
Abstract
It is evident from Chapter 1 that Shannon’s entropy occupies a central role in information-theoretic studies. Yet, the concept of information is so rich that perhaps there is no single definition that will be able to quantify information properly. Moreover, from an engineering perspective, one must estimate entropy from data which is a nontrivial matter. In this book we concentrate on Alfred Renyi’s seminal work on information theory to derive a set of estimators to apply entropy and divergence as cost functions in adaptation and learning. Therefore, we are mainly interested in computationally simple, nonparametric estimators that are continuous and differentiable in terms of the samples to yield well-behaved gradient algorithms that can optimize adaptive system parameters. There are many factors that affect the determination of the optimum of the performance surface, such as gradient noise, learning rates, and misadjustment, therefore in these types of applications the entropy estimator’s bias and variance are not as critical as, for instance, in coding or rate distortion theories. Moreover in adaptation one is only interested in the extremum (maximum or minimum) of the cost, with creates independence from its actual values, because only relative assessments are necessary. Following our nonparametric goals, what matters most in learning is to develop cost functions or divergence measures that can be derived directly from data without further assumptions to capture as much structure as possible within the data’s probability density function (PDF).
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

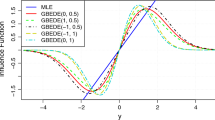
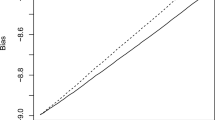
References
Aczél J., Daróczy Z., On measures of information and their characterizations,Mathematics in Science and Engineering, vol. 115, Academic Press, New York, 1975.
Basu A., Lindsay B. Minimum disparity estimation in the continuous case: Efficiency, distributions, robustness,Ann. Inst.Statist. Math.., 46:683–705, 1994.
Bengtsson I., Zyczkowski K.,Geometry of quantum states, Cambridge, UK, 2006.
Bhattacharyya A., On a measure of divergence between two statistical populations defined by their probability distributions,Bul. Calcutta Math. Soc., 35:99–109, 1943.
Bourbaki N.,Topological Vector Spaces, Springer, 1987
Campbell L., A coding theorem and Renyi’s entropy,Inf. Control, 8:423–429, 1965
Chernoff H., A measure of asymptotic efficiency of tests for a hypothesis based on a sum of observations.Ann. Math. Stat., 23:493–507, 1952.
Cover T., Thomas J.,Elements of Information Theory, Wiley, New York, 1991
Erdogmus D., Information theoretic learning: Renyi’s entropy and its applications to adaptive systems training, Ph.D. Dissertation, University of Florida, Gainesville, 2002.
Erdogmus D., Hild K., Principe J., Beyond second order statistics for learning: a pairwise interaction model for entropy estimation,J. Natural Comput., 1(1):85–108, 2003.
Fine S., Scheinberg K., Cristianini N., Shawe-Taylor J., Williamson B., Efficient SVM training using low-rank kernel representations,J. Mach. Learn. Res., 2:243–264, 2001.
Golub G., Van Loan C.,Matrix Computation, 3rd ed. The Johns Hopkins University Press, Baltimore, Maryland, 1996.
Gonzalez T., Clustering to minimize the maximum intercluster distance.Theor. Comput. Sci., 38:293–306, 1985.
Grassberger, P., I. Procaccia, Characterization of strange attractors,Phys. Rev. Lett., 50(5):346–349, 1983.
Greengard L., Rokhlin V., A fast algorithm for particle simulations.J. Comput. Phys., 73(2):325–348, 1987.
Greengard L., Strain J., The fast Gauss transform.SIAM J. Sci. Statist. Comput., 12(1):79–94, 1991.
Hart, P., Moment distributions in economics: an exposition,J. Royal. Statis Soc. Ser. A, 138:423–434, 1975.
Havrda J., Charvat, F., Quantification methods of classification processes: concept of structural a entropy,Kybernetica 3:30, 1967.
Horn D., Gottlieb A., Algorithm for data clustering in pattern recognition problems based on quantum mechanics,Phys. Rev. Lett., 88(1):018702, 2002.
