
Abstract
In recent years, action recognition has become a popular and challenging task in computer vision. Nowadays, two-stream networks with appearance stream and motion stream can make judgment jointly and get excellent action classification results. But many of these networks fused the features or scores simply, and the characteristics in different streams were not utilized effectively. Meanwhile, the spatial context and temporal information were not fully utilized and processed in some networks. In this paper, a novel three-stream network spatiotemporal attention enhanced features fusion network for action recognition is proposed. Firstly, features fusion stream which includes multi-level features fusion blocks, is designed to train the two streams jointly and complement the two-stream network. Secondly, we model the channel features obtained by spatial context to enhance the ability to extract useful spatial semantic features at different levels. Thirdly, a temporal attention module which can model the temporal information makes the extracted temporal features more representative. A large number of experiments are performed on UCF101 dataset and HMDB51 dataset, which verify the effectiveness of our proposed network for action recognition.










Similar content being viewed by others
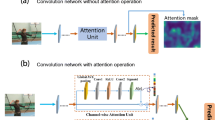
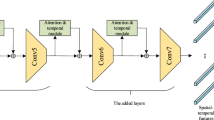
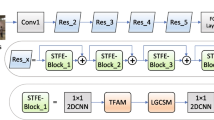
References
Dollár P, Rabaud V, Cottrell G, Belongie S (2005) Behavior recognition via sparse spatio-temporal features. In: 2005 IEEE international workshop on visual surveillance and performance evaluation of tracking and surveillance. IEEE, pp 65–72
Laptev I, Marszalek M, Schmid C, Rozenfeld B (2008) Learning realistic human actions from movies. In: 2008 IEEE conference on computer vision and pattern recognition. IEEE, pp 1–8
Willems G, Tuytelaars T, Van Gool L (2008) An efficient dense and scale-invariant spatio-temporal interest point detector. In: European conference on computer vision. Springer, pp 650–663
Wang H, Kläser A, Schmid C, Liu CL (2011) Action recognition by dense trajectories. In: 2011 IEEE conference on computer vision and pattern recognition. IEEE, pp 3169–3176
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. In: Advances in neural information processing systems. pp 1097–1105
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556
Howard AG, Zhu M, Chen B, Kalenichenko D, Wang W, Weyand T, Andreetto M, Adam H (2017) Mobilenets: efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861
Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. In: Advances in neural information processing systems. pp 568–576
Feichtenhofer C, Pinz A, Zisserman A (2016) Convolutional two-stream network fusion for video action recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 1933–1941
Wang L, Xiong Y, Wang Z, Qiao Y, Lin D, Tang X, Van Gool L (2016) Temporal segment networks: towards good practices for deep action recognition. In: European conference on computer vision. Springer, pp 20–36
Hu J, Shen L, Sun G (2018) Squeeze-and-excitation networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 7132–7141
Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A (2015) Going deeper with convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 1–9
Mikolov T, Kombrink S, Burget L, Černocky J, Khudanpur S (2011) Extensions of recurrent neural network language model. In: 2011 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, pp 5528–5531
Luo J, Wu J, Zhao S, Wang L, Xu T (2019) Lossless compression for hyperspectral image using deep recurrent neural networks. Int J Mach Learn Cybern 1–11
Zhou T, Li Z, Zhang C (2019) Enhance the recognition ability to occlusions and small objects with robust faster r-cnn. Int J Mach Learn Cybern 10(11):3155–3166
Donahue J, Hendricks LA, Guadarrama S,Rohrbach M, Venugopalan S, Saenko K, Darrell T (2015) Long-term recurrent convolutional networks for visual recognition and description. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 2625–2634
Feichtenhofer C, Pinz A, Wildes R (2016) Spatiotemporal residual networks for video action recognition. In: Advances in neural information processing systems. pp 3468–3476
Feichtenhofer C, Pinz A, Wildes RP (2017) Spatiotemporal multiplier networks for video action recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 4768–4777
Tran D, Bourdev L, Fergus R, Torresani L, Paluri M (2015) Learning spatiotemporal features with 3d convolutional networks. In: Proceedings of the IEEE international conference on computer vision. pp 4489–4497
