
Abstract
The Tangut script was a logographic writing system used for the extinct Tangut language of the Western Xia Dynasty, which spanned 1038 to 1227. The technic of optical character recognition, machine learning, and computer vision will help greatly in the unscrambling of the character in the ancient scripts. But all these technics are based on the character database, which provides learning samples and test standards. In the process of building the Tangut Character Databases using the ancient Tangut scripts as a data source, it is found that the problem of imbalanced class distribution significantly compromises the performance of learning algorithms. A method of synthetic sample generation was proposed in this paper to improve the performance of learning and recognition of Tangut characters. The comparison of recognition accuracy between the learning base in the original data set and the synthetic generated data set was demonstrated, and presented an impressive superiority utilizing the researchers’ method. The organization of Tangut character databases was also introduced in this paper.
Similar content being viewed by others

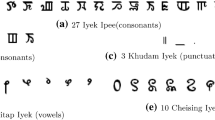
References
Tianshun, W., The Battle History of Western Xia, Ningxia People’s Press, 1993.
Ren, B., Western Xia: The Kingdom Lost in Historical Memories, Beijing: Foreign Language Press, 2005.
Fanwen, L., Comprehensive History of Western Xia, Beijing, Yinchuan: People’s Press, Ningxia People’s Press, 2005.
Kwanten, L., The structure of the Tangut Hsi-Hsia characters, Toung Pao, 1989, vol. 75, pp. 1–42.
Xirong, M. and Xingyu, W., Preprocessing in XIXIA character recognition system, Comput. Eng. Appl., 2002, pp. 48–50.
Xirong, M. and Xingyu, W., Study on feature extraction of Xixia characters, Comput. Eng. Appl., 2002, pp. 38–41.
Xirong, M. and Xingyu, W., Study on the extraction of stroke for Xixia characters based on thinning, Comput. Eng. Appl., 2002, pp. 30–31, 47.
Guangfu, M., Chen, P., and Changqing, L., Xixia characters recognition based on elastic mesh, J. Chin. Inf. Process., 2011, pp. 109–113.
He, H.B. and Garcia, E.A., Learning from imbalanced data, IEEE Trans. Knowl. Data Eng., 2009, vol. 21, pp. 1263–1284.
Chawla, N.V., Bowyer, K.W., Hall, L.O., and Kegelmeyer, W.P., SMOTE: Synthetic minority over-sampling technique, J. Artif. Intell. Res., 2002, vol. 16, pp. 321–357.
Sun, Y., Wang, Y., and Wang, Y., Boosting for learning multiple classes with imbalanced class distribution, International Conference on Data Mining, 2006, pp. 592–602.
Abe, N., Zadrozny, B., and Langford, J., An iterative method for multi-class cost-sensitive learning, Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2004, pp. 3–11.
Tan, A.C., Gilbert, D., and Deville, Y., Multi-class protein fold classification using a new ensemble machine learning approach, Genome Inf., 2003, vol. 14, pp. 206–217.
Zhou, Z.H. and Liu, X.Y., Training cost-sensitive neural networks with methods addressing the class imbalance problem, IEEE Trans. Knowl. Data Eng., 2006, vol. 18, pp. 63–77.
Zhou, Z.H. and Liu, X.Y., On multi-class cost-sensitive learning, Comput. Intell., 2010, vol. 26, pp. 232–257.
Chen, K., Lu, B.L., and Kwok, J.T., Efficient classification of multi-label and imbalanced data using min-max modular classifiers, International Joint Conference on Neural Networks, 2006, pp. 1770–1775.
Liu, C.L., Yin, F., Wang, D.H., and Wang, Q.F., CASIA online and offline Chinese handwriting databases, 2011 International Conference on Document Analysis and Recognition, 2011, pp. 37–41.
Xuejun, F., Interpretion of Tangut shi ding pin of Flower Garland Sutra, Doctoral Dissertation, Shaanxi Normal University, 2013.
Fanwen, L., Tangut-Chinese Dictionary, Beijing: China Social Sciences Press, 1997.
Schaefer, S., Mcphail, T., and Warren, J., Image deformation using moving least squares, ACM Trans. Graph., 2006, vol. 25, pp. 533–540.
Author information
Authors and Affiliations
Corresponding author
Additional information
The article is published in the original.
About this article

Cite this article
Meng, Y., Yuan, X., Wei, X. et al. Synthetic Sample Extension in Implementation of Tangut Character Databases. Aut. Control Comp. Sci. 52, 334–343 (2018). https://doi.org/10.3103/S0146411618040089
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3103/S0146411618040089