
Abstract
With the increasing amount of biomedical literature, there is a need for automatic extraction of information to support biomedical researchers. Due to incomplete biomedical information databases, the extraction cannot be done straightforward using dictionaries, so several approaches using contextual rules and machine learning have previously been proposed. Our work is inspired by the previous approaches, but is novel in the sense that it combines Google and Gene Ontology for annotating protein interactions. We got promising empirical results – 57.5% terms as valid GO annotations, and 16.9% protein names in the answers provided by our system gProt. The total error-rate was 25.6% consisting mainly of overly general answers and syntactic errors, but also including semantic errors, other biological entities (than proteins and GO-terms) and false information sources.
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others
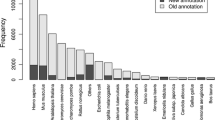
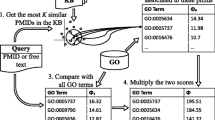
References
Bunescu, R., Ge, R., Kate, R.J., Marcotte, E.M., Mooney, R.J., Ramani, A.K., Wong, Y.W.: Comparative Experiments on Learning Information Extractors for Proteins and their Interactions. Journal Artificial Intelligence in Medicine: Special Issue on Summarization and Information Extraction from Medical Documents (2004) (forthcoming)
Cimiano, P., Staab, S.: Learning by Googling. SIGKDD Explorations Newsletter 6(2), 24–34 (2004)
Cowie, J., Lehnert, W.: Information Extraction. Communications of the ACM 39(1), 80–91 (1996)
Dill, S., Eiron, N., Gibson, D., Gruhl, D., Guha, R., Jhingran, A., Kanungo, T., Rajagopalan, S., Tomkins, A., Tomlin, J.A., Zien, J.Y.: SemTag and seeker: bootstrapping the semantic web via automated semantic annotation. In: Proceedings of the Twelfth International World Wide Web Conference, WWW 2003, pp. 178–186. ACM, New York (2003)
Dingare, S., Finkel, J., Manning, C., Nissim, M., Alex, B.: Exploring the Boundaries: Gene and Protein Identification in Biomedical Text. In: Proceedings of the BioCreative Workshop (March 2004)
Dingare, S., Finkel, J., Manning, C., Nissim, M., Alex, B., Grover, C.: Exploring the Boundaries: Gene and Protein Identification in Biomedical Text. Submitted to BMC Bioinformatics (2004)
Etzioni, O., Cafarella, M., Downey, D., Popescu, A.-M., Shaked, T., Soderland, S., Weld, D.S., Yates, A.: Unsupervised Named-Entity Extraction from the Web: An Experimental Study. Submitted to Artificial Intelligence (2004)
Tsuji, J.i., Wong, L.: Natural Language Processing and Information Extraction in Biology. In: Proceedings of the Pacific Symposium on Biocomputing 2001, pp. 372–373 (2001)
Jenssen, T.-K., Lægreid, A., Komorowski, J., Hovig, E.: A literature network of human genes for high-throughput analysis of gene expression. Nature Genetics 28(1), 21–28 (2001)
Kakade, V., Sharangpani, M.: Improving the Precision of Web Search for Medical Domain using Automatic Query Expansion. Online (2004)
Kruschwitz, U.: Automatically Acquired Domain Knowledge for ad hoc Search: Evaluation Results. In: Proceedings of the 2003 Intl. Conf. on Natural Language Processing and Knowledge Engineering (NLP-KE 2003), IEEE, Los Alamitos (2003)
Martin, E.P.G., Bremer, E.G., Guerin, M.-C., DeSesa, C., Jouve, O.: Analysis of Protein/Protein Interactions Through Biomedical Literature: Text Mining of Abstracts vs. Text Mining of Full Text Articles. In: López, J.A., Benfenati, E., Dubitzky, W. (eds.) KELSI 2004. LNCS (LNAI), vol. 3303, pp. 96–108. Springer, Heidelberg (2004)
Parry, D.: A fuzzy ontology for medical document retrieval. In: Proceedings of the second workshop on Australasian information security, Data Mining and Web Intelligence, and Software Internationalisation, vol. 32, pp. 121–126. ACM Press, New York (2004)
Sætre, R.: GeneTUC, A Biolinguistic Project. (Master Project) Norwegian University of Science and Technology, Norway (June 2002)
Sætre, R.: Natural Language Processing of Gene Information. Master’s thesis, Norwegian University of Science and Technology, Norway and CIS/LMU Munchen, Germany (April 2003)
Sætre, R., Tveit, A., Steigedal, T.S., Lægreid, A.: Semantic Annotation of Biomedical Literature using Google. In: Gavrilova, M., Mun, Y., Taniar, D., Gervasi, O., Tan, K., Kumar, V. (eds.) Proceedings of the International Workshop on Data Mining and Bioinformatics (DMBIO2005), Singapore, May 2005. LNCS, Springer, Heidelberg (2005) (forthcoming)
Shah, U., Finin, T., Joshi, A.: Information Retrieval on the Semantic Web. In: Proceedings of CIKM 2002, pp. 461–468. ACM Press, New York (2002)
Shatkay, H., Feldman, R.: Mining the Biomedical Literature in the Genomic Era: An Overview. Journal of Computational Biology 10(6), 821–855 (2003)
Tveit, A., Sætre, R., Steigedal, T.S., Lægreid, A.: ProtChew: Automatic Extraction of Protein Names from Biomedical Literature. In: Proceedings of the International Workshop on Biomedical Data Engineering (BMDE 2005, in conjunction with ICDE 2005), Tokyo, Japan, April 2005, IEEE Press, Los Alamitos (2005) (forthcoming)
Wong., L.: Limsoon Wong. A Protein Interaction Extraction System. In: Proceedings of the Pacific Symposium on Biocomputing 2001, pp. 520–530 (2001)
Wong, L.: Gaps in Text-based Knowledge Discovery for Biology. Drug Discovery Today 7(17), 897–898 (2002)
Yu, H., Hatzivassiloglou, V., Friedman, C., Rzhetsky, A., John Wilbur, W.: Automatic Extraction of Gene and Protein Synonyms from MEDLINE and Journal Articles. In: Proceedings of the AMIA Symposium 2002, pp. 919–923 (2002)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2005 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Sætre, R. et al. (2005). gProt: Annotating Protein Interactions Using Google and Gene Ontology. In: Khosla, R., Howlett, R.J., Jain, L.C. (eds) Knowledge-Based Intelligent Information and Engineering Systems. KES 2005. Lecture Notes in Computer Science(), vol 3683. Springer, Berlin, Heidelberg. https://doi.org/10.1007/11553939_166
Download citation
DOI: https://doi.org/10.1007/11553939_166
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-28896-1
Online ISBN: 978-3-540-31990-0
eBook Packages: Computer ScienceComputer Science (R0)