
Abstract
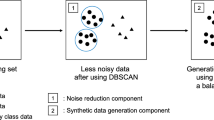
Class imbalance problems are pervasive in many real-world applications, yet classifying imbalanced data remains to be a very challenging task in machine learning. SMOTE is the most influential oversampling approach. Based on SMOTE, many variants have been proposed. However, SMOTE and its variants have three drawbacks: (1) the probability distribution of the minority class samples is not considered; (2) the generated minority samples lack diversity; (3) the generated minority class samples overlap severely when oversampled many times for balancing with majority class samples. In order to overcome these three drawbacks, a generative adversarial network (GAN) based framework is proposed in this paper. The framework includes an oversampling method and a two-class imbalanced data classification approach. The oversampling method is based on an improved GAN model, and the classification approach is based on classifier fusion via fuzzy integral, which can well model the interactions among the base classifiers trained on the balanced data subsets constructed by the proposed oversampling method. Extensive experiments are conducted to compare the proposed methods with related methods on 5 aspects: MMD-score, Silhouette-score, F-measure, G-means, and AUC-area. The experimental results demonstrate that the proposed methods are more effective and efficient than the compared approaches.




Similar content being viewed by others


References
Japkowicz N (2000) The class imbalance problem: significance and strategies. In: Proceedings of the 2000 international conference on artificial intelligence, pp 111–117
Malhotra R, Kamal S (2019) An empirical study to investigate oversampling methods for improving software defect prediction using imbalanced data. Neurocomputing 343:120–140
Zhou J, Liu Y, Zhang TH (2019) Fault diagnosis based on relevance vector machine for fuel regulator of aircraft engine. Int J Mach Learn Cybern 10(7):1779–1790
Dhingra K, Yadav SK (2019) Spam analysis of big reviews dataset using fuzzy ranking evaluation algorithm and Hadoop. Int J Mach Learn Cybern 10(8):2143–2162
Wang S, Yao X (2012) Multiclass imbalance problems: analysis and potential solutions. IEEE Trans Syst Man Cybern Part B Cybern 42(4):1119–1129
Bia JJ, Zhang CS (2018) An empirical comparison on state-of-the-art multi-class imbalance learning algorithms and a new diversified ensemble learning scheme. Knowl Based Syst 158:81–93
García V, Sánchez JS, Marqués AI et al (2020) Understanding the apparent superiority of over-sampling through an analysis of local information for class-imbalanced data. Expert Syst Appl 158:113026
Goodfellow I, Pouget-Abadie J, Mirza M et al (2014) Generative adversarial nets. Adv Neural Inf Process Syst 1:2672–2680
Branco P, Torgo L, Ribeiro R (2016) A survey of predictive modeling on imbalanced domains. ACM Comput Surv 49(2):1–50
Krawczyk B (2016) Learning from imbalanced data: open challenges and future directions. Prog Artif Intell 5:221–232
Sun Y, Kamel MS, Wong AK et al (2007) Cost-sensitive boosting for classification of imbalanced data. Pattern Recognit 40(12):3358–3378
Khan SH, Hayat M, Bennamoun M et al (2018) Cost-sensitive learning of deep feature representations from imbalanced data. IEEE Trans Neural Netw Learn Syst 29(8):3573–3587
Tao X, Li Q, Guo W et al (2019) Self-adaptive cost weights-based support vector machine cost-sensitive ensemble for imbalanced data classification. Inf Sci 487:31–56
Wang Z, Wang B, Cheng Y et al (2019) Cost-sensitive fuzzy multiple kernel learning for imbalanced problem. Neurocomputing 366:178–193
