
Abstract
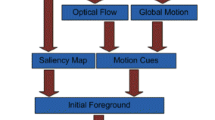
Humans and animals are able to segment visual scenes by having the natural cognitive ability to quickly identify salient objects in both static and dynamic scenes. In this paper, we present a new spatio-temporal-based approach to video object segmentation that considers both motion- and image-based saliency to produce a weighted approach which can segment both static and dynamic objects. We perform fast optical flow and then calculate the motion saliency based on this temporal information, detecting the presence of global motion and adjusting the initial optical flow results accordingly. This is then fused with a region-based contrast image saliency method, with both techniques weighted. Finally, our joint weighted saliency map is used as part of a foreground–background labelling approach to produce the final segmented video files. Good results in a wide range of environments are presented, showing that our spatio-temporal system is more robust and consistent than a number of other state-of-the-art approaches.








Similar content being viewed by others
References
Edelstein A, Rabbat M. Background subtraction for online calibration of baseline rss in rf sensing networks. IEEE Trans Mobile Comput. 2013;12(12):2386–98.
Itti L, Koch C, Niebur E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans Pattern Anal Mach Intell. 1998;11:1254–9.
Papazoglou A, Ferrari V. Fast object segmentation in unconstrained video. In: 2013 IEEE international conference on computer vision (ICCV). IEEE; 2013. p. 1777–1784.
Cheng M, Mitra NJ, Huang X, Torr PHS, Hu S. Global contrast based salient region detection. IEEE Trans Pattern Anal Mach Intell. 2015;37(3):569–82.
Chen L, Shen J, Wang W, Ni B. Video object segmentation via dense trajectories. IEEE Trans Multimed. 2015;17(12):2225–34.
Wang W, Shen J, Porikli F. Saliency-aware geodesic video object segmentation. In: Proceedings of IEEE CVPR; 2015.
Wang W, Shen J, Li X, Porikli F. Robust video object cosegmentation. IEEE Trans Image Process. 2015;24(10):3137–48.
Dong X, Shen J, Shao L, Yang M-H. Interactive cosegmentation using global and local energy optimization. IEEE Trans Image Process. 2015;24(11):3966–77.
Wolfe JM, Horowitz TS. What attributes guide the deployment of visual attention and how do they do it? Nat Rev Neurosci. 2004;5(6):495–501.
Cheng M-M, Warrell J, Lin W-Y, Zheng S, Vineet V, Crook N. Efficient salient region detection with soft image abstraction. In: 2013 IEEE international conference on computer vision (ICCV). IEEE; 2013. p. 1529–1536.
Desimone R, Duncan J. Neural mechanisms of selective visual attention. Annu Rev Neurosci. 1995;18(1):193–222.
Koch C, Ullman S. Shifts in selective visual attention: towards the underlying neural circuitry. In: Matters of intelligence. Springer; 1987. p. 115–141.
Liu T, Yuan Z, Sun J, Wang J, Zheng N, Tang X, Shum H-Y. Learning to detect a salient object. IEEE Trans Pattern Anal Mach Intell. 2011;33(2):353–67.
Yang J, Yang M-H. Top-down visual saliency via joint crf and dictionary learning. In: 2012 IEEE conference on computer vision and pattern recognition (CVPR). IEEE; 2012. p. 2296–2303.
Fang Y, Chen Z, Lin W, Lin C-W. Saliency detection in the compressed domain for adaptive image retargeting. IEEE Trans Image Process. 2012;21(9):3888–901.
Li H, Ngan KN. Saliency model-based face segmentation and tracking in head-and-shoulder video sequencesd. J Vis Commun Image Represent. 2008;19(5):320–33.
Siagian C, Itti L. Biologically inspired mobile robot vision localization. IEEE Trans Robot. 2009;25(4):861–73.
Born RT, Groh JM, Zhao R, Lukasewycz SJ. Segregation of object and background motion in visual area mt: effects of microstimulation on eye movements. Neuron. 2000;26(3):725–34.
Seo HJ, Milanfar P. Static and space–time visual saliency detection by self-resemblance. J Vis. 2009;9(12):15.
Wang W, Shen J, Shao L. Consistent video saliency using local gradient flow optimization and global refinement. IEEE Trans Image Process. 2015;24(11):4185–96.
Tu Z, Zheng A, Yang E, Luo B, Hussain A. A biologically inspired vision-based approach for detecting multiple moving objects in complex outdoor scenes. Cogn Comput. 2015;7:539–51.
Bao L, Yang Q, Jin H. Fast edge-preserving patchmatch for large displacement optical flow. IEEE Trans Image Process. 2014;23(12):4996–5006.
