
Abstract
Discriminatory information about person identity is multimodal. Yet, most person recognition systems are unimodal, e.g. the use of facial appearance. With a view to exploiting the complementary nature of different modes of information and increasing pattern recognition robustness to test signal degradation, we developed a multiple expert biometric person identification system that combines information from three experts: face, visual speech, and audio. The system uses multimodal fusion in an automatic unsupervised manner, adapting to the local performance and output reliability of each of the experts. The expert weightings are chosen automatically such that the reliability measure of the combined scores is maximized. To test system robustness to train/test mismatch, we used a broad range of Gaussian noise and JPEG compression to degrade the audio and visual signals, respectively. Experiments were carried out on the XM2VTS database. The multimodal expert system out performed each of the single experts in all comparisons. At severe audio and visual mismatch levels tested, the audio, mouth, face, and tri-expert fusion accuracies were 37.1%, 48%, 75%, and 92.7% respectively, representing a relative improvement of 23.6% over the best performing expert.
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others

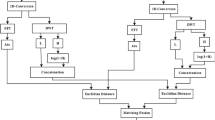

References
Blackburn, D., Bone, M., Phillips, P.J.: Facial Recognition Vendor Test 2000. Evaluation report (2000)
Gross, R., Shi, J., Cohn, J.F.: Quo Vadis Face Recognition. In: Third Workshop on Empirical Evaluation Methods in Computer Vision (2001)
Fox, N.A., Reilly, R.B.: Audio-Visual Speaker Identification Based on the Use of Dynamic Audio and Visual Features. In: Proc. of the fourth Int’l Conf. on Audio- and Video-Based Biometric Person Authentication, Guildford, UK, pp. 743–751 (2003)
Identix Corp., 5600 Rowland Road, Minnetonka, MN 55343, http://www.identix.com
Dieckmann, U., Plankensteiner, P., Wagner, T.: SESAM: A biometric person identification system using sensor fusion. Pattern Recognition Letters 18, 827–833 (1997)
Yemez, Y., Kanak, A., Erzin, E., Tekalp, A.M.: Multimodal Speaker Identification with Audio-video Processing. In: Proc. of the Int’l Conf. on Image Processing, vol. 3, pp. 5–8 (2003)
Frischholz, R.W., Dieckmann, U.: BiolD: a multimodal biometric identification system. Computer 33, 64–68 (2000)
Sanderson, C., Paliwal, K.K.: Identity verification using speech and face information. Digital Signal Processing 14, 449–480 (2004)
Wark, T., Sridharan, S.: Adaptive Fusion of Speech and Lip Information for Robust Speaker Identification. Digital Signal Processing 11, 169–186 (2001)
Fox, N.A., Reilly, R.B.: Robust Multi-modal Person Identification with Tolerance of Facial Expression. In: The Proc. of the IEEE Int’l Conf. on Systems, Man and Cybernetics, vol. 1, pp. 580–585. The Hague, The Netherlands (2004)
Reynolds, D.A., Rose, R.C.: Robust Text-Independent Speaker Identification Using Gaussian Mixture Speaker Models. IEEE Tran. on Speech and Audio Processing 3, 72–83 (1995)
Young, S., Evermann, G., Kershaw, D., Moore, G., Odell, J., Ollason, D., Valtchev, V., Woodland, P.: The HTK Book (for HTK Version 3.1). Cambridge University Engineering Department: Microsoft Corporation (2001)
Lucey, S., Chen, T., Sridharan, S., Chandran, V.: Integration strategies for audio-visual speech processing: Applied to text dependent speaker recognition. To appear in the IEEE Transactions on Multimedia, vol. 7 (2005)
Potamianos, G., Graf, H., Cosatto, E.: An Image Transform Approach for HMM Based Automatic Lipreading. In: Proc. of the IEEE Int’l Conf. Image Processing, Chicago, vol. 3, pp. 173–177 (1998)
