
Abstract
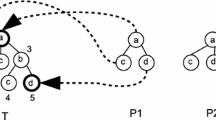
In this paper, we propose an efficient algorithm enumerating all frequent subtrees containing all special nodes that are guaranteed to be included in all trees belonging to a given data. Our algorithm is a modification of TreeMiner algorithm [10] so as to efficiently generate only candidate subtrees satisfying our constraints. We report mining results obtained by applying our algorithm to the problem of finding frequent structures containing the name and reputation of given restaurants in Web pages collected by a search engine.
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others

References
Agrawal, R., Srikant, R.: First algorithms for mining association rules. In: Proc. 20th Int’l Conf. on VLDB, pp. 487–499 (1994)
Agrawal, R., Srikant, R.: Mining sequential patterns. In: Proc. 11th Int’l Conf. on Data Eng., pp. 3–14 (1995)
Asai, T., Abe, K., Kawasoe, S., Arimura, H., Sakamoto, H., Arikawa, S.: Efficient substructure discovery from large semi-structured data. In: Proc. 2nd SIAM Int’l Conf. on Data Mining, pp. 158–174 (2002)
Cohen, W.W., Hurst, M., Jensen, L.S.: A flexible learning system for wrapping tables and lists in HTML documents. In: Proc. 11th Int’l World Wide Web Conf., pp. 232–241 (2002)
Garofalakis, M., Rastogi, R., Shim, K.: Mining sequential patterns with regular expression constraints. IEEE Transactions on Knowledge and Data Engineering 14(3), 530–552 (2002)
Inokuchi, A., Washio, T., Motoda, H.: An apriori-based algorithm for mining frequent substructures from graph data. In: Zighed, D.A., Komorowski, J., Żytkow, J.M. (eds.) PKDD 2000. LNCS (LNAI), vol. 1910, pp. 13–23. Springer, Heidelberg (2000)
Hasegawa, H., Kudo, M., Nakamura, A.: Reputation Extraction Using Both Structural and Content Information. Technical Report TCS-TR-A-05-2 (2005), http://www-alg.ist.hokudai.ac.jp/tra.html
Kushmerick, N.: Wrapper induction:efficiency and expressiveness. Artificial Intelligence (118), 15–68 (2000)
Srikant, R., Vu, Q., Agrawal, R.: Mining association rules with item constraints. In: Proc. 3rd Int’l Conf. on Knowledge Discovery and Data Mining, pp. 67–73 (1997)
Zaki, M.J.: Efficiently mining frequent trees in a forest. In: Proc. SIGKDD 2002, pp. 71–80 (2002)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2005 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Nakamura, A., Kudo, M. (2005). Mining Frequent Trees with Node-Inclusion Constraints. In: Ho, T.B., Cheung, D., Liu, H. (eds) Advances in Knowledge Discovery and Data Mining. PAKDD 2005. Lecture Notes in Computer Science(), vol 3518. Springer, Berlin, Heidelberg. https://doi.org/10.1007/11430919_101
Download citation
DOI: https://doi.org/10.1007/11430919_101
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-26076-9
Online ISBN: 978-3-540-31935-1
eBook Packages: Computer ScienceComputer Science (R0)