
Abstract
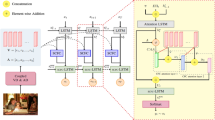
Image to captions has attracted widespread attention over the years. Recurrent neural networks (RNN) and their corresponding variants have been the mainstream when it comes to dealing with image captioning task for a long time. However, transformer-based models have shown powerful and promising performance on visual tasks contrary to classic neural networks. In order to extract richer and more robust multimodal intersection feature representation, we improve the original abstract scene graph to caption model and propose the Caption TLSTMs which is made up of two LSTMs with Transformer blocks in the middle of them in this paper. Compared with the model before improvement, the architecture of our Caption TLSTMs enables the entire network to make the most of the long-term dependencies and feature representation ability of the LSTM, while encoding the multimodal textual, visual and graphic information with the transformer blocks as well. Finally, experiments on VisualGenome and MSCOCO datasets have shown good performance in improving the general image caption generation quality, demonstrating the effectiveness of the Caption TLSTMs model.





Similar content being viewed by others


References
Kiros R, Salakhutdinov R, Zemel R (2014) Multimodal neural language models, In: International conference on machine learning, pp 595-603, PMLR
Hossain MZ, Sohel F, Shiratuddin MF, Laga HJACS (2019) A comprehensive survey of deep learning for image captioning. ACM Comput Surv 51(6):1–36
Li R, Liang H, Shi Y, Feng F, Wang XJN (2020) Dual-CNN: a convolutional language decoder for paragraph image captioning. Neurocomputing 396:92–101
Papineni K, Roukos S, Ward T, W-J. Zhu (2002) Bleu: a method for automatic evaluation of machine translation, In: Proceedings of the 40th annual meeting of the association for computational linguistics, pp 311-318
Banerjee S, Lavie A (2005) METEOR: An automatic metric for MT evaluation with improved correlation with human judgments, In: Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pp 65-72
Lin C-Y (2004) Rouge: a package for automatic evaluation of summaries, In: Text summarization branches out, pp 74-81
Vedantam R, Lawrence Zitnick C, Parikh D (2015) Cider: consensus-based image description evaluation, In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4566-4575
Chen S, Jin Q, Wang P, Wu Q (2020) Say as you wish: Fine-grained control of image caption generation with abstract scene graphs, In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 9962-9971
Vinyals O, Toshev A, Bengio S, Erhan D (2015) Show and tell: a neural image caption generator, In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3156-3164
Anderson P et al (2018) Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering, In: 31st meeting of the IEEE/CVF conference on computer vision and pattern recognition, CVPR 2018, June 18, 2018 - June 22, 2018, Salt Lake City, UT, United states, pp 6077-6086: IEEE Computer Society
Kulkarni G et al. (2011) Baby talk: understanding and generating simple image descriptions, In: 2011 IEEE conference on computer vision and pattern recognition, CVPR 2011, pp 1601-1608: IEEE Computer Society
Yang X, Liu Y, Wang XJ (2021) ReFormer: the relational transformer for image captioning
Jiang W, Ma L, Jiang Y-G, Liu W, Zhang T (2018) Recurrent fusion network for image captioning, In: Proceedings of the european conference on computer vision (ECCV), pp 499-515
Xu K et al (2015) Show, attend and tell: Neural image caption generation with visual attention, In: 32nd international conference on machine learning, ICML 2015, July 6, 2015 - July 11, 2015, Lile, France, vol. 3, pp. 2048-2057: International machine learning society (IMLS)
Xu D, Zhu Y, Choy CB, Fei-Fei L (2017) Scene graph generation by iterative message passing, in Proceedings of the IEEE conference on computer vision and pattern recognition, pp 5410-5419
Zellers R, Yatskar M, Thomson S, Choi Y (2018) Neural motifs: Scene graph parsing with global context, In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 5831-5840
Sun G, Zhang C, Woodland PC (2021) Transformer language models with lstm-based cross-utterance information representation, In: ICASSP 2021-2021 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp. 7363-7367: IEEE
Graves A, Jaitly N, Mohamed A-r (2013) Hybrid speech recognition with deep bidirectional LSTM, In: 2013 IEEE workshop on automatic speech recognition and understanding, 2013, pp. 273-278: IEEE
