
Abstract
Data mining comprises two subdisciplines. One of these is based on statistical modelling, though the large data sets associated with data mining lead to new problems for traditional modelling methodology. The other, which we term pattern detection, is a new science. Pattern detection is concerned with defining and detecting local anomalies within large data sets, and tools and methods have been developed in parallel by several applications communities, typically with no awareness of developments elsewhere. Most of the work to date has focussed on the development of practical methodology, with little attention being paid to the development of an underlying theoretical base to parallel the theoretical base developed over the last century to underpin modelling approaches. W e suggest that the time is now right for the development of a theoretical base, so that important common aspects of the work can be identified, so that key directions for future research can be characterised, and so that the various different application domains can benefit from the work in other areas. We attempt describe a unified approach to the subject, and also attempt to provide theoretical base on which future developments can stand.
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others


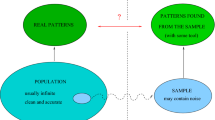
References
Grenander U.: General Pattern Theory: a Mathematical Study of Regular Structures. Clarendon Press, Oxford (1993)
Klösgen, W.: Subgroup patterns. In: Klösgen, W., Zytkow, J.M. (eds.): Handbook of data mining and knowledge discovery. Oxford University Press, New York (1999)
Friedman, J.H., Fisher, N.I.: Bump hunting in high-dimensional data. Statistics and Computing 9(2) (1999) 1–20
Hand D.J., Blunt G., Kelly M.G., Adams N.M.: Data mining for fun and profit. Statistical Science 15 (2000) 111–131
Hand D.J., Mannila H., Smyth P.: Principles of Data Mining. MIT Press (2001)
Chau T., Wong A.K.C.: Pattern discovery by residual analysis and recursive partitioning. IEEE Transactions on Knowledge and Data Engineering 11 (1999) 833–852
Adams N.M., Hand D.J., Till, R.J.: Mining for classes and patterns in behavioural data.Journal of the Operational Research Society 52 (2001) 1017–1024
Bolton R.J., Hand D.J.: Significance tests for patterns in continuous data. In: Proceedings of the IEEE International Conference on Data Mining, San Jose, CA. Springer-Verlag (2001)
Edwards R.D., Magee F.: Technical Analysis of Stock Trends. 7th edn. AMACOM, New York (1997)
Jobman D.R.: The Handbook of Technical Analysis. Probus Publishing Co. (1995)
Zembowicz R., Zytkow J.: From contingency tables to various forms of knowledge in databases. In: Fayyad, U.M., Piatetsky-Shapiro, G., Smyth, P., Uthurusamy, R. (eds.): Advances in Knowledge Discovery and Data Mining, Menlo Park, California, AAAI Press (1996) 329–349
Liu B., Hsu W., Ma Y.: Pruning and summarizing the discovered associations. In: Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, California, ACM Press (1999) 125–134
DuMouchel, W.: Bayesian data mining in large frequency tables, with an application to the FDA Spontaneous Reporting System. The American Statistician 53 (1999) 177–202
Jelinek F.: Statistical Methods for Speech Recognition. MIT Press, Cambridge, Massachusetts (1997)
Sinha S., Tompa M.: A statistical method for finding transcription factor binding sites.In: Proceedings of the Eighth International Conference on Intelligent Systems for Molecular Biology, La Jolla, CA, AAAI Press (2000) 344–354
Chudova, D., Smyth, P.: Unsupervised identification of sequential patterns under a Markov assumption. In: Proceedings of the KDD 2001 Workshop on Temporal Data Mining, San Francisco, CA (2001)
Durbin R., Eddy S., Krogh A., Mitchison G.: Biological Sequence Analysis. Cambridge University Press: Cambridge (1998)
Hand D.J., Bolton R.J.: Pattern detection in data mining. Technical Report, Department of Mathematics, Imperial College, London (2002)
Dong G., Li J.: Interestingness of discovered association rules in terms of neighbourhood-based unexpectedness.In: Proceedings of the Pacific Asia Conference on Knowledge Discovery in Databases (PAKDD), Lecture Notes in Computer Science, Vol.1394., Springer-Verlag, Berlin Heidelberg New York (1998) 72–86
Toivonen H., Klemettinen M., Ronkainen P., Hätönen, Mannila H.: Pruning and grouping discovered association rules.In: Mlnet Workshop on Statistics, Machine Learning, and Discovery in Databases, Crete, Greece, MLnet (1995) 47–52
Brin S., Motwani R., Ullma J.D., Tsur S.: Dynamic itemset counting and implication rules for market basket data.In: Proceedings of the ACM SIGMOD International Conference on Management of Data, Tucson, Arizona, ACM Press (1997) 255–264
Miller R.G.: Simultaneous Statistical Inference. 2nd ed. Springer-Verlag, New York (1981)
Pigeot I.: Basic concepts of multiple tests-a survey. Statistical Papers 41 (2000) 3–36
Benjamini Y., Hochberg Y.: Controlling the false discovery rate. Journal of the Royal Statistical Society, Series B 57 (1995) 289–300
Bolton R.J., Hand D.J., Adams, N.: Determining hit rate in pattern search. In: These Proceedings (2002)
Berry M.J.A., Lino. G.: Mastering data mining. The art and science of customer relationship management. Wiley, New York (2000)
Brunskill A.J.: Some sources of error in the coding of birth weight. American Journal of Public Health 80 (1990) 72–3
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2002 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Hand, D.J. (2002). Pattern Detection and Discovery. In: Hand, D.J., Adams, N.M., Bolton, R.J. (eds) Pattern Detection and Discovery. Lecture Notes in Computer Science(), vol 2447. Springer, Berlin, Heidelberg. https://doi.org/10.1007/3-540-45728-3_1
Download citation
DOI: https://doi.org/10.1007/3-540-45728-3_1
Published:
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-44148-9
Online ISBN: 978-3-540-45728-2
eBook Packages: Springer Book Archive