
Abstract
In the domain of bioinformatics, extracting a relation such as protein-protein interations from a large database of text documents is a challenging task. One major issue with biomedical information extraction is how to efficiently digest the sheer size of unstructured biomedical data corpus. Often, among these huge biomedical data, only a small fraction of the documents contain information that is relevant to the extraction task. We propose a novel query expansion algorithm to automatically discover the characteristics of documents that are useful for extraction of a target relation. Our technique introduces a hybrid query re-weighting algorithm combining the modified Robertson Sparck-Jones query ranking algorithm with a keyphrase extraction algorithm. Our technique also adopts a novel query translation technique that incorporates POS categories to query translation. We conduct a series of experiments and report the experimental results. The results show that our technique is able to retrieve more documents that contain protein-protein pairs from MEDLINE as iteration increases. Our technique is also compared with SLIPPER, a supervised rule-based query expansion technique. The results show that our technique outperforms SLIPPER from 17.90% to 29.98 better in four iterations.
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others


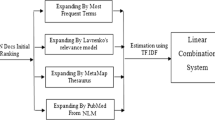
References
Agichtein, E., Gravano, L.: Querying Text Databases for Efficient Information Extraction. In: Proceedings of the 19th IEEE International Conference on Data Engineering (ICDE), pp. 113–124 (2003)
Chang, K.C., Garcia-Molina, H., Paepcke, A.: Boolean Query Mapping Across Heterogeneous Information Sources. IEEE Transactions on Knowledge and Data Engineering 8(4), 515–521 (1996)
Cohen, W.W., Singer, Y.: Simple, Fast, and Effective Rule Learner. In: Proceedings of the Sixteenth National Conference on Artificial Intelligence and Eleventh Conference on Innovative Applications of Artificial Intelligence, July 18-22, pp. 335–342 (1999)
French, J.C., Brown, D.E., Kim, N.H.: A Classification Approach to Boolean Query Reformulation. Journal of the American Society for Information Science 48(8), 694–706 (1997)
Salton, G., Buckley, C., Fox, E.A.: Automatic query formulations in information retrieval. Journal of the American Society for Information Science 34(4), 262–280 (1983)
Song, M., Song, I.Y., Hu, T.: KPSpotter: A Flexible Information Gain-based Keyphrase Extraction System. In: Fifth International Workshop on Web Information and Data Management (WIDM 2003), pp. 50–53 (2003)
Van Der Pol, R.: Dipe-D: a Tool For Knowledge-based Query Formulation. Information Retrieval 6, 21–47 (2003)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2005 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Song, M., Song, IY., Hu, X., Allen, R.B. (2005). An Automatic Unsupervised Querying Algorithm for Efficient Information Extraction in Biomedical Domain. In: Ho, T.B., Cheung, D., Liu, H. (eds) Advances in Knowledge Discovery and Data Mining. PAKDD 2005. Lecture Notes in Computer Science(), vol 3518. Springer, Berlin, Heidelberg. https://doi.org/10.1007/11430919_22
Download citation
DOI: https://doi.org/10.1007/11430919_22
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-26076-9
Online ISBN: 978-3-540-31935-1
eBook Packages: Computer ScienceComputer Science (R0)