
Abstract
Given strings S 1, S 2, and a regular expression R, we introduce regular expression constrained sequence alignment as the problem of finding the maximum alignment score between S 1 and S 2 over all alignments such that in these alignments there exists a segment where some substring s 1 of S 1 is aligned with some substring s 2 of S 2, and both s 1 and s 2 match R, i.e. s 1,s 2 ∈ L(R) where L(R) is the regular language described by R. A motivation for the problem is that protein sequences can be aligned in a way that known motifs guide the alignments. We present an O(nmr) time algorithm for the regular expression constrained sequence alignment problem where n, and m are the lengths of S 1, and S 2, respectively, and r is in the order of the size of the transition function of a finite automaton M that we create from a nondeterministic finite automaton N accepting L(R). M contains O(t 2) states if N has t states.
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others


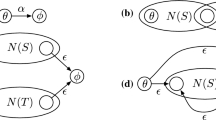
References
Arslan, N., Eğecioğlu, Ö.: Algorithms for the constrained common sequence problem. In: Simanek, M., Holub, J. (eds.) Proc. Prague Stringology Conference 2004, Prague, August 2004, pp. 24–32 (2004)
Bork, P., Koonin, E.V.: Protein sequence motifs. Curr. Opin. Struct. Biol. 6, 366–376 (1996)
Chin, F.Y.L., Ho, N.L., Lam, T.W., Wong, P.W.H., Chan, M.Y.: Efficient constrained multiple sequence alignment with performance guarantee. In: Proc. IEEE Computational Systems Bioinformatics (CSB 2003), pp. 337–346 (2003)
Comet, J.-P., Henry, J.: Pairwise sequence alignment using a PROSITE patternderived similarity score. Computers and Chemistry 26, 421–436 (2002)
Doolittle, R.F.: Similar amino acid sequences: chance or common ancestry. Science 214, 149–159 (1981)
Hopcroft, J.E., Ullman, J.D.: Introduction to automata theory, languages, and computation. Addison-Wesley Publishing Company, Reading (1979)
Chin, F.Y.L., Santis, A.D., Ferrara, A.L., Ho, N.L., Kim, S.K.: A simple algorithm for the constrained sequence problems. Information Processing Letters 90, 175–179 (2004)
Falquet, L., Pagni, M., Bucher, P., Hulo, N., Sigrist, C.J., Hofmann, K., Bairoch, A.: The PROSITE database, its status in 2002. Nucleic Acids Res. 30, 235–238 (2002)
Tang, C.Y., Lu, C.L., Chang, M.D.-T., Tsai, Y.-T., Sun, Y.-J., Chao, K.-M., Chang, J.M., Chiou, Y.-H., Wu, C.-M., Chang, H.-T., Chou, W.-I.: Constrained multiple sequence alignment tool development and its applications to rnase family alignment. In: Proceeding of the 1st IEEE Computer Society Bioinformatics Conference (CSB 2002), pp. 127–137 (2002)
Tsai, Y.-T.: The constrained common sequence problem. Information Processing Letters 88, 173–176 (2003)
Tsai, Y.-T., Lu, C.L., Yu, C.T., Huang, Y.P.: MuSiC: A tool for multiple sequence alignment with constraint. Bioinformatics 20(14), 2309–2311 (2004)
Walker, J.E., Saraste, M., Runswick, M.J., Gay, N.J.: Distantly related sequences in the alpha- and beta-subunits of ATP synthase, myosin, kinases and other ATPrequiring enzymes and a common nucleotide binding fold. EMBO J. 1, 945–951 (1982)
Waterman, M.S.: Introduction to computational biology. Chapman & Hall, Boca Raton (1995)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2005 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Arslan, A.N. (2005). Regular Expression Constrained Sequence Alignment. In: Apostolico, A., Crochemore, M., Park, K. (eds) Combinatorial Pattern Matching. CPM 2005. Lecture Notes in Computer Science, vol 3537. Springer, Berlin, Heidelberg. https://doi.org/10.1007/11496656_28
Download citation
DOI: https://doi.org/10.1007/11496656_28
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-26201-5
Online ISBN: 978-3-540-31562-9
eBook Packages: Computer ScienceComputer Science (R0)