Heikkilä M, Pietikäinen M. A texture-based method for modeling the background and detecting moving objects. IEEE Trans Pattern Anal Mach Intell. 2006;28(4):657–62.
Zivkovic Z. Improved adaptive gaussian mixture model for background subtraction. In: Proceedings of the 17th International conference on pattern recognition, 2004. ICPR 2004, volume 2. IEEE; 2004. p. 28–31.
Barnich O, Van Droogenbroeck M. Vibe: a universal background subtraction algorithm for video sequences. IEEE Trans Image Process. 2011;20(6):1709–24.
Horn BK, Schunck BG. Determining optical flow. In: 1981 Technical symposium east. International Society for Optics and Photonics; 1981. p. 319–331.
Lucas BD, Kanade T, et al. An iterative image registration technique with an application to stereo vision. IJCAI. 1981;81:674–9.
Sun D, Roth S, Black MJ. Secrets of optical flow estimation and their principles. In: 2010 IEEE conference on computer vision and pattern recognition (CVPR). IEEE; 2010. pp. 2432–2439.
Wedel A, Cremers D, Pock T, Bischof H. Structure- and motion-adaptive regularization for high accuracy optic flow. In: 2009 IEEE 12th international conference on computer vision. IEEE; 2009. p. 1663–1668.
Wedel A, Pock T, Zach C, Bischof H, Cremers D. An improved algorithm for tv-l 1 optical flow. In: Statistical and geometrical approaches to visual motion analysis. Springer; 2009. p. 23–45.
Yubing T, Cheikh FA, Guraya FFE, Konik H, Trémeau A. A spatiotemporal saliency model for video surveillance. Cogn Comput. 2011;3(1):241–63.
De Croon GCHE, Postma EO, van den Herik HJ. Adaptive gaze control for object detection. Cogn Comput. 2011;3(1):264–78.
Donoser M, Urschler M, Hirzer M, Bischof H. Saliency driven total variation segmentation. In: 2009 IEEE 12th international conference on computer vision. IEEE; 2009. p. 817–824.
Rutishauser U, Walther D, Koch C, Perona P. Is bottom-up attention useful for object recognition? In: Computer vision and pattern recognition, 2004. CVPR 2004. Proceedings of the 2004 IEEE computer society conference on, volume 2. IEEE; 2004. p. II–37.
Christopoulos C, Skodras A, Ebrahimi T. The jpeg2000 still image coding system: an overview. IEEE Trans Consum Electron. 2000;46(4):1103–27.
Gao Y, Wang M, Zha Z-J, Shen J, Li X, Xindong W. Visual-textual joint relevance learning for tag-based social image search. IEEE Trans Image Process. 2013;22(1):363–76.
Harel J, Koch C, Perona P. Graph-based visual saliency. In: Advances in neural information processing systems; 2006. p. 545–552.
Zhang L, Tong MH, Marks TK, Shan H, Cottrell GW. Sun: a bayesian framework for saliency using natural statistics. J Vis. 2008;8(7):32.
Xie Y, Huchuan L, Yang M-H. Bayesian saliency via low and mid level cues. IEEE Trans Image Process. 2013;22(5):1689–98.
Wei Y, Wen F, Zhu W, Sun J. Geodesic saliency using background priors. In: Computer vision—ECCV 2012. Springer; 2012. p. 29–42.
Shen X, Wu Y. A unified approach to salient object detection via low rank matrix recovery. In: 2012 IEEE conference on computer vision and pattern recognition (CVPR). IEEE; 2012. p. 853–860.
Lang C, Liu G, Jian Y, Yan S. Saliency detection by multitask sparsity pursuit. IEEE Trans Image Process. 2012;21(3):1327–38.
Li W-T, Chang H-S, Lien K-C, Chang H-T, Wang YF. Exploring visual and motion saliency for automatic video object extraction. IEEE Trans Image Process. 2013;22(7):2600–10.
Rother C, Kolmogorov V, Blake A. Grabcut: interactive foreground extraction using iterated graph cuts. ACM Trans Graph (TOG). 2004;23(3):309–14.
Lafferty J, McCallum A, Pereira FCN. Conditional random fields: probabilistic models for segmenting and labeling sequence data; 2001. p. 282–289.
Zhang D, Javed O, Shah M. Video object segmentation through spatially accurate and temporally dense extraction of primary object regions. In: 2013 IEEE conference on computer vision and pattern recognition (CVPR). IEEE; 2013. p. 628–635.
Li C, Lin L, Zuo W, Yan S, Tang J. Sold: sub-optimal low-rank decomposition for efficient video segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition; 2015. p. 5519–5527.