Jizba P., Toshihico T., The world according to Renyi: Thermodynamics of multifractal systems,Ann. Phys., 312:17–59, 2004.
Kapur J.,Measures of Information and their Applications, Wiley Eastern Ltd, New Delhi, 1994.
Kawai A, Fukushige T., $105/Gflops astrophysical N-body simulation with reconfigurable add-in card and hierarchical tree algorithm, inProc. SC2006, IEEE Computer Society Press, Tampa FL, 2006.
Kolmogorov A., Sur la notion de la moyenne,Atti della R. Accademia Nazionale dei Lincei, 12:388–391, 1930.
Kullback S.,Information theory and statistics, Dover, Mineola, NY, 1959.
Lutwak E., Yang D., Zhang G., Cramér–Rao and moment-entropy inequalities for Renyi entropy and generalized Fisher information,IEEE Trans. Info. Theor.., 51(2):473–479, 2005.
Nagumo M., Uber eine klasse von mittelwerte,Japanese J. Math.., 7:71, 1930.
Pardo L.,Statistical Inference based on Divergence measures, Chapman & Hall, Boca raton, FL, 2006.
Parzen E., On the estimation of a probability density function and the mode,Ann. Math. Statist.., 33:1065–1067, 1962.
Principe, J., Xu D., Fisher J., Information theoretic learning, in unsupervised adaptive filtering, Simon Haykin (Ed.), pp. 265–319, Wiley, New York, 2000.
Rao S., Unsupervised Learning: An Information Theoretic Learning Approach, Ph.D. thesis, University of Florida, Gainesville, 2008.
Renyi A., On measures of entropy and information,Proc. of the 4th Berkeley Symp. Math. Statist. Prob. 1960, vol. I, Berkeley University Press, pp. 457, 1961.
Renyi A., Probability Theory, North-Holland, University Amsterdam, 1970.
Renyi A. (Ed.),Selected Papers of Alfred Renyi, vol. 2, Akademia Kiado, Budapest, 1976.
Renyi A., Some fundamental questions about information theory, in Renyi, A. (Ed.),Selected Papers of Alfred Renyi, vol. 2, Akademia Kiado, Budapest, 1976.
Rudin W.Principles of Mathematical Analysis. McGraw-Hill, New York, 1976.
Seth S., and Principe J., On speeding up computation in information theoretic learning, inProc. IJCNN 2009, Atlanta, GA, 2009.
Silverman B.,Density Estimation for Statistics and Data Analysis, Chapman and Hall, London, 1986.
Song, K., Renyi information, log likelihood and an intrinsic distribution measure,J. of Stat. Plan. and Inference, 93: 51–69, 2001.
Torkkola K., Feature extraction by non-parametric mutual information maximization,J. Mach. Learn. Res.., 3:1415–1438, 2003.
Tsallis C., Possible generalization of Boltzmann Gibbs statistics,J. Stat. Phys.., 52:479, 1988.
von Neumann, J.,Mathematical Foundations of Quantum Mechanics, Princeton University Press, Princeton, NJ, 1955.
Xu D., Energy, Entropy and Information Potential for Neural Computation, PhD Dissertation, University of Florida, Gainesville, 1999
Yang C., Duraiswami R., Gumerov N., Davis L., Improved fast Gauss transform and efficient kernel density estimation. InProc. ICCV 2003, pages 464–471, 2003.
Author information
Authors and Affiliations
Rights and permissions
Copyright information
© 2010 Springer Science+Business Media, LLC
About this chapter
Cite this chapter
Xu, D., Erdogmuns, D. (2010). Renyi’s Entropy, Divergence and Their Nonparametric Estimators. In: Information Theoretic Learning. Information Science and Statistics. Springer, New York, NY. https://doi.org/10.1007/978-1-4419-1570-2_2
Download citation
DOI: https://doi.org/10.1007/978-1-4419-1570-2_2
Published:
Publisher Name: Springer, New York, NY
Print ISBN: 978-1-4419-1569-6
Online ISBN: 978-1-4419-1570-2
eBook Packages: Computer ScienceComputer Science (R0)