
Abstract
We developed an Enterprise Contents Management System for an academic domain. The main feature of this system is its function for focusing searches in Web documents, utilizing human names and locations appearing in the documents as the search context. To realize this function, we adopted a standard text-mining algorithm for extracting proper nouns. We conducted an experimental study of this system against the existing digital contents of our university, and succeeded in efficiently obtaining suitable contents along the given contexts, which were obtained through previous searches. This experiment also suggested that our approach solves the general problem of finding an appropriate set of key words in a Web search. By performing this experiment, we confirmed that context mining is one of the most important technologies to be further developed in our effort to promote knowledge circulation through digital contents.
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others

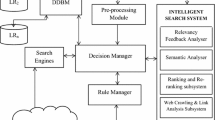

References
Kiyoki, Y.: A Metadatabase System for Semantic Image Search by a Mathematical Model of Meaning. ACM SIGMOD Record 23(4), 34–41 (1994)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2006 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Shimazu, K., Saito, I., Furukawa, K. (2006). Experimental Study of Semantic Contents Mining on Intra-university Enterprise Contents Management System for Knowledge Sharing. In: Mizoguchi, R., Shi, Z., Giunchiglia, F. (eds) The Semantic Web – ASWC 2006. ASWC 2006. Lecture Notes in Computer Science, vol 4185. Springer, Berlin, Heidelberg. https://doi.org/10.1007/11836025_71
Download citation
DOI: https://doi.org/10.1007/11836025_71
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-38329-1
Online ISBN: 978-3-540-38331-4
eBook Packages: Computer ScienceComputer Science (R0)