
Abstract
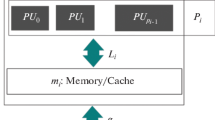
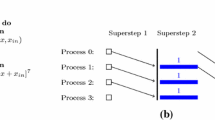
In this paper, we present deterministic parallel algorithms for the coarse grained multicomputer (CGM) and bulk-synchronous parallel computer (BSP) models which solve the following well known graph problems: (1) list ranking, (2) Euler tour construction, (3) computing the connected components and spanning forest, (4) lowest common ancestor preprocessing, (5) tree contraction and expression tree evaluation, (6) computing an ear decomposition or open ear decomposition, (7) 2-edge connectivity and biconnectivity (testing and component computation), and (8) cordai graph recognition (finding a perfect elimination ordering). The algorithms for Problems 1–7 require O(log p) communication rounds and linear sequential work per round. Our results for Problems 1 and 2 hold for arbitrary ratios \(\frac{n}{p}\), i.e. they are fully scalable, and for Problems 3–8 it is assumed that \(\frac{n}{p} \geqslant p^ \in ,{\mathbf{ }} \in {\mathbf{ }} > 0\), which is true for all commercially available multiprocessors. We view the algorithms presented as an important step towards the final goal of O(1) communication rounds. Note that, the number of communication rounds obtained in this paper is independent of n and grows only very slowly with respect to p. Hence, for most practical purposes, the number of communication rounds can be considered as constant. The result for Problem 1 is a considerable improvement over those previously reported. The algorithms for Problems 2–7 are the first practically relevant deterministic parallel algorithms for these problems to be used for commercially available coarse grained parallel machines.
Research partially supported by the Natural Sciences and Engineering Research Council of Canada, FAPESP (Brasil), CNPq (Brasil), PROTEM-2-TCPAC (Brasil), the Commission of the European Communities (ESPRIT Long Term Research Project 20244, ALCOM-IT), DFG-SFB 376 “Massive Parallelität” (Germany), and the Region Rhône-Alpes (France).
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others

References
S.G. Akl, Parallel Computation, Prentice Hall, 1997.
R.J. Anderson, and L. Snyder, “A Comparison of Shared and Nonshared Memory Models of Computation,” in Proc. of the IEEE, 79(4), pp. 480–487.
A. Bäumker and W. Dittrich, “Parallel Algorithms for Image Processing: Practical Algorithms with Experiments,” International Parallel Processing Symposium, IEEE Computer Society Press, 1996, pp. 429–433.
G.E. Blelloch, C.E. Leiserson, B.M. Maggs, C.G. Plaxton, “A Comparison of Sorting Algorithms for the Connection Machine CM-2.,” in Proc. ACM Symp. on Parallel Algorithms and Architectures, 1991, pp. 3–16.
E. Cáceres, F. Dehne, A. Ferreira, P. Flocchini, I. Rieping, A. Roncato, N. Santoro, and S.W. Song, “Efficient Parallel Graph Algorithms For Coarse Grained Multicomputers and BSP,”, on-line Postscript at http://www.scs.carleton.ca/scs/faculty/dehne.html.
R. Cole, “Parallel merge sort,” SIAM J. Comput., 17(4), 1988, pp. 770–785.
R. Cole and U. Vishkin, “Approximate parallel scheduling. Part I: The basic technique with applications to optimal parallel list ranking in logarithmic time”, SIAM Journal of Computing, Vol. 17, No. 1, 1988.
F. Dehne, A. Fabri, and A. Rau-Chaplin, “Scalable Parallel Geometric Algorithms for Coarse Grained Multicomputers,” in Proc. ACM 9th Annual Computational Geometry, pages 298–307, 1993.
F. Dehne, A. Fabri, and C. Kenyon, “Scalable and Architecture Independent Parallel Geometric Algorithms with High Probability Optimal Time,” in Proc. 6th IEEE Symposium on Parallel and Distributed Processing, pages 586–593, 1994.
F. Dehne, X. Deng, P. Dymond, A. Fabri, and A. A. Kokhar, “A randomized parallel 3D convex hull algorithm for coarse grained multicomputers,” in Proc. ACM Symposium on Parallel Algorithms and Architectures (SPAA'95), pp. 27–33, 1995.
F.Dehne, S.W. Song, “Randomized parallel list ranking for distributed memory multiprocessors,” in Proc. Second Asian Computing Science Conference, ASIAN'96, Singapore, Dec. 1996, Springer Lecture Notes in Computer Science 1179, pp. 1–10.
X. Deng, “A Convex Hull Algorithm for Coarse Grained Multiprocessors,” in Proc. 5th International Symposium on Algorithms and Computation, 1994.