Carreira J, Zisserman A (2017) Quo vadis, action recognition? A new model and the kinetics dataset. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 6299–6308
Qiu Z, Yao T, Mei T (2017) Learning spatio-temporal representation with pseudo-3d residual networks. In: Proceedings of the IEEE international conference on computer vision. pp 5533–5541
Tran D, Wang H, Torresani L, Ray J, LeCun Y, Paluri M (2018) A closer look at spatiotemporal convolutions for action recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 6450–6459
Zhongxu H, Youmin H, Liu J, Bo W, Han D, Kurfess T (2018) 3d separable convolutional neural network for dynamic hand gesture recognition. Neurocomputing 318:151–161
Wang F, Jiang M, Qian C, Yang S, Li C, Zhang H, Wang X, Tang X (2017) Residual attention network for image classification. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3156–3164
Hu J, Shen L, Albanie S, Sun G, Vedaldi A (2018) Gather-excite: exploiting feature context in convolutional neural networks. In: Advances in neural information processing systems. pp 9401–9411
Zhao H, Zhang Y, Liu S, Shi J, Loy CC, Lin D, Jia J (2018) Psanet: point-wise spatial attention network for scene parsing. In: Proceedings of the European conference on computer vision (ECCV). pp 267–283
Woo S, Park J, Lee J-Y, Kweon IS (2018) Cbam: convolutional block attention module. In: Proceedings of the European conference on computer vision (ECCV). pp 3–19
Wang X, Girshick R, Gupta A, He K (2018) Non-local neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 7794–7803
Fu J, Liu J, Tian H, Li Y, Bao Y, Fang Z, Lu H (2019) Dual attention network for scene segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 3146–3154
Li X, Wang W, Hu X, Yang J (2019) Selective kernel networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 510–519
Li X, Hu X, Yang J (2019) Spatial group-wise enhance: improving semantic feature learning in arXiv preprint arXiv:1905.0964
Zhou P, Shi W, Tian J, Qi Z, Li B, Hao H, Xu B (2016) Attention-based bidirectional long short-term memory networks for relation classification. In: Proceedings of the 54th annual meeting of the association for computational linguistics (vol 2: short papers). pp 207–212
Cao Y, Xu J, Lin S, Wei F, Hu H (2019) Gcnet: non-local networks meet squeeze-excitation networks and beyond. arXiv preprint arXiv:1904.11492
Bai S, Kolter JZ, Koltun V (2018) An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv preprint arXiv:1803.01271
Bottou L (2010) Large-scale machine learning with stochastic gradient descent. In: Proceedings of COMPSTAT’2010. Springer, pp 177–186
Paszke A, Gross S, Chintala S, Chanan G, Yang E, DeVito Z, Lin Z, Antiga L, Lerer A (2017) Automatic differentiation in pytorch, Alban Desmaison
Fan L, Huang W, Gan C, Ermon S, Gong B, Huang J (2018) End-to-end learning of motion representation for video understanding. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 6016–6025
Tran D, Ray J, Shou Z, S-F Chang, Paluri M (2017) Convnet architecture search for spatiotemporal feature learning. arXiv preprint arXiv:1708.05038
Liu Q, Che X, Bie M (2019) R-stan: residual spatial-temporal attention network for action recognition. IEEE Access 7:82246–82255
Wang H, Schmid C (2013) Action recognition with improved trajectories. In: Proceedings of the IEEE international conference on computer vision. pp 3551–3558
Peng X, Wang L, Wang X, Qiao Yu (2016) Bag of visual words and fusion methods for action recognition: comprehensive study and good practice. Comput Vis Image Underst 150:109–125
Lan Z, Lin M, Li X, Hauptmann AG, Raj B (2015) Beyond gaussian pyramid: multi-skip feature stacking for action recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 204–212
Ng JY-H, Hausknecht M, Vijayanarasimhan S, Vinyals O, Monga R, Toderici G (2015) Beyond short snippets: deep networks for video classification. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 4694–4702
Wang L, Qiao Y, Tang X (2015) Action recognition with trajectory-pooled deep-convolutional descriptors. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 4305–4314
Wang Y, Long M, Wang J, Yu PS (2017) Spatiotemporal pyramid network for video action recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 1529–1538
Lin W, Mi Y, Wu J, Lu K, Xiong H (2017) Action recognition with coarse-to-fine deep feature integration and asynchronous fusion. arXiv preprint arXiv:171107430