Matthews, I., Potamianos, G., Neti, C., Luettin, J.: A Comparison of Model and Transform-based Visual Features for Audio-Visual LVCSR. In: Proc. of the IEEE Int’l Conf. on Multimedia and Expo., pp. 825–828 (2001)
Fox, N.A., Gross, R., de Chazal, P., Cohn, J.F., Reilly, R.B.: Person Identification Using Automatic Integration of Speech, Lip, and Face Experts. In: ACM SIGMM workshop on Biometrics Methods and Applications, Berkley, CA, pp. 25–32 (2003)
Fox, N.A., O’Mullane, B.A., Reilly, R.B.: Audio-Visual Speaker Identification via Automatic Fusion using Reliability Estimates of both Modalities. In: Kanade, T., Jain, A., Ratha, N.K. (eds.) AVBPA 2005. LNCS, vol. 3546, pp. 787–796. Springer, Heidelberg (2005)
Vapnik, V.: The nature of statistical learning theory. Springer, Heidelberg (1995)
Messer, K., Kittler, J., Luettin, J., Maitre, G.: XM2VTSDB: The Extended M2VTS Database. In: The Proc. of the Second Int’l Conf. on Audio and Video-based Biometric Person Authentication, Washington D.C., pp. 72–77 (1999)
Belhumeur, P.N., Hespanha, J.P., Kriegman, D.J.: Eigenfaces vs. Fisherfaces: recognition using class specific linear projection. IEEE Transactions on Pattern Analysis and Machine Intelligence 19, 711–720 (1997)
Sirovich, L., Kirby, M.: Low-dimensional procedure for the characterization of human faces. Journal of the Optical Society of America A 4, 519–524 (1987)
Turk, M., Pentland, A.: Eigenfaces for Recognition. Journal of Cognitive Neuroscience 3, 71–86 (1991)
Li, Y., Gong, S., Liddell, H.: Support vector regression and classification based multi-view face detection and recognition. In: Proc. of the Fourth IEEE Int’l Conf. on Automatic Face and Gesture Recognition, pp. 300–305 (2000)
Lawrence, S., Giles, C.L., Tsoi, A.C., Back, A.D.: Face recognition: a convolutional neural-network approach. IEEE Tran. on Neural Networks 8, 98–113 (1997)
Lanitis, A., Taylor, C.J., Cootes, T.F.: Automatic interpretation and coding of face images using flexible models. IEEE Transactions on Pattern Analysis and Machine Intelligence 19, 743–756 (1997)
Yuille, A.: Deformable Templates for Face Recognition. Journal of Cognitive Neuroscience 3, 59–70 (1991)
Wiskott, L., Fellous, J.-M., Kuiger, N., von der Malsburg, C.: Face recognition by elastic bunch graph matching. IEEE Transactions on Pattern Analysis and Machine Intelligence 19, 775–779 (1997)
Penev, P., Atick, J.: Local feature analysis: A general statistical theory for object representation. Network: Computation in Neural Systems 7, 477–500 (1996)
Phillips, P.J., Grother, P., Michaels, P., Blackburn, D., Tabassi, E., Bone, M.: Face Recognition Vendor Test 2002, Evaluation report (2002)
Kittler, J., Hatef, M., Duin, R.P.W., Matas, J.: On Combining Classifiers. IEEE Transactions on Pattern Analysis and Machine Intelligence 20, 226–239 (1998)
Jain, A., Nandakumar, K., Ross, A.: Score Normalization in Multimodal Biometric Systems. To appear in Pattern Recognition (2005)
Heckmann, M., Berthommier, F., Kristian, K.: Noise Adaptive Stream Weighting in Audio-Visual Speech Recognition. EURASIP Journal on Applied Signal Processing 2002, 1260–1273 (2002)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2005 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Fox, N.A., Gross, R., Cohn, J.F., Reilly, R.B. (2005). Robust Automatic Human Identification Using Face, Mouth, and Acoustic Information. In: Zhao, W., Gong, S., Tang, X. (eds) Analysis and Modelling of Faces and Gestures. AMFG 2005. Lecture Notes in Computer Science, vol 3723. Springer, Berlin, Heidelberg. https://doi.org/10.1007/11564386_21
Download citation
DOI: https://doi.org/10.1007/11564386_21
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-29229-6
Online ISBN: 978-3-540-32074-6
eBook Packages: Computer ScienceComputer Science (R0)