Wang CZ, Wang Y, Shao MW et al (2020) Fuzzy rough attribute reduction for categorical data. IEEE Trans Fuzzy Syst 28(5):818–830
Wang CZ, Huang Y, Shao MW et al (2020) Feature selection based on neighborhood self-information. IEEE Trans Cybern 50(9):4031–4042
Wang CZ, Huang Y, Shao MW et al (2019) Fuzzy rough set-based attribute reduction using distance measures. Knowl Based Syst 164:205–212
Ni P, Zhao SY, Wang XZ et al (2020) Incremental feature selection based on fuzzy rough sets. Inf Sci 536:185–204
Ni P, Zhao SY, Wang XZ et al (2019) PARA: a positive-region based attribute reduction accelerator. Inf Sci 503:533–550
Kovács G (2019) An empirical comparison and evaluation of minority oversampling techniques on a large number of imbalanced datasets. Appl Soft Comput J 83:105662
Elreedy D, Atiya AF (2019) A comprehensive analysis of synthetic minority oversampling technique (SMOTE) for handling class imbalance. Inf Sci 505:32–64
Fernández A, García S, Herrera F et al (2018) SMOTE for learning from imbalanced data: progress and challenges, marking the 15-year anniversary. J Artif Intell Res 61:863–905
Chawla NV, Bowyer KW, Hall LO et al (2002) SMOTE: synthetic minority oversampling technique. J Artif Intell Res 16:321–357
Douzas G, Bacao F, Last F (2018) Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE. Inf Sci 465:1–20
Douzas G, Bacao F (2019) Geometric SMOTE a geometrically enhanced drop-in replacement for SMOTE. Inf Sci 501:118–135
Maldonado S, López J, Vairetti C (2019) An alternative SMOTE oversampling strategy for high-dimensional datasets. Appl Soft Comput 76:380–389
Susan S, Kumar A (2019) \(\text{ SSO}_{\text{ Maj }}\text{-SMOTE-SSO }_{\text{ Min }}\): three-step intelligent pruning of majority and minority samples for learning from imbalanced datasets. Appl Soft Comput 78:141–149
Mathew J, Pang CK, Luo M et al (2018) Classification of imbalanced data by oversampling in kernel space of support vector machines. IEEE Trans Neural Netw Learn Syst 29(9):4065–4076
Raghuwanshi SS, Shukla S (2020) SMOTE based class-specific extreme learning machine for imbalanced learning. Knowl Based Syst 187:104814
Pan TT, Zhao JH, Wu W et al (2020) Learning imbalanced datasets based on SMOTE and Gaussian distribution. Inf Sci 512:1214–1233
Zhang H, Li M (2014) RWO-sampling: a random walk over-sampling approach to imbalanced data classification. Inf Fusion 20:99–116
Han X, Cui R, Lan Y et al (2019) A Gaussian mixture model based combined resampling algorithm for classification of imbalanced credit datasets. Int J Mach Learn Cybern 10:3687–3699
Zhang CK, Zhou Y, Guo JW et al (2019) Research on classification method of high-dimensional class imbalanced datasets based on SVM. Int J Mach Learn Cybern 10:1765–1778
Odena A, Olah C, Shlens J (2017) Conditional image synthesis with auxiliary classifier GANs. Proc Int Conf Mach Learn 70:2642–2651
Ali-Gombe A, Elyan E (2019) MFC-GAN: class-imbalanced dataset classification using multiple fake class generative adversarial network. Neurocomputing 361:212–221
Douzas G, Bacao F (2018) Effective data generation for imbalanced learning using conditional generative adversarial networks. Expert Syst Appl 91:464–471
Zheng M, Li T, Zhu R et al (2020) Conditional Wasserstein generative adversarial network-gradient penalty-based approach to alleviating imbalanced data classification. Inf Sci 512:1009–1023
Arjovsky M, Chintala S, Bottou L (2017) Wasserstein generative adversarial networks. In: International conference on machine learning, pp 214–223
Sun J, Li H, Fujita H et al (2020) Class-imbalanced dynamic financial distress prediction based on Adaboost-SVM ensemble combined with SMOTE and time weighting. Inf Fusion 54:128–144
