
Abstract
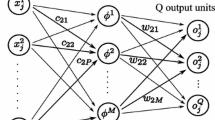
A new methodology for neural learning is presented. Only a single iteration is needed to train a feed-forward network with near-optimal results. This is achieved by introducing a key modification to the conventional multi-layer architecture. A virtual input layer is implemented, which is connected to the nominal input layer by a special nonlinear transfer function, and to the first hidden layer by regular (linear) synapses. A sequence of alternating direction singular value decompositions is then used to determine precisely the inter-layer synaptic weights. This computational paradigm exploits the known separability of the linear (inter-layer propagation) and nonlinear (neuron activation) aspects of information transfer within a neural network. Examples show that the trained neural networks generalize well.
Similar content being viewed by others


References
Hassoun, M. H.: Fundamentals of Artificial Neural Networks, MIT Press, 1995.
Bishop, C. M.: Neural Networks for Pattern Recognition, Oxford University Press, 1997.
Beckerman, M.: Adaptive Cooperative Systems, Wiley Interscience, 1997.
White, D. A. and Sofge, D. A.: Handbook of Intelligent Control: Neural, Fuzzy and Adaptive Approaches, Van Nostrand Reinhold, 1992.
Cichocki, A. and Unbehauen, R.: Neural Networks for Optimization and Signal Processing, Wiley, 1993.
Mars, P., Chen, J. R. and Nambiar, R.: Learning Algorithms, CRC Press, 1996.
Chauvin, Y. and Rumelhart, D. E.: Backpropagation: Theory, Architectures, and Applications, Lawrence Erlbaum, 1995.
Barhen, J., Gulati, S. and Zak, M.: Neural learning of constrained nonlinear transformations, IEEE Computer, 22(6) (1989), 67-76.
Barhen, J., Toomarian, N. and Gulati, S.: Applications of adjoint operators to neural networks, Appl. Math. Lett., 3(3) (1990), 13-18.
Toomarian, N. and Barhen, J.: Learning a trajectory using adjoint functions and teacher forcing, Neural Networks, 5 (1992), 473-484; ibid., U.S. Patent No. 5,428,710, March 28, 1995.
Barhen, J., Protopopescu, V. and Reister, D.: TRUST: A deterministic algorithm for global optimization, Science, 276 (1997), 1094-1097.
Shepherd, A. J.: Second-Order Methods for Neural Networks, Springer, 1997.
Biegler-König, F. and Bärman, F.: A learning algorithm for multilayered neural networks based on linear least squares problems, Neural Networks, 6 (1993), 127-131.
Tam, Y. F. and Chow, T. W. S.: Accelerated training algorithm for feedforward neural networks based on least squares method, Neural Processing Letters, 2(4) (1995), 20-25.
Golub, G. and Van Loan, V.: Matrix Computations, Johns Hopkins University Press, Baltimore, 1983.
Author information
Authors and Affiliations
Rights and permissions
About this article
Cite this article
Barhen, J., Cogswell, R. & Protopopescu, V. Single-Iteration Training Algorithm for Multi-Layer Feed-Forward Neural Networks. Neural Processing Letters 11, 113–129 (2000). https://doi.org/10.1023/A:1009682730770
Issue Date:
DOI: https://doi.org/10.1023/A:1009682730770