
Abstract
We observed that the coefficients of two important empirical statisti- cal laws of language - Zipf law and Heaps law - are different for different lan- guages, as we illustrate on English and Russian examples. This may have both theoretical and practical implications. On the one hand, the reasons for this may shed light on the nature of language. On the other hand, these two laws are im- portant in, say, full-text database design allowing predicting the index size.
The work was done under partial support of CONACyT, REDII, and SNI, Mexico. We thank Prof. R. Baeza-Yates, Prof. E. Atwell, and Prof. I. Bolshakov for useful discussion.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others
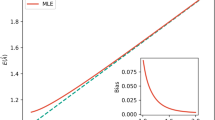

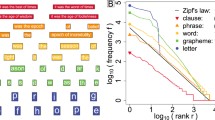
References
Manning, C. D. and Shutze, H. Foundations of statistical natural language processing. Cambridge, MA, The MIT press, 1999, 680 p.
Zipf, G. K. Human behavior and the principle of least effort. Cambridge, MA, Addison-Wesley, 1949.
Elliott J, Atwell, E, and Whyte B. Language identification in unknown signals. In CO-LING’2000, ACL and Morgan Kaufmann Publishers, 2000, p. 1021–1026.
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2001 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Gelbukh, A., Sidorov, G. (2001). Zipf and Heaps Laws’ Coefficients Depend on Language. In: Gelbukh, A. (eds) Computational Linguistics and Intelligent Text Processing. CICLing 2001. Lecture Notes in Computer Science, vol 2004. Springer, Berlin, Heidelberg. https://doi.org/10.1007/3-540-44686-9_33
Download citation
DOI: https://doi.org/10.1007/3-540-44686-9_33
Published:
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-41687-6
Online ISBN: 978-3-540-44686-6
eBook Packages: Springer Book Archive