
Abstract
Dictionary-based biological concept extraction is still the state-of-the-art approach to large-scale biomedical literature annotation and indexing. The exact dictionary lookup is a very simple approach, but always achieves low extraction recall because a biological term often has many variants while a dictionary is impossible to collect all of them. We propose a generic extraction approach, referred to as approximate dictionary lookup, to cope with term variations and implement it as an extraction system called MaxMatcher. The basic idea of this approach is to capture the significant words instead of all words to a particular concept. The new approach dramatically improves the extraction recall while maintaining the precision. In a comparative study on GENIA corpus, the recall of the new approach reaches a 57% recall while the exact dictionary lookup only achieves a 26% recall.
This research work is supported in part from the NSF Career grant (NSF IIS 0448023). NSF CCF 0514679 and the research grant from PA Dept of Health.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others


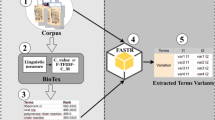
References
Chang, J.T., Schütze, H., Altman, R.B.: GAPSCORE: finding gene and protein names one word at a time. Bioinformatics 20(2), 216–225 (2004)
Chiang, J.-H., Yu, H.-C.: Literature extraction of protein functions using sentence pattern mining. IEEE Transactions on Knowledge and Data Engineering 17(8), 1088–1098 (2005)
Collier, N., Nobata, C., Tsujii, J.: Extracting the names of genes and gene products with a Hidden Markov Model. In: Proc. COLING 2000, pp. 201–207 (2000)
Fukuda, K., Tamura, A., Tsunoda, T., Takagi, T.: Toward information extraction: Identifying protein names from biological papers. In: Proceedings of Pacific Symposium on Biocomputing, Maui, Hawaii, January 1998, pp. 707–718 (1998)
Lesk, M.: Automatic Sense Disambiguation: How to Tell a Pine Cone from and Ice Cream Cone. In: Proceedings of the SIGDOC 1986 Conference, ACM Press, New York (1986)
Rindfleisch, T.C., Tanabe, L., Weinstein, J.N.: EDGAR: Extraction of Drugs, Genes and Relations from the Biomedical Literature. In: Proceedings of Pacific Symposium on Bioinformatics, Hawaii, USA, pp. 514–525 (2000)
Song, Y.-I., Kim, S.-B., Rim, H.-C.: Terminology Indexing and Reweighting methods for Biomedical Text Retrieval. In: Proceedings of the SIGIR 2004 Workshop on Search and Discovery in Bioinformatics, Sheffield, UK, ACM, New York (2004)
Subramaniam, L., Mukherjea, S., Kankar, P., Srivastava, B., Batra, V., Kamesam, P., Kothari, R.: Information Extraction from Biomedical Literature: Methodology, Evaluation and an Application. In: The Proceedings of the ACM Conference on Information and Knowledge Management, New Orleans, Louisiana (2003)
Tanabe, L., Wilbur, W.: Tagging gene and protein names in biomedical text. Bioinformatics 18(8), 1124–1132 (2002)
Zhou, G.-D., Zhang, J., Su, J., Shen, D., Tan, C.-L.: Recognizing Names in Biomedical Texts: A Machine Learning Approach. Bioinformatics 20(7), 1178–1190 (2004)
Zhou, X., Han, H., Chankai, I., Prestrud, A., Brooks, A.: Converting Semi-structured Clinical Medical Records into Information and Knowledge. In: Proceeding of The International Workshop on Biomedical Data Engineering (BMDE) in conjunction with the 21st International Conference on Data Engineering (ICDE), Tokyo, Japan, April 5-8 (2005)
Zhou, X., Hu, X., Zhang, X.: Using Concept-based Indexing to Improve Language Modeling Approach to Genomic IR. In: Lalmas, M., MacFarlane, A., Rüger, S.M., Tombros, A., Tsikrika, T., Yavlinsky, A. (eds.) ECIR 2006. LNCS, vol. 3936, Springer, Heidelberg (2006)
GENIA Corpus, http://www-tsujii.is.s.u-tokyo.ac.jp/GENIA/
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2006 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Zhou, X., Zhang, X., Hu, X. (2006). MaxMatcher: Biological Concept Extraction Using Approximate Dictionary Lookup. In: Yang, Q., Webb, G. (eds) PRICAI 2006: Trends in Artificial Intelligence. PRICAI 2006. Lecture Notes in Computer Science(), vol 4099. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-36668-3_150
Download citation
DOI: https://doi.org/10.1007/978-3-540-36668-3_150
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-36667-6
Online ISBN: 978-3-540-36668-3
eBook Packages: Computer ScienceComputer Science (R0)