
Abstract
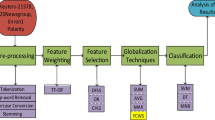
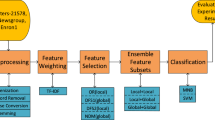
Fish-net algorithm is a novel field learning algorithm which derives classification rules by looking at the range of values of each attribute instead of the individual point values. In this paper, we present a Feature Selection Fish-net learning algorithm to solve the Dual Imbalance problem on text classification. Dual imbalance includes the instance imbalance and feature imbalance. The instance imbalance is caused by the unevenly distributed classes and feature imbalance is due to the different document length. The proposed approach consists of two phases: (1) select a feature subset which consists of the features that are more supportive to difficult minority class; (2) construct classification rules based on the original Fish-net algorithm. Our experimental results on Reuters21578 show that the proposed approach achieves better balanced accuracy rate on both majority and minority class than Naive Bayes MultiNomial and SVM.
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others

References
Forman, G.: A pitfall and solution in multi-class feature selection for text classification. In: Proceedings of the 21st International Conference on Machine Learning (2004)
Zheng, Z., Wu, X., Srihari, R.: Feature selection for text categorization on imbalanced data. ACM SIGKDD Explorations Newsletter:Special issue on learning from imbalanced datasets 6, 80–89 (2004)
Dai, H., Hang, X., Li, G.: Inexact field learning: An approach to induce high quality rules from low quality data. In: Proceedings of 2001 IEEE International Conference on Data Mining (2001)
Ciesielski, V., Dai, H.: Fisherman: a comprehensive discovery, learning and forecasting systems. In: Proceedings of 2nd Singapore International Conference on Intelligent System, pp. B297(1)–B297(6) (1994)
Dai, H., Ciesielski, V.: Learning of inexact rules by the fish-net algorithm from low quality data. In: Proceedings of the Eighth Australian Joint Artificial Intelligence Conference, pp. 108–115 (1994)
Witten, I.H., Frank, E.: Data mining: practical machine learning tools and techniques with Java implementations. Morgan Kaufmann, San Francisco (1999)
Joachims, T.: Making large-scale support vector machine learning practical. In: Scholkopf, B., Burges, C., Smola, A.S. (eds.) Advances in Kernel Methods: Support Vector Machines, MIT Press, Cambridge (1998)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2005 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Zhuang, L., Dai, H., Hang, X. (2005). A Novel Field Learning Algorithm for Dual Imbalance Text Classification. In: Wang, L., Jin, Y. (eds) Fuzzy Systems and Knowledge Discovery. FSKD 2005. Lecture Notes in Computer Science(), vol 3614. Springer, Berlin, Heidelberg. https://doi.org/10.1007/11540007_6
Download citation
DOI: https://doi.org/10.1007/11540007_6
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-28331-7
Online ISBN: 978-3-540-31828-6
eBook Packages: Computer ScienceComputer Science (R0)