Zhu Y, Lan Z, Newsam S, Hauptmann A (2018) Hidden two-stream convolutional networks for action recognition. In: Asian conference on computer vision. Springer, pp 363–378
Liu Z, Hu H (2019) Spatiotemporal relation networks for video action recognition. IEEE Access 7:14969–14976
Huang W, Fan L, Harandi M, Ma L, Liu H, Liu W, Gan C (2018) Toward efficient action recognition: principal backpropagation for training two-stream networks. IEEE Trans Image Process 28(4):1773–1782
Song S, Liu J, Li Y, Guo Z (2020) Modality compensation network: Cross-modal adaptation for action recognition. IEEE Trans Image Process 29:3957–3969
Li C, Zhang B, Chen C, Ye Q, Han J, Guo G, Ji R (2019) Deep manifold structure transfer for action recognition. IEEE Trans Image Process 28(9):4646–4658
Zhu W, Hu J, Sun G, Cao X, Qiao Y (2016) A key volume mining deep framework for action recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 1991–1999
Kar A, Rai N, Sikka K, Sharma G (2017) Adascan: adaptive scan aooling in deep convolutional neural networks for human action recognition in videos. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 3376–3385
Liu Z, Wang L, Zheng N (2018) Content-aware attention network for action recognition. In: IFIP international conference on artificial intelligence applications and innovations. Springer, pp 109–120
Peng Y, Zhao Y, Zhang J (2018) Two-stream collaborative learning with spatial-temporal attention for video classification. IEEE Trans Circuits Syst Video Technol 29(3):773–786
Tran A, Cheong L-F (2017) Two-stream flow-guided convolutional attention networks for action recognition. In: Proceedings of the IEEE international conference on computer vision. pp 3110–3119
Peng Y, Zhao Y, Zhang J (2019) Two-stream collaborative learning with spatial-temporal attention for video classification. IEEE Transactions on Circuits and Systems for Video Technology 29(3):773–786
Li D, Yao T, Duan L, Mei T, Rui Y (2019) Unified spatio-temporal attention networks for action recognition in videos. IEEE Transactions on Multimedia 21(2):416–428
Xue F, Ji H, Zhang W, Cao Y (2019) Attention-based spatial-temporal hierarchical convlstm network for action recognition in videos. IET Computer Vision 13(8):708–718
Liu S, Ma X, Wu H, Li Y (2020) An end to end framework with adaptive spatio-temporal attention module for human action recognition. IEEE Access 8:47220–47231
Luo G, Wei J, Hu W, Maybank SJ (2019) Tangent fisher vector on matrix manifolds for action recognition. IEEE Trans Image Process 29:3052–3064
Rahimi S, Aghagolzadeh A, Ezoji M (2020) Human action recognition using double discriminative sparsity preserving projections and discriminant ridge-based classifier based on the gdwl-l1 graph. Expert Syst Appl 141:112927
Wang X, Farhadi A, Gupta A (2016) Actions transformations. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 2658–2667
Varol G, Laptev I, Schmid C (2017) Long-term temporal convolutions for action recognition. IEEE Trans Pattern Anal Mach Intell 40(6):1510–1517
Shou Z, Lin X, Kalantidis Y, Sevillalara L, Rohrbach M, Chang S, Yan Z (2019) Dmc-net: generating discriminative motion cues for fast compressed video action recognition. pp 1268–1277
Huang S, Lin X, Karaman S, Chang SF (2019) Flow-distilled ip two-stream networks for compressed video action recognition. arXiv preprint arXiv:191204462
Khowaja SA, Lee SL (2020) Semantic image networks for human action recognition. Int J Comput Vis 128(2):393–419
Battash B, Barad H, Tang H, Bleiweiss A (2020) Mimic the raw domain: Accelerating action recognition in the compressed domain. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. pp 684–685
Alwassel H, Mahajan D, Torresani L, Ghanem B, Tran D (2019) Self-supervised learning by cross-modal audio-video clustering. arXiv preprint arXiv:191112667
Acknowledgements
This work was partially supported by the National Natural Science Foundation of China (61362030, 61201429), China Postdoctoral Science Foundation (2015M581720, 2016M600360), Jiangsu Postdoctoral Science Foundation (1601216C), Scientific and Technological Aid Program of Xinjiang (2017E0279), 111 Projects under Grant B12018.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zhuang, D., Jiang, M., Kong, J. et al. Spatiotemporal attention enhanced features fusion network for action recognition. Int. J. Mach. Learn. & Cyber. 12, 823–841 (2021). https://doi.org/10.1007/s13042-020-01204-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-020-01204-5