Soltau H, Liao H, Sak HJ (2016) Neural speech recognizer: Acoustic-to-word LSTM model for large vocabulary speech recognition
Dai Z, Yang Z, Yang Y, Carbonell J, Le QV, Salakhutdinov RJ (2019) Transformer-xl: attentive language models beyond a fixed-length context. arXiv preprint, arXiv:1901.02860
Irie K, Zeyer A, Schlüter R, Ney HJ (2019) Language modeling with deep transformers
Vaswani A et al (2017) Attention is all you need. Advances in neural information processing systems 30, pp 5998-6008
Farhadi A et al (2010) Every picture tells a story: Generating sentences from images, In: European conference on computer vision, pp 15-29, Springer
Gupta A, Verma Y, Jawahar C (2012) Choosing linguistics over vision to describe images, In: Proceedings of the AAAI conference on artificial intelligence, vol. 26(1)
Ordonez V, Kulkarni G, Berg TJA (2011) Im2text: describing images using 1 million captioned photographs, vol. 24, pp 1143-1151
Zhang X et al. (2021) RSTNet: Captioning With Adaptive Attention on Visual and Non-Visual Words, In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 15465-15474
Ushiku Y, Yamaguchi M, Mukuta Y, Harada T (2015) Common subspace for model and similarity: Phrase learning for caption generation from images, In: Proceedings of the IEEE international conference on computer vision, pp 2668-2676
Mitchell M et al. (2012) Midge: Generating image descriptions from computer vision detections, In: Proceedings of the 13th conference of the european chapter of the association for computational linguistics, pp 747-756
Sutskever I, Vinyals O, Le QVJ (2014) Sequence to sequence learning with neural networks
Jia X, Gavves E, Fernando B, Tuytelaars T (2015) Guiding the long-short term memory model for image caption generation, In: 15th IEEE international conference on computer vision, ICCV 2015, December 11, 2015 - December 18, 2015, Santiago, Chile, 2015, vol. 2015 international conference on computer vision, ICCV 2015, pp. 2407-2415: Institute of Electrical and Electronics Engineers Inc
Zhu X, Li L, Liu J, Peng H, Niu XJAS (2018) Captioning transformer with stacked attention modules. Appl Sci 8(5):739
Johnson J et al. (2015) Image retrieval using scene graphs, In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3668-3678
Han K et al (2020) A survey on visual transformer. arXiv e-prints, arXiv:2111.06091
Khan S, Naseer M, Hayat M, Zamir SW, Khan FS, Shah MJ (2021) Transformers in vision: a survey. ACM Computing Surveys (CSUR)
Herdade S, Kappeler A, Boakye K, Soares JJ (2019) Image captioning: transforming objects into words
Li G, Zhu L, Liu P, Yang Y (2019) Entangled transformer for image captioning, In: Proceedings of the IEEE/CVF international conference on computer vision, pp 8928-8937
Cornia M, Stefanini M, Baraldi L, Cucchiara R (2020) Meshed-memory transformer for image captioning, In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 10578-10587
Pan Y, Yao T, Li Y, Mei T (2020) X-linear attention networks for image captioning, In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 10971-10980
Liu X, Zhang P, Yu C, Lu H, Qian X, Yang XJ (2021) A video is worth three views: trigeminal transformers for video-based person re-identification
Schlichtkrull M, Kipf TN, Bloem P, Van Den Berg R, Titov I, Welling M (2018) Modeling relational data with graph convolutional networks, In: European semantic web conference, pp 593-607, Springer
Krishna R et al (2017) Visual genome: connecting language and vision using crowdsourced dense image annotations. Int J Comput Vis 123(1):32–73
Lin T-Y et al (2014) Microsoft coco: Common objects in context, In: European conference on computer vision, pp 740-755, Springer
Karpathy A, Fei-Fei L (2015) Deep visual-semantic alignments for generating image descriptions, In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3128-3137
Ren S, He K, Girshick R, Sun JJA (2015) Faster r-cnn: towards real-time object detection with region proposal networks. Adv Neural Inf Process Syst 28:91-99
Deng J, Dong W, Socher R, Li L-J, Li K, Fei-Fei L (2009) Imagenet: a large-scale hierarchical image database, In: 2009 IEEE conference on computer vision and pattern recognition, pp 248-255: Ieee
Acknowledgements
This work has been supported by the National Natural Science Foundation of China under Contract Nos. 61571453 and 61806218.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Yan, J., Xie, Y., Luan, X. et al. Caption TLSTMs: combining transformer with LSTMs for image captioning. Int J Multimed Info Retr 11, 111–121 (2022). https://doi.org/10.1007/s13735-022-00228-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13735-022-00228-7