
Abstract
Variability and noise in data-sets entries make hard the discover of important regularities among association rules in mining problems. The need exists for defining flexible and robust similarity measures between association rules. This paper introduces a new class of similarity functions, SF’s, that can be used to discover properties in the feature space X and to perform their grouping with standard clustering techniques. Properties of the proposed SF’s are investigated and experiments on simulated data-sets are also shown to evaluate the grouping performance.
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others

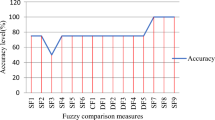
References
Khöler, W., Wallach, H.: Figural after-effects: an investigation of visual processes. In: Proc. Amer. phil. Soc., vol. 88, pp. 269–357 (1944)
Tenenbaum, J.B.: Rules and Similarity in Concept Learning. In: Solla, S.A., Leen, T.K., Müuller, K.-R. (eds.) Advances in Neural Information Processing Systems, vol. 12, pp. 59–65. MIT Press, Cambridge (2000)
Di Gesú, V., Roy, S.: Pictorial indexes and soft image distances. In: Pal, N.R., Sugeno, M. (eds.) AFSS 2002. LNCS, vol. 2275, pp. 200–215. Springer, Heidelberg (2002)
Di Gesú, V., Lo Bosco, G.: A Genetic Integrated Fuzzy Classifier. Pattern Recognition Letters 26(4), 411–420 (2005)
Pearce, M., Blake, D.J., Tinsley, J.M., Byth, B.C., Campbell, L., Monaco, A.P., Davies, K.E.: The utrophin and dystrophin genes share similarities in genomic structure. In: Human Molecular Genetics, vol. 2, pp. 1765–1772. Oxford Univ.Press, Oxford (1993)
Morgenstern, B.: DIALIGN 2: improvement of the segment-to-segment approach to multiple sequence alignment. Bioinformatics 15, 211–218 (1999)
Varré, J.S., Delahaye, J.P., Rivals, E.: Transformation Distances: a family of dissimilarity measures based on movement of segments. Bioinformatics 15, 194–202 (1999)
Agrawal, R., Imielinski, T., Swami, A.: Mining association rules between sets of items in large databases. In: Proceedings of the ACM SIGMOD International Conference on Management of Data, Washington D.C (1993)
Tsumoto, S., Hirano, S.: Visualization of Rules Similarity using Multidimensional Scaling. In: Proceedings of the Third IEEE International Conference on Data Mining (ICDM 2003) (2003)
Lent, B., Swami, A., Widom, J.: Clustering Association Rules. In: ICDE, pp. 220–231 (1997)
Gupta, G., Strehl, A., Ghosh, J.: Distance based clustering of association rules. In: Intelligent Engineering Systems Through Articial Neural Networks (Proceedings of ANNIE 1999), vol. 9, pp. 759–764. ASME Press (1999)
Friedman, J.H., Fisher, I.: Bump Hunting in High-Dimensional Data, Stanford University, Department of Statistics, Technical Report (1998)
Friedman, J.H., Popescu, B.E.: Importance Sampled Learning Ensamble, Stanford University, Department of Statistics, Technical Report (2003)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Copyright information
© 2006 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Di Gesù, V., Friedman, J.H. (2006). New Similarity Rules for Mining Data. In: Apolloni, B., Marinaro, M., Nicosia, G., Tagliaferri, R. (eds) Neural Nets. WIRN NAIS 2005 2005. Lecture Notes in Computer Science, vol 3931. Springer, Berlin, Heidelberg. https://doi.org/10.1007/11731177_26
Download citation
DOI: https://doi.org/10.1007/11731177_26
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-33183-4
Online ISBN: 978-3-540-33184-1
eBook Packages: Computer ScienceComputer Science (R0)