
Abstract
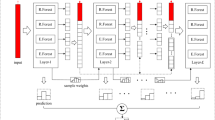
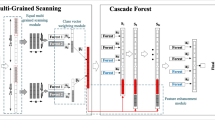
The known deficiencies of deep neural networks include inferior training efficiency, weak parallelization capability, too many hyper-parameters etc. To address these issues, some researchers presented deep forest, a special deep learning model, which achieves some significant improvements but remain poor training efficiency, inflexible model size and weak interpretability. This paper endeavors to solve the issues in a new way. Firstly, deep forest is extended to the densely connected deep forest to enhance the prediction accuracy. Secondly, to perform parallel training with adaptive model size, the flat random forest is proposed by achieving the balance between the width and depth of densely connected deep forest. Finally, two core algorithms are respectively presented for the forward output weights computation and output weights updating. The experimental results show, compared with deep forest, the proposed flat random forest acquires competitive prediction accuracy, higher training efficiency, less hyper-parameters and adaptive model size.















Similar content being viewed by others

References
Dimitriadou E, Weingessel A, Hornik K (2001) Voting-merging: an ensemble method for clustering. In: International conference on artificial neural networks, pp 217–244
Breiman L (1996) Bagging predictors. Mach Learn 24(2):123–140
Schapire RE (1999) A brief introduction to boosting. In: Sixteenth international joint conference on artificial intelligence, pp 1401–1406
Chen T, Guestrin C (2016) XGBoost: a scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pp 785–794
Friedman JH, Popescu BE (2008) Predictive learning via rule ensembles. Ann Appl Stat 2(3):916–954
Breiman L (2001) Random forests. Mach Learn 45(1):5–32
Zhou ZH, Feng J (2017) Deep forest: towards an alternative to deep neural networks. arXiv:1702.08835
Huang G, Liu Z, Laurens VDM, Weinberger KQ (2017) Densely connected convolutional networks. In Proceedings of the 2017 IEEE conference on computer vision and pattern recognition (CVPR), vol 1(no. 2), p 3
Chen CLP, Wan JZ (1999) A rapid learning and dynamic stepwise updating algorithm for flat neural networks and the application to time-series prediction. IEEE Trans Syst Man Cybern B Cybern 29(1):62–72
Chan TH, Jia K, Gao S, Lu J, Zeng Z, Ma Y (2014) PCANet: a simple deep learning baseline for image classification. IEEE Trans Image Process 24(12):5017–5032
Chen CLP, Liu Z (2018) Broad learning system: an effective and efficient incremental learning system without the need for deep architecture. IEEE Trans Neural Netw Learn Syst 29(1):10–24
Payne DB, Stern JR (1985) Wavelength-switched passively coupled single-mode optical network. In: Proceedings of the IOOC–ECOC, vol 85, p 585
Jacobs RA, Jordan MI, Nowlan SJ, Hinton GE (1991) Adaptive mixtures of local experts. Neural Comput 3(1):79–87
Hoeting JA, Madigan D, Volinsky RCT (1999) Bayesian model averaging: a tutorial. Stat Sci 14(4):382–401
Bagui SC (2005) Combining pattern classifiers: methods and algorithms. Technometrics 47(4):517–518
Bauer E, Kohavi R (1999) An empirical comparison of voting classification algorithms: bagging, boosting, and variants. Mach Learn 36(1–2):105–139
Mallapragada PK, Jin R, Jain AK, Liu Y, Mallapragada PK, Jin R et al (2009) Semiboost: boosting for semi-supervised learning. IEEE Trans Pattern Anal Mach Intell 31(11):2000–2014
Bennett KP, Demiriz A, Maclin R (2002) Exploiting unlabeled data in ensemble methods. In: Proceedings of the eighth ACM SIGKDD international conference on knowledge discovery and data mining, pp 289–296
Zhou ZH, Li M (2005) Tri-training: exploiting unlabeled data using three classifiers. IEEE Trans Knowl Data Eng 17(11):1529–1541
Yoon J, Zame WR, Mihaela VDS (2018) ToPs: ensemble learning with trees of predictors. IEEE Trans Signal Process 66(8):2141–2152
Wu Q, Ye Y, Zhang H et al (2014) ForesTexter: an efficient random forest algorithm for imbalanced text categorization. Knowl Based Syst 67:105–116
Amiri S, Mahjoub MA, Rekik I (2018) Dynamic multiscale tree learning using ensemble strong classifiers for multi-label segmentation of medical images with lesions. In: Proceedings of the 13th international joint conference on computer vision, imaging and computer graphics theory and applications, vol 4, pp 419–426
Chakraborty T (2017) [IEEE 2017 IEEE international conference on data mining (ICDM)—New Orleans, LA (2017.11.18-2017.11.21)] 2017 IEEE international conference on data mining (ICDM)—EC3: combining clustering and classification for ensemble learning, pp 781–786
Strauss T, Hanselmann M, Junginger A et al (2017) Ensemble methods as a defense to adversarial perturbations against deep neural networks. arXiv:1709.03423
Zhou ZH (2012) Ensemble methods: foundations and algorithms. Chapman and Hall/CRC, London
Hinton GE, Osindero S, Teh YW (2014) A fast learning algorithm for deep belief nets. Neural Comput 18(7):1527–1554
Wang Y, Xia ST, Tang Q et al (2018) A novel consistent random forest framework: Bernoulli random forests. IEEE Trans Neural Netw Learn Syst 29(8):3510–3523
Samaria FS, Harter AC (1994) Parameterization of a stochastic model for human face identification. IEEE Workshop Appl Comput Vis 22:138–142
Asuncion A, Newman D (2007) UCI machine learning repository. University of California, School of Information and Computer Science, Irvine
Acknowledgements
This work was supported by the Fundamental Research Funds for the Central Universities (2017XKQY082). The authors would like to thank the anonymous reviewers and the associate editor for their valuable comments.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Liu, P., Wang, X., Yin, L. et al. Flat random forest: a new ensemble learning method towards better training efficiency and adaptive model size to deep forest. Int. J. Mach. Learn. & Cyber. 11, 2501–2513 (2020). https://doi.org/10.1007/s13042-020-01136-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-020-01136-0