first time. Although the study by Schmidt et al. [1] is interesting, the citations of Schmidt et al. [1] were almost zero before 2013 (Google Scholar), and it is not easy for his work to turn up in search engine unless one intentionally flips hundreds of search pages. Such information may not be available in earlier generation of search engine when ELM was proposed. The old search engines available in the beginning of this century were not as powerful as most search engines available nowadays and many publications were not online 10–15 years ago. As stated in our earlier work [4], Baum [31] claimed that (seen from simulations) one may fix the weights of the connections on one level and simply adjust the connections on the other level, and no (significant) gain is possible by using an algorithm able to adjust the weights on both levels simultaneously. Surely, almost every researcher knows that the easiest way is to calculate the output weights by least-square method (closed-form) as done in Schmidt et al. [1] and ELM if the input weights are fixed.
Loss of Feature Learning Capability
The earlier works (Schmidt et al. [1], RVFL [2], Broomhead and Lowe [61]) may lose learning capability in some cases.
As analyzed in our earlier work [3, 4], although Lowe [35]’s RBF network chooses RBF network centers randomly, it uses one value \(b\) for all the impact factors in all RBF hidden nodes, and such a network will lose learning capability if the impact factor \(b\) is randomly generated. Thus, in RBF network implementation, the single value of impact factors is usually adjusted manually or based on cross-validation. In this sense, Lower’s RBF network does not use random RBF hidden neurons, let alone wide types of ELM networks.Footnote 7 Furthermore, Chen et al. [64] point out that such Lowe [35, 61]’s RBF learning procedure may not be satisfactory and thus they proposed an alternative learning procedure to choose RBF node centers one by one in a rational way which is also different from random hidden nodes used by ELM.
Schmidt et al. [1] at its original form may face difficulty in sparse data applications; however, one can linearly extend sparse ELM solutions to Schmidt et al. [1] (the resultant solution referred to ELM+\(b\)).
ELM is efficient for auto-encoder as well [39]. However, when RVFL is used for auto-encoder, the weights of the direct link between its input layer to its output layer will become a constant value one and the weights of the links between its hidden layer to its output layer will become a constant value zero; thus, RVFL will lose learning capability in auto-encoder cases. Schmidt et al. [1] which has the biases in output nodes may face difficulty in auto-encoder cases too.
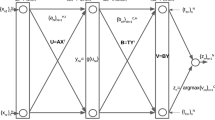
It may be difficult to implement those earlier works (Schmidt et al. [1], RVFL [2], Broomhead and Lowe [61]) in multilayer networks, while hierarchical ELM with multi-ELM each working in one hidden layer can be considered as a single ELM itself. Table 2 summarizes the relationship and main differences between ELM and those earlier works.
Rights and permissions
About this article

Cite this article
Huang, GB. What are Extreme Learning Machines? Filling the Gap Between Frank Rosenblatt’s Dream and John von Neumann’s Puzzle. Cogn Comput 7, 263–278 (2015). https://doi.org/10.1007/s12559-015-9333-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12559-015-9333-0