X. Deng and P. Dymond, “Efficient Routing and Message Bounds for Optimal Parallel Algorithms,” in Proc. Int. Parallel Proc. Symp., 1995.
X. Deng and N. Gu, “Good Programming Style on Multiprocessors,” in Proc. IEEE Symposium on Parallel and Distributed Processing, 1994, pp. 538–543.
G.A. Dirac. “On rigid circuit graphs”. Abh. Math. Sem. Univ. Hamburg 25, 1961, pp. 71–76.
A. Ferreira, A. Rau-Chaplin, and S. Ubeda, “Scalable 2d convex hull and triangulation algorithms for coarse-grained multicomputers,” in Proceedings of the 7th IEEE Symposium on Parallel and Distributed Processing — SPDP'95, pages 561–569, San Antonio (USA), October 1995. IEEE Press.
A.V. Gerbessiotis and L.G. Valiant, “Direct Bulk-Synchronous Parallel Algorithms,” in Proc. 3rd Scandinavian Workshop on Algorithm Theory, Lecture Notes in Computer Science, Vol. 621, 1992, pp. 1–18.
M.T. Goodrich, “Communication efficient parallel sorting,” ACM Symposium on Theory of Computing (STOC), 1996.
Ja'Ja', An Introduction to Parallel Algorithms, Addison Wesley, 1992.
P. Klein. “Efficient Parallel Algorithms for Chordal Graphs”. Proc. 29th Symp. Found. of Comp. Sci., FOCS 1989, pp. 150–161.
P. Klein. “Parallel Algorithms for Chordal Graphs”. In Synthesis of parallel algorithms, J. H. Reif (editor). Morgan Kaufmann Publishers, 1993, pp. 341–407.
Hui Li, and K. C. Sevcik, “Parallel Sorting by Overpartitioning,” in Proc. ACM Symp. on Parallel Algorithms and Architectures, 1994, pp. 46–56.
Y. Maon, B. Schieber, U. Vishkin. “Parallel ear decomposition search (EDS) and st-numbering in graphs”. Theoretical Computer Science, vol. 47, 1986, pp. 277–298.
G.L. Miller, J.H. Reif, “Parallel tree contraction and its application,” IEEE Symp. on Foundations of Computer Science, 1985, pp. 478–489.
G. L. Miller, V. Ramachandran. “Efficient parallel ear decomposition with applications”, manuscript, MSRI, Berkeley, January 1986.
V. Ramachandran. “Parallel open ear decomposition with applications to graph biconnectivity and triconnectivity”, in [28], pp. 276–340.
M. Reid-Miller, “List ranking and list scan on the Cray C-90,” in Proc. ACM Symp. on Parallel Algorithms and Architectures, 1994, pp. 104–113.
J. H. Reif (editor), Synthesis of parallel algorithms, Morgan Kaufmann Publishers, 1993.
D.J. Rose, R.E. Tarjan, and G.S. Lueker. “Algorithmic Aspects of Vertex Elimination on Graphs”. SIAM J. Comp. 5, 1976, pp. 266–283.
Y. Shiloch, U. Vishkin, “An O(log n) parallel connectivity algorithm,” Journal of Algorithms, 3(1), pp. 57–67, 1983.
L. Snyder, “Type architectures, shared memory and the corollary of modest potential,” Annu. Rev. Comput. Sci. 1, 1986, pp. 289–317.
R.E. Tarjan, U. Vishkin, “An efficient parallel biconnectivity algorithm,” SIAM J. Comput., 14(4), 1985, pp. 862–874.
L. Valiant, “A bridging model for parallel computation,” Communications of the ACM, Vol. 33, No. 8, August 1990.
L.G. Valiant et al., “General Purpose Parallel Architectures,” Handbook of Theoretical Computer Science, Edited by J. van Leeuwen, MIT Press/Elsevier, 1990, pp.943–972.
H. Whitney. “Non-separable and planar graphs”. Trans. Amer. Math. Soc. 34, 1932, pp. 339–362.
Author information
Authors and Affiliations
Editor information
Rights and permissions
Copyright information
© 1997 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Cáceres, E. et al. (1997). Efficient parallel graph algorithms for coarse grained multicomputers and BSP. In: Degano, P., Gorrieri, R., Marchetti-Spaccamela, A. (eds) Automata, Languages and Programming. ICALP 1997. Lecture Notes in Computer Science, vol 1256. Springer, Berlin, Heidelberg. https://doi.org/10.1007/3-540-63165-8_195
Download citation
DOI: https://doi.org/10.1007/3-540-63165-8_195
Published:
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-63165-1
Online ISBN: 978-3-540-69194-5
eBook Packages: Springer Book Archive