
Abstract
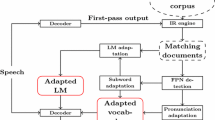
This paper concerns the development of statistical language models of the Slovenian language for use in an automatic speech recognition system. The proposed techniques are language-independent and can be applied to other highly inflected Slavic languages. The large number of unique words in inflected languages is identified as the primary reason for performance degradation. This article discusses the concept of word-formation in the Slovenian language, which is also common to all Slavic languages. The main problems are outlined for word-based language models. A novel variation on the N-gram modelling theme is examined where, instead of using words, modelling units are chosen to be stems and endings. Only data-driven algorithms are employed, which decompose words automatically. A significant reduction in the OOV rate results when using stems and endings for modelling the Slovenian language. The final part of this article focuses on building a speech recogniser. Two different decoding strategies have been employed: one-pass and two-pass search decoders. Language modelling experiments have been performed using the VEČER newswire text corpus, and recognition experiments have been conducted using the SNABI Slovenian speech database. The new language model resulted in the reduction of the OOV rate by 64%, and the recognition accuracy was improved by 4.34%.
Similar content being viewed by others


References
Brown, P.F., Della Pietra, V.J., de Souza, P.V., Lai, J.C., and Mercer, R.L. (1992). Class-based n-gram models of natural language. Computational Linguistics, 18:467-479.
Caflisch, J. (1995). Issues in Russian Linguistics. University Press of America, Inc.
Clarkson, P. and Rosenfeld, R. (1997). Statistical language modeling using the CMU-cambridge toolkit. Proceedings of Eurospeech.
Derouault, A.M. and Mérialdo, B. (1986). Natural language modeling for phoneme-to-text transcription. IEEE Trans. Pattern Anal. Machine Intell., PAMI-8, 6:742-749.
Dimec, J., Džeroski, S., Todorovski, L., and Hristovski, D. (1999). WWW search engine for Slovenian and English medical documents. Medical Informatics Europe, Amsterdam: IOS Press.
Džeroski, S. and Erjavec, T. (2000). Learning to Lemmatise Slovene Words. Learning Language in Logic, 1925:69-88.
El-Beze, M. and Derouault, A.M. (1990). A morphological model for large vocabulary speech recognition. Proceedings of ICASSP.
Geutner, P., Finke, M., and Scheytt, P. (1998). Adaptive vocabularies for transcribing multilingual broadcast news. Proceedings of the ICASSP.
Haji?, J. and Hladká, B. (1998). Tagging inflective languages: Prediction of morphological categories for a rich, structured tagset. Proceedings of the COLING-ACL.
Huang, X., Acero, A., and Hon, H.-W. (2001). Spoken Language Processing: A Guide to Theory, Algorithm and System Development. Prentice Hall.
Jardino, M. (1996). Multilingual stochastic n-gram class language models. Proceedings of the ICASSP.
Jelinek, F. (1986). Self-organized language modeling for speech recognition. IBM Europe Institute, Advances in Speech Processing, Oberlech, Austria.
Jelinek, F. (1998). Statistical Methods for Speech Recognition. Cambridge, MA: The MIT Press.
Kačič, Z., Horvat, B., and Zogling, A. (2000). Issues in design and collection of large telephone speech corpus for Slovenian language. Proceedings of the LREC, pp. 246-249.
Katz, S. (1987). Estimation of probabilities from sparse data for the language model component of a speech recogizer. IEEE Transactions on Acoustics, Speech, and Signal Processing, ASSP-35(3): 400-401.
Maltese, G. and Mancini, F. (1992). An automatic technique to include grammatical and morphological information in a trigrambased statistical language model. Proceedings of the ICASSP, pp. 157-160.
Toporišič, J. (2000). Slovenska slovnica. Založba Obzorja Maribor.
Urban?i?, B., Jedli?ka, A., and Hauser, P. (1980). Češ?ina. Založba Obzorja.
Whittaker, E.W.D. and Woodland, P.C. (1997). Comparison of language modelling techiques for Russian and English. Proceedings of ICSLP.
Young, S., Odell, J., Ollason, D., Kershaw, D., Valtcheva, V., and Woodland, P. (2000). The HTK Book. Entropic Inc.
Yuk, D. (1998). N-best breadth search for LVCSR using a long span language model. 136th Meeting Acoustical Society of America.
Zhao, J., Hamaker, J., Deshmukh, N., Ganapathiraju, A., and Picone, J. (1999). Fast Recognition Techniques for Large Vocabulary Speech Recognition. Texas Instruments Incorporated, Mississippi.
Author information
Authors and Affiliations
Rights and permissions
About this article
Cite this article
Maučec, M.S., Rotovnik, T. & Zemljak, M. Modelling Highly Inflected Slovenian Language. International Journal of Speech Technology 6, 245–257 (2003). https://doi.org/10.1023/A:1023466103841
Issue Date:
DOI: https://doi.org/10.1023/A:1023466103841