
Abstract
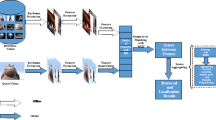
In this paper, we propose studying the impact of clustering on near-duplicate video (NDV) retrieval. The aim is to reduce the search space at retrieval time through a pre-processing clustering step performed on the dataset off-line and retrieving NDVs based on the formed clusters. Our contribution is a novel clustering framework inspired by a bioinformatics technique, namely DNA multiple sequence alignment (MSA). A series of video keyframes in chronological order is represented as an alphabetical genome, analogous to a DNA sequence and MSA is employed to automatically partition the NDVs in a video collection into clusters. After discussing the advantages and shortcomings of the main state-of-the-art clustering approaches for video clustering in the theoretical part of the paper, we empirically evaluate the performance of the proposed MSA-based framework against five clustering algorithms representative of these mainstream approaches: Birch, Cure, Dbscan, Expectation-Maximization and Proclus. Also, we show that our clustering-based approach, while being significantly faster than non-clustering-based n-gram and edit distance NDV retrieval techniques, yields better mean average precision retrieval accuracy.










Similar content being viewed by others


References
Belkhatir M, Tahayna B (2012) Near-duplicate video detection featuring coupled temporal and perceptual visual structures and logical inference based matching. Inf Process Manage 48(3):489–501
Notredame C, Higgins DG, Heringa J (2000) T-coffee: a novel method for fast and accurate multiple sequence alignment. J Mol Biol 302(1):205–217
Edgar RC (2004) MUSCLE: multiple sequence alignment with high accuracy and high throughput. Nucleic Acids Res 32(5):1792–1797
MacQueen J et al (1967) Some methods for classification and analysis of multivariate observations. In: Proceedings of the fifth Berkeley symposium on mathematical statistics and probability, vol 1, pp 281–297
Thompson JD, Higgins DG, Gibson TJ (1994) CLUSTAL W: improving the sensitivity of progressive multiple sequence alignment through sequence weighting, position-specific gap penalties and weight matrix choice. Nucleic Acids Res 22(22):4673–4680
Wu X, Ngo CW, Hauptmann AG, Tan HK (2009) Real-time near-duplicate elimination for web video search with content and context. IEEE Trans Multimedia 11(2):196–207
Yuan J, Tian Q, Ranganath S (2004) Fast and robust search method for short video clips from large video collection. In: Proceedings of the 17th international conference on pattern recognition, ICPR, vol 4, pp 866–869
Feng DF, Doolittle RF (1987) Progressive sequence alignment as a prerequisitet to correct phylogenetic trees. J Mol Evol 25(4):351–360
Song J, Yang Y, Huang Z, Shen HT, Hong R (2011) Multiple feature hashing for real-time large scale near-duplicate video retrieval. In: Proceedings of the 19th ACM international conference on Multimedia, pp 423–432
Shang L, Yang L, Wang F, Chan KP, Hua XS (2010) Real-time large scale near-duplicate web video retrieval. In: Proceedings of 18th ACM international conference on Multimedia, pp 531–540
Cai Y, Yang L, Ping W, Wang F, Mei T, Hua XS, Li S (2011) Million-scale near-duplicate video retrieval system. In: Proceedings of the 19th ACM international conference on multimedia, pp 837–838
Zhang T, Ramakrishnan R, Livny M (1996) BIRCH: an efficient data clustering method for very large databases. ACM SIGMOD Record 25:103–114
Guha S, Rastogi R, Shim K (1998) CURE: an efficient clustering algorithm for large databases. ACM SIGMOD Record 27:73–84
McLachlan GJ, Krishnan T (1997) The EM algorithm and extensions, vol 274. Wiley, New York
Aggarwal CC, Wolf JL, Yu PS, Procopiuc C, Park JS (1999) Fast algorithms for projected clustering. ACM SIGMOD Record 28(2):61–72
Ester M, Kriegel HP, Sander J, Xu X (1996) A density-based algorithm for discovering clusters in large spatial databases with noise. In: Proceedings of the 2nd international conference on knowledge discovery and data mining, vol 1996, pp 226–231
Shen HT, Zhou X, Huang Z, Shao J, Zhou X (2007) UQLIPS: a real-time near-duplicate video clip detection system. In: Proceedings of the 33rd international conference on very large data bases, pp 1374–1377
Tan HK, Ngo CW, Hong R, Chua TS (2009) Scalable detection of partial near-duplicate videos by visual-temporal consistency. In: Proceedings of the 17th ACM international conference on multimedia, pp 145–154
Paisitkriangkrai S, Mei T, Zhang J, Hua XS (2010) Scalable clip-based near-duplicate video detection with ordinal measure. In: Proceedings of the ACM international conference on image and video retrieval, pp 121–128
Duan LY, Yuan JS, Tian Q, Xu CS (2004) Fast and robust video clip search using index structure. In: Proceedings of the 12th annual ACM international conference on multimedia, pp 756–757
Gao L, Li Z, Katsaggelos AK (2008) A kd-tree based dynamic indexing scheme for video retrieval and geometry matching. In: Proceedings of 17th international conference on computer communications and networks, ICCCN’08, pp 1–5
Chatterjee K, Chen SC (2008) GeM-tree: towards a generalized multidimensional index structure supporting image and video retrieval. In: Proceedings of the 10th IEEE international symposium on multimedia, ISM 2008, pp 631–636
Aggarwal CC, Yu PS (2000) Finding generalized projected clusters in high dimensional spaces. In: Proceedings of the ACM SIGMOD international conference on management of data, pp 70–81
Lu G (2002) Techniques and data structures for efficient multimedia retrieval based on similarity. IEEE Trans Multimedia 4(3):372–384
Hua XS, Chen X, Zhang HJ (2004) Robust video signature based on ordinal measure. In: Proceedings of the international conference on image processing, ICIP’04, vol 1, pp 685–688
Zhu J, Hoi SC, Lyu MR, Yan S (2008) Near-duplicate keyframe retrieval by nonrigid image matching. In: Proceedings of the 16th ACM international conference on multimedia, pp 41–50
Ke Y, Sukthankar R, Huston L (2004) Efficient near-duplicate detection and sub-image retrieval. In: Proceedings of the 12th annual ACM international conference on multimedia, pp 869–876
Zhou J, Zhang XP (2005) Automatic identification of digital video based on shot-level sequence matching. In: Proceedings of the 13th annual ACM international conference on multimedia, pp 515–518
Agrawal R, Gehrke J, Gunopulos D, Raghavan P (1998) Automatic subspace clustering of high dimensional data for data mining applications. In: Proceedings of the ACM SIGMOD international conference on management of data, pp 94–105
Cheng X, Chia LT (2010) Stratification-based keyframe cliques for removal of near-duplicates in video search results. In: Proceedings of the international conference on multimedia information retrieval, pp 313–322
Zhou X, Chen L (2010) Monitoring near duplicates over video streams. In: Proceedings of the 18th ACM international conference on multimedia, pp 521–530
Tian X, Yang L, Wang J, Yang Y, Wu X, Hua XS (2008) Bayesian video search reranking. In: Proceeding of the 16th ACM international conference on multimedia, pp 131–140
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Wang, Y., Belkhatir, M. Studying the impact of sequence clustering on near-duplicate video retrieval: an experimental comparison. Int J Multimed Info Retr 4, 279–288 (2015). https://doi.org/10.1007/s13735-013-0043-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13735-013-0043-7