
Abstract
This paper examines the applicability of some learning techniques for speech recognition, more precisely, for the classification of phonemes represented by a particular segment model. The methods compared were the IB1 algorithm (TiMBL), ID3 tree learning (C4.5), oblique tree learning (OC1), artificial neural nets (ANN), and Gaussian mixture modeling (GMM), and, as a reference, a hidden Markov model (HMM) recognizer was also trained on the same corpus. Before feeding them into the learners, the segmental features were additionally transformed using either linear discriminant analysis (LDA), principal component analysis (PCA), or independent component analysis (ICA). Each learner was tested with each transformation in order to find the best combination. Furthermore, we experimented with several feature sets, such as filter-bank energies, mel-frequency cepstral coefficients (MFCC), and gravity centers. We found LDA helped all the learners, in several cases quite considerably. PCA was beneficial only for some of the algorithms, and ICA improved the results quite rarely and was bad for certain learning methods. From the learning viewpoint, ANN was the most effective and attained the same results independently of the transformation applied. GMM behaved worse, which shows the advantages of discriminative over generative learning. TiMBL produced reasonable results; C4.5 and OC1 could not compete, no matter what transformation was tried.
Similar content being viewed by others
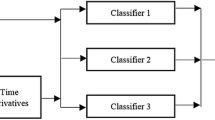

References
Akansu, A.N. and Haddad, R.A. (1992). Multiresolution Signal Decomposition: Transforms, Subbands and Wavelets. New York: Academic Press.
Albesano, D., De Mori, R., Gemello, R., and Mana, F. (1999). A study on the effect of adding new dimensions to trajectories in the acoustic space. In Proceedings of EuroSpeech’99, Budapest, Hungary, pp. 1503–1506.
Alder, M.D. (1994). Principles of Pattern Classification: Statistical, Neural Net and Syntactic Methods of Getting Robots to See and Hear. http://ciips.ee.uwa.edu.au/~mike/PatRec.
Battle, E., Nadeu, C., and Fonollosa, J.A.R. (1998). Feature decorrelation methods in speech recognition. A comparative study. In Proceedings of ICSLP’98, Sydney, Australia.
Comon, P. (1994). Independent component analysis, A new concept? Signal Processing, 36:287–314.
Daelemans, W., Zavrel, J., Sloot, K., and Bosch, A. (1999). TiMBL: Tilburg Memory Based Learner version 2.0 Reference Guide, ILK Technical Report–ILK 99-01, Computational Linguistics, Tilburg University, The Netherlands.
Dempster, A.P., Laird, N.M., and Rubin, D.B. (1977). Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B, 39(1):1–38.
Duda, R. and Hart, P. (1973). Pattern Classification and Scene Analysis. New York: Wiley & Sons.
Fukada, T., Sagisaka, Y., and Paliwal, K.K. (1997). Model parameter estimation for mixture density polynomial segment models. In Proceedings of ICASSP’97, Munich, Germany, pp. 1403–1406.
Fukunaga, K. (1989). Statistical Pattern Recognition. New York, Academic Press.
Gales, M. and Young, S. (1993). Segmental hidden Markov models. In Proceedings of EuroSpeech’93. Berlin, Germany, pp. 1579–1582.
Gish, H. and Ng, K. (1993). A segmental speech model with applications toword spotting. In Proceedings of ICASSP’93. Minneapolis, MN, pp. 447–450.
Glass, J., Chang, J., and McCandless, M. (1996). A probabilistic framework for feature based speech recognition. In Proceedings of ICSLP’96. Philadelphia, PA, pp. 2277–2280.
Halberstadt, A.K. (1998). Heterogeneous Measurements and Multiple Classifiers for Speech Recognition, Department of Electrical Engineering and Computer Science, Massachusetts Institute of Technology, Cambridge, MA, Ph.D. thesis.
Hyvärinen, A. (1997). A family of fixed-point algorithms for independent component analysis. In Proceedings of ICASSP, Munich, Germany.
Hyvärinen, A. (1998). New approximations of differential entropy for independent component analysis and projection pursuit. In Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, pp. 273–279.
Kocsor, A., Kuba, A., Jr., Toth, L., Jelasity, M., Gyimothy, T., and Csirik, J. (1999a). A segment-based statistical speech recognition system for isolated/continuous number recognition. In Software Technology, Fenno-Ugric sumposium FUSST’99,Sagadi, Estonia, pp. 201–209.
Kocsor, A., Kuba, A., Jr., and Toth, L. (1999b). An overview of the OASIS speech recognition project. In Proceedings of ICAI’99, Eger-Noszvaj, Hungary.
Murthy, S.K., Kasif, S., and Salzberg, S. (1994). A system for induction of oblique decision trees. J. Artificial Intelligence Research, 2:1–32.
Ostendorf, M. (1996a). From HMMs to segment models: Stochastic modeling for CSR. In C.-H., Lee, F.K., Soong, and K.K., Paliwal (Eds.), Automatic Speech and Speaker Recognition, Advanced Topics,New York, Kluwer Academic, pp. 185–211.
Ostendorf, M., Digalakis, V.V., and Kimball, O.A. (1996b). From HMMs to segment models: A unified view of stochastic modeling for speech recognition. IEEE Trans. Speech Audio Proc., 4(5):360–378.
Quinlan, J.R. (1993). C4.5: Programs for Machine Learning, San Mateo, California, Morgan Kaufmann.
Rabiner, L. and Juang, B.-H. (1993). Fundamentals of Speech Recognition, Englewood Cliffs, NJ, Prentice Hall.
Schürmann, J. (1996). Pattern Classification, A Unified View of Statistical and Neural Approaches. New York: Wiley & Sons.
Szarvas, M., Mihajlik, P., Fegyó, T., and Tatai, P. (2000). Automatic recognition of Hungarian: Theory and practice. elsewhere in this issue.
Tipping, M.E. and Bishop, C.M. (1997). Probabilistic Principal Component Analysis, Technical Report NCRG/97/010, Neural Computing Research Group, Aston University, Birmingham, United Kingdom.
Author information
Authors and Affiliations
Rights and permissions
About this article
Cite this article
Kocsor, A., Tóth, L., Kuba, A. et al. A Comparative Study of Several Feature Transformation and Learning Methods for Phoneme Classification. International Journal of Speech Technology 3, 263–276 (2000). https://doi.org/10.1023/A:1026554814106
Issue Date:
DOI: https://doi.org/10.1023/A:1026554814106