
Abstract
Support vector machine (SVM), a state-of-the-art classifier for supervised classification task, is famous for its strong generalization guarantees derived from the max-margin property. In this paper, we focus on the maximum margin classification problem cast by SVM and study the bi-regular hinge loss model, which not only performs feature selection but tends to select highly correlated features together. To solve this model, we propose an online learning algorithm that aims at solving a non-smooth minimization problem by alternating iterative mechanism. Basically, the proposed algorithm alternates between intrusion samples detection and iterative optimization, and at each iteration it obtains a closed-form solution to the model. In theory, we prove that the proposed algorithm achieves \(O(1/\sqrt{T})\) convergence rate under some mild conditions, where T is the number of training samples received in online learning. Experimental results on synthetic data and benchmark datasets demonstrate the effectiveness and performance of our approach in comparison with several popular algorithms, such as LIBSVM, SGD, PEGASOS, SVRG, etc.














Similar content being viewed by others


Notes
A problem is said to be NP-hard if the solution is required to be over the integers [16].
The learner in an online learning model needs to make predictions about a sequence of samples, one after the other, and then receives a loss after each prediction. The goal is to minimize the accumulated losses [30, 31]. The first explicit models of online learning were proposed by Angluin [2] and Littlestone [28].
CVX is a free Matlab software for disciplined convex programming, which can be downloaded from http://cvxr.com/cvx.
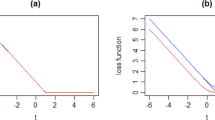
The objective function values here include the hinge loss and the bi-regular term.
References
Akbari M, Gharesifard B, Linder T (2019) Individual regret bounds for the distributed online alternating direction method of multipliers. IEEE Trans Autom Control 64(4):1746–1752
Angluin D (1988) Queries and concept learning. Mach Learn 2:319–342
Barzilai J, Borwein JM (1988) Two-point step size gradient methods. IMA J Numer Anal 8:141–148
Boyd S, Parikh N, Chu E, Peleato B, Eckstein J (2010) Distributed optimization and statistical learning via the alternating direction method of multipliers. Found Trends Mach Learn 3(1):1–122
Buhlmann P, van de Geer S (2011) Statistics for High-dimensional Data: Methods, Theory and Applications. Springer, Berlin
Candès EJ, Wakin MB, Boyd SP (2008) Enhancing sparsity by reweighted \(l_1\) minimization. J Fourier Anal Appl 14(5):877–905
Chang KW, Hsieh CJ, Lin CJ (2008) Coordinate descent method for large-scale l2-loss linear support vector machines. J Mach Learn Res 9:1369–1398
Chang CC, Lin CJ (2011) LIBSVM: a library for support vector machines. ACM Trans Intell Syst Technol 2(3):27:1–27:27
Chauhan VK, Dahiya K, Sharma A (2019) Problem formulations and solvers in linear SVM: a review. Artif Intell Rev 52:803–855
Chauhan VK, Sharma A, Dahiya K (2020) Stochastic trust region inexact Newton method for large-scale machine learning. Int J Mach Learn and Cybern 11:1541–1555
Cohen K, Nedić A, Srikant R (2017) On projected stochastic gradient descent algorithm with weighted averaging for least squares regression. IEEE Trans Autom Control 62(11):5974–5981
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20(3):273–297
De Mol C, De Vito E, Rosasco L (2009) Elastic-net regularization in learning theory. J Complex 25(2):201–230
Duchi JC, Shalev-Shwartz S, Singer Y, Tewari A (2010) Composite Objective Mirror Descent. In: Proceedings of the 23rd annual conference on learning theory, pp 14–26
Gabay D, Mercier B (1976) A dual algorithm for the solution of nonlinear variational problems via finite element approximation. Comput Optim Appl 2(1):17–40
