
Abstract
Embedded devices designed for various real-time multimedia and telecom applications, have a bottleneck in energy consumption and performance that becomes day by day more crucial. This is imposed by the increasing gap between processor and memory speed. Many authors have addressed this problem, but all existing techniques either consider only performance without any other trade-off, or they operate at the level of individual loops. We fill this gap, by presenting a technique which achieves parallelization in the memory accesses through four loop transformations. Our estimations from two real-life applications from the multimedia and telecom domain, reveal that using our technique, we can either increase the performance (up to 35%) or lower the energy consumption (up to 20%) for the same cost.
This work was partially sponsored by a scholarship from Public Benefit Foundation of Alexander S. Onasis and from Marie Curie Host Fellowship project HPMT-CT-2000-00031
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others
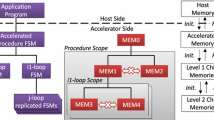
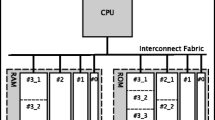
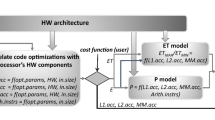
References
Catthoor, F., Wuytack, S., Greef, E.D., Balasa, F., Nachtergaele, L., Vandecappelle, A.: Custom Memory Management Methodology, Exploration of memory organization for embedded multimedia system design. Kluwer Academic Publishers, Boston (1998)
Panda, P., Catthoor, F., Dutt, N., Danckaert, K., Brockmeyer, E., Kulkarni, C., Vandecappelle, A., Kjeldsberg, P.: Data and memory optimizations for embedded systems. ACM Trans. on Design Automation for Embedded Systems (TODAES) 6, 142–206 (2001)
Ding, C., Kennedy, K.: The memory bandwidth bottleneck and its amelioration by a compiler. In: IEEE 14th International Parallel and Distributed Processing Symposium (IPDPS 2000), pp. 181–189 (2000)
Wand, Z., Kirkpatrick, M., Sha, E.H.M.: Optimal two level partitioning and loop scheduling for hiding memory latency for dsp applications. In: Design Automation Conference (DAC), pp. 540–545 (2000)
Fraboulet, A., Huard, G., Mignotte, A.: Loop alignment for memory accesses optimization. In: 12th International Symposium on System Synthesis (ISSS), pp. 71–77 (1999)
Kandemir, M., Choudhary, A.: Compiler-directed scratch pad memory hierarchy design and management. In: 39th ACM/IEEE DAC, pp. 690–695 (2002)
Altman, E., Gao, G.: Optimal software pipelining through enumeration of schedules. In: Proceedings of EuroPar Conf., Lyon, France. Lecture Notes in computer science, pp. 833–840. Springer, Heidelberg (1996)
Wuytack, S., Catthoor, F., Jong, G.D., Man, H.J.D.: Minimizing the required memory bandwidth in VLSI system realizations. IEEE Trans. VLSI Systems 7, 433–441 (1999)
IMEC (2005), http://www.imec.be/design/atomium/
Strobach, P.: QSDPCM - a new technique in scene adaptive coding. In: Proceedings 4th Eur. Signal Processing Conf (EUSIPCO), pp. 1141–1144 (1988)
Shreedhar, M., Varghese, G.: Efficient fair queuing using deficit round robin. In: Proceedings of ACM SIGCOMM, pp. 231–242 (1995)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2005 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Dasygenis, M., Brockmeyer, E., Catthoor, F., Soudris, D., Thanailakis, A. (2005). Improving the Memory Bandwidth Utilization Using Loop Transformations. In: Paliouras, V., Vounckx, J., Verkest, D. (eds) Integrated Circuit and System Design. Power and Timing Modeling, Optimization and Simulation. PATMOS 2005. Lecture Notes in Computer Science, vol 3728. Springer, Berlin, Heidelberg. https://doi.org/10.1007/11556930_13
Download citation
DOI: https://doi.org/10.1007/11556930_13
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-29013-1
Online ISBN: 978-3-540-32080-7
eBook Packages: Computer ScienceComputer Science (R0)