
Abstract
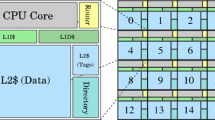
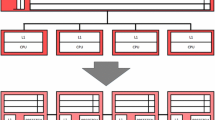
Large-scale multiprocessors suffer from long latencies for remote accesses. Caching is by far the most popular technique for hiding such delays. Caching not only hides the delay, but also decreases the network load. Cache-Only Memory Architectures (COMA), have no physically shared memory. Instead, all the memory resources are invested in caches, enabling in caches of the largest possible size. A datum has no home, and is moved by a protocol between the caches according to its usage. Furthermore, it might exist in multiple caches. Even though no shared memory exists in the traditional sense, the architecture provides a shared memory view to a processor, and hence also to the programmer. The simulation results of large programs running on up to 128 processors indicate that the COMA adapts well to existing shared memory programs. They also show that an application with a poor locality can benefit by adopting the COMA principle of no fixed home for data, resulting in a reduction of execution time by a factor three.
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others

References
P. Andersson. Performance Evaluation of Different Topologies for the Data Diffusion Machine. Final work for Undergraduate Studies, KTH, November 1991.
H. Burkhardt, S. Frank, B. Knobe, and J. Rothnie. Overview of the KSR1 Computer System. Technical Report KSR-TR-9202001, Kendall Square Research, Boston, 1992.
D.R. Cheriton, H.A. Goosen, and P. Machanick. Restructuring Parallel Simulation to Improve Cache Behavior in Shared-Memory Multiprocessor: A First Experience. Computer Science Department, Stanford, Internal paper, 1990.
D. Chaiken, J. Kubiatowicz, and A. Agarwal. LimitLESS Directories: A Scalable Cache Coherence Scheme. In Proceedings of the 4th Annual Architectural Support for Programming Languages and Operating Systems, 1991.
H. Davis, S. Goldschmidt, and J. Hennessy. Tango: A Multiprocessor Simulation and Tracing System. Tech. Report No CSL-TR-90-439, Stanford University, 1990.
J. R. Goodman. Using Cache Memory to Reduce Processor-Memory Traffic. In Proceedings of the 10th Annual International Symposium on Computer Architecture, pages 124–131, 1983.
J.R. Goodman and P.J. Woest. The Wisconsin Multicube: A New Large-Scale Cache-Coherent Multiprocessor. In Proceedings of the 15th Annual International Symposium on Computer Architecture, Honolulu, Hawaii, pages 422–431, 1988.
E. Hagersten. Toward Scalable Cache Only Memory Architectures. PhD thesis, Royal Institute of Technology, Stockholm/ Swedish Institute of Computer Science, 1992.
E. Hagersten, S. Haridi, and D.H.D. Warren. The Cache-Coherence Protocol of the Data Diffusion Machine. In M. Dubois and S. Thakkar, editors, Cache and Interconnect Architectures in Multiprocessors. Kluwer Academic Publisher, Norwell, Mass, 1990.
E. Hagersten, A. Landin, and S. Haridi. Multiprocessor Consistency and Synchronization Through Transient Cache States. In M. Dubois and S. Thakkar, editors, Scalable Shared-Memory Multiprocessors. Kluwer Academic Publisher, Norwell, Mass, June 1991.
E. Hagersten, A. Landin, and S. Haridi. DDM — A Cache-Only Memory Architecture. IEEE Computer, 25(9):44–54, Sept. 1992.
Homer. Odyssey. 800 BC.
M. Hill and A.J. Smith. Evaluating Associativity in CPU Caches. IEEE Transactions on Computers, 38(12):1612–1630, December 1989.
J. Larus. Abstract Execution: A Technique for Efficient Tracing Programs. Tech Report, Computer Science Department, University of Wisconsin at Madison, 1990.
D. Lenoski. The Design and Analysis of DASH: A Scalable Directory-Based Multiprocessor. PhD thesis, Stanford University, 1991.
A. Landin, E. Hagersten, and S. Haridi. Race-free Interconnection Networks and Multiprocessor Consistency. In Proceedings of the 18th Annual International Symposium on Computer Architecture, 1991.
D. Lenoski, J. Laudon, K. Gharachorloo, A. Gupta, and J. Hennessy. The Directory-Based Cache Coherence Protocol for the DASH Multiprocessor. In Proceedings of the 17th Annual International Symposium on Computer Architecture, pages 148–159, 1990.
M.S. Lam, E.E. Rothberg, and M.E. Wolf. The Cache Performance and Optimizations of Blocked Algorithms. In Proceedings of the 4th Annual Architectural Support for Programming Languages and Operating Systems, pages 63–74, 1991.
S. Raina and D.H.D Warren. Traffic Patterns in a Scalable Multiprocessor through Transputer Emulation. In International Hawaii Conference on System Science, 1991.
P. Stenström. A Survey of Cache Coherence for Multiprocessors. IEEE Computer, 23(6), June 1990.
J.S. Singh, W-D. Weber, and A. Gupta. SPLASH: Stanford Parallel Applications for Shared Memory. Stanford University, Report, April 1991.
D.H.D. Warren and S. Haridi. Data Diffusion Machine—a scalable shared virtual memory multiprocessor. In International Conference on Fifth Generation Computer Systems 1988. ICOT, 1988.
A. Wilson. Hierarchical cache/bus architecture for shared memory multiprocessor. Technical report ETR 86-006, Encore Computer Corporation, 1986.
Author information
Authors and Affiliations
Editor information
Rights and permissions
Copyright information
© 1993 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Hagersten, E., Grindal, M., Landin, A., Saulsbury, A., Werner, B., Haridi, S. (1993). Simulating the data diffusion machine. In: Bode, A., Reeve, M., Wolf, G. (eds) PARLE '93 Parallel Architectures and Languages Europe. PARLE 1993. Lecture Notes in Computer Science, vol 694. Springer, Berlin, Heidelberg. https://doi.org/10.1007/3-540-56891-3_3
Download citation
DOI: https://doi.org/10.1007/3-540-56891-3_3
Published:
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-56891-9
Online ISBN: 978-3-540-47779-2
eBook Packages: Springer Book Archive