González S, García S, Lázaro M et al (2017) Class switching according to nearest enemy distance for learning from highly imbalanced data-sets. Pattern Recognit 70:12–24
Gutiérrez-López A, Gutiérrez-López FJA, Figueiras-Vidal AR (2020) Asymmetric label switching resists binary imbalance. Inf Fusion 60:20–24
Raghuwanshi BS, Shukla S (2019) Classifying imbalanced data using ensemble of reduced kernelized weighted extreme learning machine. Int J Mach Learn Cybern 10:3071–3097
Hsiao YH, Su CT, Fu PC (2020) Integrating MTS with bagging strategy for class imbalance problems. Int J Mach Learn Cybern 11:1217–1230
Zhai JH, Zhang SF, Wang CX (2017) The classification of imbalanced large datasets based on MapReduce and ensemble of ELM classifiers. Int J Mach Learn Cybern 8(3):1009–1017
Abdallah ACB, Frigui H, Gader P (2012) Adaptive local fusion with fuzzy integrals. IEEE Trans Fuzzy Syst 20(5):849–864
Zhan YZ, Zhang J, Mao QR (2012) Fusion recognition algorithm based on fuzzy density determination with classification capability and supportability. Pattern Recognit Artif Intell 25(2):346–351
Han H, Wang WY, Mao BH (2005) Borderline-SMOTE: a new oversampling method in imbalanced datasets learning. In: International conference on advances in intelligent computing. Springer, pp 878–887
He HB, Bai Y, Garcia EA et al (2008) ADASYN: adaptive synthetic sampling approach for imbalanced learning. In: IEEE international joint conference on neural networks, IJCNN, pp 1322–1328
Koziarski M, Wozniak M (2017) CCR: a combined cleaning and resampling algorithm for imbalanced data classification. Int J Appl Math Comput Sci 27:727–736
Siriseriwan W, Sinapiromsaran K (2017) Adaptive neighbor synthetic minority oversampling technique under 1NN outcast handling. Songklanakarin J Sci Technol 39(5):565–576
Rivera WA (2017) Noise reduction a priori synthetic over-sampling for class imbalanced datasets. Inf Sci 408:146–161
Rivera WA, Xanthopoulos P (2016) A priori synthetic over-sampling methods for increasing classification sensitivity in imbalanced datasets. Expert Syst Appl 66:124–135
Brownlee J (2016) Image augmentation for deep learning with Keras. https://machinelearningmastery.com/image-augmentation-deep-learning-keras
Alcalá-Fdez J, Fernandez A, Luengo J et al (2011) KEEL data-mining software tool: dataset repository, integration of algorithms and experimental analysis framework. J Mult Valued Logic Soft Comput 17(2–3):255–287
Zhai JH, Zhang SF, Zhang MY et al (2018) Fuzzy integral-based ELM ensemble for imbalanced big data classification. Soft Comput 22(11):3519–3531
Gretton A, Borgwardt KM, Rasch M et al (2016) A kernel method for the two-sample problem. In: Advances in neural information processing systems, vol 19 (NIPS), pp 1672–1679
Rousseeuw PJ (1987) Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. J Comput Appl Math 20:53–65
He HB, Garcia EA (2009) Learning from imbalanced data. IEEE Trans Knowl Data Eng 21(9):1263–1284
Acknowledgements
This research is supported by the national natural science foundation of China (71371063), by the key R&D program of science and technology foundation of Hebei Province (19210310D), by the natural science foundation of Hebei Province (F2017201026), by Postgraduate’s Innovation Fund Project of Hebei University (hbu2019ss077).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zhai, J., Qi, J. & Zhang, S. Imbalanced data classification based on diverse sample generation and classifier fusion. Int. J. Mach. Learn. & Cyber. 13, 735–750 (2022). https://doi.org/10.1007/s13042-021-01321-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-021-01321-9