
Abstract
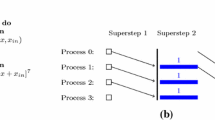
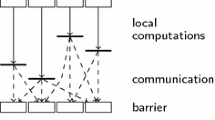
We prove an analogue of Brent’s lemma for BSP-like parallel machines featuring a hierarchical structure for both the interconnection and the memory. Specifically, for these machines we present a uniform scheme to simulate any computation designed for v processors on a v′-processor configuration with v′ ≤ v and the same overall memory size. For a wide class of computations the simulation exhibits optimal O (v/v′) slowdown. The simulation strategy aims at translating communication locality into temporal locality. As an important special case (v′= 1), our simulation can be employed to obtain efficient hierarchy-conscious sequential algorithms from efficient fine-grained ones.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others

References
Valiant, L.G.: A bridging model for parallel computation. Communications of the ACM 33 (1990)103–111
Dehne, F., Fabri, A., Rau-Chaplin, A.: Scalable parallel geometric algorithms for coarse grained multicomputers. International Journal on Computational Geometry 6 (1996) 379–400
Brent, R.P.: The parallel evaluation of general arithmetic expressions. Journal of the ACM 21 (1974)201–206
Vitter, J.S., Shriver, E.A.M.: Algorithms for parallel memory II: Hierarchical multilevel memories. Algorithmica 12 (1994) 148–169
Aggarwal, A., Alpern, B., Chandra, A.K., Snir, M.: A model for hierarchical memory. In: Proc. of the 19th ACM STOC. (1987) 305–314
Alpern, B., Carter, L., Ferrante, J.: Modeling parallel computers as memory hierarchies. In Programming Models for Massively Parallel Computers. IEEE Computer Society Press (1993)116–123
Hey wood, T., Ranka, S.: A practical hierarchical model of parallel computation. I. the model. Journal of Parallel and Distributed Computing 16 (1992) 212–232
Bilardi, G., Preparata, F.P.: Processor-time tradeoffs under bounded-speed message propagation: Part I, upper bounds. Theory of Computing Systems 30 (1997) 523–546
Bilardi, G., Preparata, F.P.: Processor-time tradeoffs under bounded-speed message propagation: Part II, lower bounds. Theory of Computing Systems 32 (1999) 531–559
Dehne, F., Dittrich, W., Hutchinson, D.: Efficient external memory algorithms by simulating coarse-grained parallel algorithms. In: Proc. of the 9th ACM SPAA. (1997) 106–115
Dehne, F., Dittrich, W., Hutchinson, D., Maheshwari, A.: Reducing I/O complexity by simulating coarse grained parallel algorithms. In: Proc. of the 13th IPPS. (1999) 14–20
Sibeyn, J., Kaufmann, M.: BSP-like external-memory computation. In: Proc. of the 3rd Italian Conference on Algorithms and Complexity. LNCS 1203 (1997) 229–240
De la Torre, P., Kruskal, C.P.: Submachine locality in the bulk synchronous setting. In: Proc. of EUROPAR 96. LNCS 1124 (1996) 352–358
Bilardi, G., Peserico, E.: A characterization of temporal locality and its portability across memory hierarchies. In: Proc. of ICALP 2001. LNCS 2076 (2001) 128–139
Bilardi, G., Pietracaprina, A., Pucci, G.: A quantitative measure of portability with application to bandwidth-latency models for parallel computing. In: Proc. of EUROPAR 99. LNCS 1685 (1999)543–551
Fantozzi, C., Pietracaprina, A., Pucci, G.: Implementing shared memory on clustered machines. In: Proc. of IPDPS 2001. (2001)
Bilardi, G., Fantozzi, C., Pietracaprina, A., Pucci, G.: On the effectiveness of D-BSP as a bridging model of parallel computation. In: Proc. of ICCS 2001. LNCS 2074 (2001) 579–588
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2002 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Fantozzi, C., Pietracaprina, A., Pucci, G. (2002). Seamless Integration of Parallelism and Memory Hierarchy. In: Widmayer, P., Eidenbenz, S., Triguero, F., Morales, R., Conejo, R., Hennessy, M. (eds) Automata, Languages and Programming. ICALP 2002. Lecture Notes in Computer Science, vol 2380. Springer, Berlin, Heidelberg. https://doi.org/10.1007/3-540-45465-9_73
Download citation
DOI: https://doi.org/10.1007/3-540-45465-9_73
Published:
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-43864-9
Online ISBN: 978-3-540-45465-6
eBook Packages: Springer Book Archive