Barnes C, Shechtman E, Finkelstein A, Goldman D. Patchmatch: a randomized correspondence algorithm for structural image editing. ACM Trans Graph (TOG). 2009;28(3):24.
He K, Sun J. Computing nearest-neighbor fields via propagation-assisted kd-trees. In: 2012 IEEE conference on computer vision and pattern recognition (CVPR). IEEE; 2012. p. 111–118.
Scharstein D, Szeliski R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. Int J Comput Vis. 2002;47(1–3):7–42.
Loy CC, Xiang T, Gong S. Salient motion detection in crowded scenes. In: 2012 5th International symposium on communications control and signal processing (ISCCSP). IEEE; 2012. p. 1–4.
Mathe S, Sminchisescu C. Dynamic eye movement datasets and learnt saliency models for visual action recognition. In: Computer vision–ECCV 2012. Springer; 2012. p. 842–856.
Pylyshyn ZW. Visual indexes, preconceptual objects, and situated vision. Cognition. 2001;80(1):127–58.
Scholl BJ. Objects and attention: the state of the art. Cognition. 2001;80(1):1–46.
Dufaux F, Konrad J. Efficient, robust, and fast global motion estimation for video coding. IEEE Trans Image Process. 2000;9(3):497–501.
Felzenszwalb PF, Huttenlocher DP. Efficient graph-based image segmentation. Int J Comput Vis. 2004;59(2):167–81.
Jiang H, Wang J, Yuan Z, Liu T, Zheng N, Li S. Automatic salient object segmentation based on context and shape prior. BMVC. 2011;6:9.
Achanta R, Shaji A, Smith K, Lucchi A, Fua P, Susstrunk S. Slic superpixels compared to state-of-the-art superpixel methods. IEEE Trans Pattern Anal Mach Intell. 2012;34(11):2274–82.
Wang T, Collomosse J. Probabilistic motion diffusion of labeling priors for coherent video segmentation. IEEE Trans Multimed. 2012;14(2):389–400.
Lee YJ, Kim J, Grauman K. Key-segments for video object segmentation. In: 2011 IEEE international conference on computer vision (ICCV). IEEE; 2011. p. 1995–2002.
Fukuchi K, Miyazato K, Kimura A, Takagi S, Yamato J. Saliency-based video segmentation with graph cuts and sequentially updated priors. In: IEEE international conference on multimedia and expo, 2009 (ICME 2009). IEEE; 2009. p. 638–641.
Singh A, Chu C-HH, Pratt M. Learning to predict video saliency using temporal superpixels. In: Pattern Recognition Applications and Methods, 4th International Conference on; 2015.
Prest A, Leistner C, Civera J, Schmid C, Ferrari V. Learning object class detectors from weakly annotated video. In: 2012 IEEE conference on computer vision and pattern recognition (CVPR). IEEE; 2012. p. 3282–3289.
Li F, Kim T, Humayun A, Tsai D, Rehg JM. Video segmentation by tracking many figure-ground segments. In: 2013 IEEE international conference on computer vision (ICCV). IEEE; 2013. p. 2192–2199.
Abel A, Hussain A. Novel two-stage audiovisual speech filtering in noisy environments. Cogn Comput. 2014;6(2):200–17.
Acknowledgments
This work is supported in part by the National High Technology Research and Development Program (863 Program) of China (2014AA015104). This research is also supported by the Natural Science Foundation of Anhui Higher Education Institution of China (KJ2015A110), the “Sino-UK” Higher Education Research Partnership for PhD studies” joint-project (2013–2015) funded by the British Council China and the China Scholarship Council (CSC), the Natural Science Foundation of Anhui Higher Education Institution of China (No. KJ2014A015), and the Natural Science Foundation of China (No. 61472002). This research is also partially supported by the Engineering and Physical Sciences Research Council (No. EP/M026981/1) and a Royal Society of Edinburgh Travel Grant (ABEL/NNS/INT).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
Zhengzheng Tu, Andrew Abel, Lei Zhang, Bin Luo, and Amir Hussain declare that they have no conflict of interest.
Informed Consent
All procedures followed were in accordance with the ethical standards of the responsible committee on human experimentation (institutional and national) and with the Helsinki Declaration of 1975, as revised in 2008 (5). Additional informed consent was obtained from all patients for which identifying information is included in this article.
Human and Animal Rights
This article does not contain any studies with human or animal subjects performed by the any of the authors.
Rights and permissions
About this article

Cite this article
Tu, Z., Abel, A., Zhang, L. et al. A New Spatio-Temporal Saliency-Based Video Object Segmentation. Cogn Comput 8, 629–647 (2016). https://doi.org/10.1007/s12559-016-9387-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12559-016-9387-7