Garey MR, Johnson DS (1979) Computers and intractability: a guide to the theory of NP-completeness. Freeman, New York
Glowinski R, Marrocco A (1975) Sur l’approximation, paréléments finis d’ordre un, et lan résolution, par pénalisation-dualité, d’une classe de problémes de Dirichlet non linéaires. Rev Fr Automat Infor 9:41–76
Gong Y, Xu W (2007) Machine learning for multimedia content analysis. Springer Science & Business Media, New York
Hajewski J, Oliveira S, Stewart D (2018) Smoothed hinge loss and l1 support vector machines. In: Proceedings of the 2018 IEEE international conference on data mining workshops, pp 1217–1223
He B, Yuan X (2012) On the \(O(1/n)\) convergence rate of the Douglas-Rachford alternating direction method. SIAM J Numer Anal 50(2):700–709
Hsieh CJ, Chang KW, Lin CJ, Keerthi SS, Sundararajan S (2008) A dual coordinate descent method for large-scale linear SVM. In: Proceedings of the 36th international conference on machine learning, pp 408–415
Huang F, Chen S, Huang H (2019) Faster stochastic alternating direction method of multipliers for nonconvex optimization. In: Proceedings of the 36th international conference on machine learning, pp 2839–2848
Joachims T (2006) Training linear SVMs in linear time. In: Proceedings of the 12th ACM SIGKDD international conference on knowledge discovery and data mining, pp 217–226
Johnson R, Zhang T (2013) Accelerating stochastic gradient descent using predictive variance reduction. In: Advances in Neural Information Processing Systems, pp 315-323
Khan ZA, Zubair S, Alquhayz H, Azeem M, Ditta A (2019) Design of momentum fractional stochastic gradient descent for recommender systems. IEEE Access 7:179575–179590
Lin CJ, Weng RC, Sathiya Keerthi S (2008) Trust region Newton method for large-scale logistic regression. J Mach Learn Res 9:627–650
Liu Y, Shang F, Cheng J (2017) Accelerated variance reduced stochastic ADMM. In: Proceedings of the 31st AAAI conference on artificial intelligence, pp 2287-2293
Littlestone N (1988) Learning quickly when irrelevant attributes abound: a new linear-threshold algorithm. Mach Learn 2(4):285–318
Nalepa J, Kawulok M (2019) Selecting training sets for support vector machines: a review. Artif Intell Rev 52(2):857–900
Sammut C, Webb GI (2011) Encyclopedia of Machine Learning. Springer Science & Business Media, New York
Shalev-Shwartz S (2012) Online learning and online convex optimization. Found Trends Mach Learn 4(2):107–194
Shalev-Shwartz S, Singer Y, Srebro N, Cotter A (2011) Pegasos: primal estimated sub-gradient solver for SVM. Math Program 127(1):3–30
Singla M, Shukla KK (2020) Robust statistics-based support vector machine and its variants: a survey. Neural Comput Appl 32:11173–11194
Song T, Li D, Liu Z, Yang W (2019) Online ADMM-based extreme learning machine for sparse supervised learning. IEEE Access 7:64533–64544
Suzuki T (2013) Dual averaging and proximal gradient descent for online alternating direction multiplier method. In: Proceedings of the 30th international conference on machine learning, pp 392–400
Tan C, Ma S, Dai Y H, Qian Y (2016) Barzilai-borwein step size for stochastic gradient descent. Advances in neural information processing systems, pp 685–693
Vapnik V (1995) The nature of statistical learning theory. Springer, New York
Wang L, Zhu J, Zou H (2006) The doubly regularized support vector machine. Stat Sinica 16:589–615
Wang L, Zhu J, Zou H (2008) Hybrid huberized support vector machines for microarray classification and gene selection. Bioinformatics 2(3):412–419
Wang Z, Hu R, Wang S, Jiang J (2014) Face hallucination via weighted adaptive sparse regularization. IEEE Trans Circuits Syst Video Technol 24(5):802–813
Xiao L (2009) Dual averaging methods for regularized stochastic learning and online optimization. In: Advances in neural information processing systems, pp 2116–2124
