
Abstract
In using the ε-support vector regression (ε-SVR) algorithm, one has to decide on a suitable value of the insensitivity parameter ε. Smola et al. [6] determined its “optimal” choice based on maximizing the statistical efficiency of a location parameter estimator. While they successfully predicted a linear scaling between the optimal ε and the noise in the data, the value of the theoretically optimal ε does not have a close match with its experimentally observed counterpart. In this paper, we attempt to better explain the experimental results there, by analyzing a toy problem with a closer setting to the ε-SVR. Our resultant predicted choice of ε is much closer to the experimentally observed value, while still demonstrating a linear trend with the data noise.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others

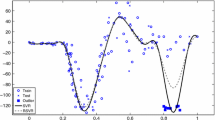
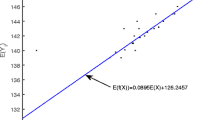
References
C. Goutte and L.K. Hansen. Regularization with a pruning prior. Neural Networks, 10(6):1053–1059, 1997.
L.K. Hansen and C.E. Rasmussen. Pruning from adaptive regularization. Neural Computation, 6:1223–1232, 1994.
D.J.C. MacKay. Bayesian interpolation. Neural Computation, 4(3):415–447, May 1992.
K.R. Müller, A.J. Smola, G. Rätsch, B. Schölkopf, J. Kohlmorgen, and V. Vapnik. Predicting time series with support vector machines. In Proceedings of the International Conference on Artificial Neural Networks, 1997.
B. Schölkopf and A.J. Smola. New support vector algorithms. NeuroCOLT2 Technical Report NC2-TR-1998-031, GMD FIRST, 1998.
A.J. Smola, N. Murata, B. Schölkopf, and K.-R. Müller. Asymptotically optimal choice of e-loss for support vector machines. In Proceedings of the International Conference on Artificial Neural Networks, 1998.
A.J. Smola and B. Schölkopf. A tutorial on support vector regression. NeuroCOLT2 Technical Report NC2-TR-1998-030, Royal Holloway College, 1998.
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2001 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Kwok, J.T. (2001). Linear Dependency between ε and the Input Noise in ε-Support Vector Regression. In: Dorffner, G., Bischof, H., Hornik, K. (eds) Artificial Neural Networks — ICANN 2001. ICANN 2001. Lecture Notes in Computer Science, vol 2130. Springer, Berlin, Heidelberg. https://doi.org/10.1007/3-540-44668-0_57
Download citation
DOI: https://doi.org/10.1007/3-540-44668-0_57
Published:
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-42486-4
Online ISBN: 978-3-540-44668-2
eBook Packages: Springer Book Archive