
Abstract
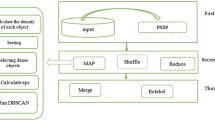
Until now, a lot of clustering algorithms for differential privacy (DP) have been proposed. Practically, there still exist difficulties in implementing these algorithms in a big data platform. In this paper, we proposed a clustering algorithm for privacy preservation on MapReduce. The algorithm is implemented from two aspects. Firstly, the optimized Canopy algorithm is implemented to get the optimal number of clusters and the initial center points on MapReduce. Secondly, the DP K-means algorithm is implemented to get the final clusters on MapReduce. As a result, the proposed algorithm can generate the optimal clustering number that is same with the standard classified data set and can achieve better accuracy of the clusters with the suitable privacy budget \(\varepsilon \).
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Blum, A., Dwork, C., Mcsherry, F., et al.: Practical privacy: the SuLQ framework. In: Proceedings of the 24th ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, pp. 128–138. ACM, New Work (2005)
Dwork, C.: Differential privacy. In: Bugliesi, M., Preneel, B., Sassone, V., Wegener, I. (eds.) ICALP 2006. LNCS, vol. 4052, pp. 1–12. Springer, Heidelberg (2006). https://doi.org/10.1007/11787006_1
Dwork, C.: A firm foundation for private data analysis. Commun. ACM 54(1), 86–95 (2011)
Hartigan, J.A., Wong, M.A.: A K-means clustering algorithm. J. Roy. Stat. Soc. Ser. C. Appl. Stat. 28(1), 100–108 (1979)
Hatamlou, A., Abdullah, S., Nezamabadi-pour, H.: A combined approach for clustering bases on K-means and gravitational search algorithm. Swarm. Evol. Comput. 6, 47–52 (2012)
Hua, Y.H., Miao, K.X.: Understanding Big Data Processing and Programming, 1st edn. China Machine Press, Beijing (2014)
Li, Y., Hao, Z.F., Wen, W., Xie, G.Q.: Research on differential privacy preserving K-means clustering. Comput. Sci. 40(3), 287–290 (2013)
Mccallum, A., Nigam, K., Ungar, L.H.: Efficient clustering of high-dimensional data sets with application to reference matching. In: Proceedings of the 6th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 169–178. ACM, New York (2000)
Mendes, R., Vilela, J.P.: Privacy-preserving data mining: methods, metrics, and applications. IEEE Access 5(99), 10562–10582 (2017)
Nissim, K., Raskhodnikova, S., Smith, A.: Smooth sensitivity and sampling in private data analysis. In: Proceedings of the 39th Annual ACM Symposium on Theory of Computing, pp. 75–84. ACM, New York (2007)
Reddy, D., Jana, P.K.: Initialization for K-means clustering using Voronoi diagram. Procedia Technol. 4(4), 395–400 (2012)
Shang, T., Zhao, Z., Guan, Z., Liu, J.: A DP canopy K-means algorithm for privacy preservation of hadoop platform. In: Wen, S., Wu, W., Castiglione, A. (eds.) CSS 2017. LNCS, vol. 10581, pp. 189–198. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-69471-9_14
Xiong, P., Zhu, T.Q., Wang, X.F.: A survey on differential privacy and applications. Chin. J. Comput. 37(1), 101–122 (2014)
Zhang, W.J., Gu, X.F., Chen, L.F.: A K-means initial clustering center selection algorithm based on mean-standard deviation. J. Remote Sens. 10(5), 715–721 (2006)
Acknowledgment
Project supported by the National Key Research and Development Program of China (No. 2016YFC1000307) and the National Natural Science Foundation of China (No. 61571024) for valuable helps.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Zhao, Z., Shang, T., Liu, J., Guan, Z. (2018). Clustering Algorithm for Privacy Preservation on MapReduce. In: Sun, X., Pan, Z., Bertino, E. (eds) Cloud Computing and Security. ICCCS 2018. Lecture Notes in Computer Science(), vol 11064. Springer, Cham. https://doi.org/10.1007/978-3-030-00009-7_56
Download citation
DOI: https://doi.org/10.1007/978-3-030-00009-7_56
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-00008-0
Online ISBN: 978-3-030-00009-7
eBook Packages: Computer ScienceComputer Science (R0)