Xie Z, Li Y (2019) Large-scale support vector regression with budgeted stochastic gradient descent. Int J Mach Learn Cybern 10(6):1529–1541
Xu Y, Akrotirianakis I, Chakraborty A (2016) Proximal gradient method for huberized support vector machine. Pattern Anal Appl 19(4):989–1005
Xue W, Zhang W (2017) Learning a coupled linearized method in online setting. IEEE Trans Neural Netw Learn Syst 28(2):438–450
Zamora E, Sossa H (2017) Dendrite morphological neurons trained by stochastic gradient descent. Neurocomputing 260:420–431
Zhao P, Zhang T (2015) Stochastic optimization with importance sampling for regularized loss minimization. In: Proceedings of the 20th international conference on machine learning
Zhu J, Rosset S, Hastie T, Tibshirani R (2004) 1-norm support vector machines. In: Advances in neural information processing systems, pp 49–56
Zinkevich M (2003) Online convex programming and generalized infinitesimal gradient ascent. In: Proceedings of the 20th international conference on machine learning, pp 928–936
Zou H, Hastie T (2005) Regularization and variable selection via the elastic net. J R Stat Soc B 67(2):301–320
Zou H, Zhang H (2009) On the adaptive elastic-net with a diverging number of parameters. Ann Stat 37(4):1733–1751
Acknowledgements
The authors thank the editor and the reviewers for their constructive comments and suggestions that greatly improved the quality and presentation of this paper. This work was partly supported by the National Natural Science Foundation of China (Grant nos. 12071104, 61671456, 61806004, 61971428), the China Postdoctoral Science Foundation (Grant no. 2020T130767), the Natural Science Foundation of the Anhui Higher Education Institutions of China (Grant no. KJ2019A0082), and the Natural Science Foundation of Zhejiang Province, China (Grant no. LD19A010002).
Author information
Authors and Affiliations
Corresponding authors
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1: Auxiliary Lemmas
To prove Theorems 1, we first give some auxiliary lemmas as follows.
Lemma 1
\(\forall\) \(\varvec{a}, \varvec{b}, \varvec{c} \in \mathbb {R}^n\) and \(h\in \mathbb {R}\), we have
Proof
\(\square\)
Particularly, when h becomes a symmetric matrix H, we have
Following the Lemma 11 given in [35], we obtain the result as follows.
Lemma 2
Under the update rules of Algorithm 1, it holds that
Appendix 2: Proof of Theorem 1
Proof
First, by the definition of \(\mathcal {R}_T\) and taking the optimality conditions for \(\varvec{w}_{t+1}\) and \(\varvec{z}_t\), we have
By using Lemma 1, we have
In addition, it holds that \(\langle \varvec{g}_t,\varvec{w}_{t}-\varvec{w}_{t+1}\rangle \le \frac{\eta _t}{2}\Vert \varvec{g}_t\Vert _{Q_t^{-1}}^2 + \frac{1}{2\eta _t}\Vert \varvec{w}_{t}-\varvec{w}_{t+1}\Vert _{Q_t}^2\). Plugging this inequality, Eq. (19), and Lemma 2 into the right-hand side of Eq. (18) gives
Note that \(Q_t=(\gamma -\rho \eta _t)I\), we have
Further, it follows from \(\langle \beta \nabla q(\varvec{z}_t) + \varvec{\lambda }_t, \varvec{z} -\varvec{z}_t \rangle \ge 0\) that \(\langle \varvec{z}_*- \varvec{z}_{T+1}, \varvec{\lambda }_* - \varvec{\lambda }_{T+1}\rangle \le \langle \varvec{z}_* - \varvec{z}_{T+1}, \beta \nabla q(\varvec{z}_{T+1}) + \varvec{\lambda }_* \rangle\). Then plugging this inequality and Eq. (21) into the right-hand side of Eq. (20) yields
where we use \(\varvec{\lambda }_{t} = \varvec{\lambda }_{t-1} - \rho (\varvec{w}_{t}-\varvec{z}_{t})\) and the initial values of \(\varvec{w}_1\), \(\varvec{z}_1\), and \(\varvec{\lambda }_1\). This gives the result as desired. \(\square\)
Rights and permissions
About this article

Cite this article
Xue, W., Zhong, P., Zhang, W. et al. Sample-based online learning for bi-regular hinge loss. Int. J. Mach. Learn. & Cyber. 12, 1753–1768 (2021). https://doi.org/10.1007/s13042-020-01272-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-020-01272-7