
Abstract
Choroidal neovascularization (CNV), caused by new blood vessels in the choroid growing through the Bruch’s membrane, is an important manifestation of terminal age-related macular degeneration (AMD). Automated CNV detection in three-dimensional (3D) spectral-domain optical coherence tomography (SD-OCT) images is still a huge challenge. This paper presents an automated CNV detection method based on object tracking strategy for time series SD-OCT volumetric images. In our proposed scheme, experts only need to manually calibrate CNV lesion area for the first moment of each patient, and then the CNV of the following moments will be automatically detected. In order to fully represent space consistency of CNV, a 3D-histogram of oriented gradient (3D-HOG) feature is constructed for the generation of random forest model. Finally, the similarity between training and testing samples is measured for model updating. The experiments on 258 SD-OCT cubes from 12 eyes in 12 patients with CNV demonstrate that our results have a high correlation with the manual segmentations. The average of correlation coefficients and overlap ratio for CNV projection area are 0.907 and 83.96%, respectively.
This work was supported by the National Natural Science Foundation of China (61671242, 61701192, 61701222, 61473310), Suzhou Industral Innovation Project (SS201759).
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
- Choroidal neovascularization
- 3D-HOG features
- Image segmentation
- Spectral-domain optical coherence tomography
1 Introduction
CNV is characterized by the abnormal growth of blood vessels in the choroid layer in age-related macular degeneration (AMD) [1]. Characterization of CNV is fundamental in the diagnosis of diabetic retinopathy because it could help clinicians to objectively predict the progression of CNV or make a treatment decision. However, this characterization relies mainly on the accurate detection and their properties, such as area and length. Apart from the challenging and time-consuming, CNV owns more complicated structure characteristics [2]. Thus, effectively automated CNV detection and segmentation are able to assist CNV clinical diagnosis vastly.
Currently, the optical coherence tomography angiography (OCTA) is a novel evolving imaging technology which utilizes motion contrast to visualize retinal and choroidal vessels. It can provide more distinct vascular network that is used to visualize and detect CNV [3]. Additionally, several CNV segmentation methods only target at fluorescein angiography (FA) image sequences [4]. For the quantitative analysis of CNV in OCTA, Jia et al. [5] manually calculated the CNV area and flow index from two-dimensional (2D) maximum projection outer retina CNV angiogram in AMD patients. Recently, for the purpose of calculating the vessel length of CNV network in OCTA, they developed a level set method to segment neovascular vessels within detected CNV membrane, and a skeleton algorithm was applied to determine vessel centerlines [6]. Zhu et al. [7] proposed a CNV prediction algorithm based on reaction diffusion model in longitudinal OCT images. Xi et al. [8] learned local similarity prior embedding active contour model for CNV segmentation in OCT images.
Most of CNV quantitative evaluation methods above are two-dimensional (2D) and only suitable for FA [4] or OCTA [5]. In this paper, we presented an automated CNV detection method based on three-dimensional histogram of oriented gradient (3D-HOG) feature in time series spectral-domain optical coherence tomography (SD-OCT) volumetric images. In summary, our contributions in this paper can be highlighted as: (1) A CNV detection method based on object tracking strategy was proposed for time series SD-OCT images. (2) A 3D-HOG feature was constructed for CNV detection in SD-OCT volumetric images. (3) Aiming at the characteristic changes of CNV along with drug treatment and time variation, a model updating method is proposed.
2 Method
2.1 Method Overview
The whole framework of our method is shown in Fig. 1. In the stage of image pre-processing, noise removal and layer segmentation are performed on each B-scan. Consequently, we divide patches into positive and negative samples and extract 3D-HOG features. Finally, random forest is utilized to train a prediction model. In the testing phase, we first measure the similarity between the testing and training images. If they are similar, we extract 3D-HOG feature and use the trained model to directly predict the location of CNV. Otherwise, the detection results from the previous moments are utilized to update the training samples, and then to obtain the final detection results.
2.2 Preprocessing
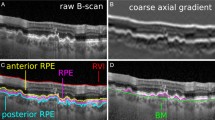
To reduce the influence of speckle noise on the layer segmentation, this paper uses bilateral filter to remove noise. Then, we segment internal limiting membrane (ILM) and Bruch membrane (BM) layers based on gradual intensity distance to restrict the region of interest (ROI). Figure 2 shows the preprocessing, where the red and green lines are the ILM and BM layers (Fig. 2(c)), respectively. The blue rectangle in Fig. 2(d) represents the ROI, which is the minimum rectangle containing ILM and BM.

Framework of the proposed method.

Preprocessing for one normal and one CNV (second row) SD-OCT images.
2.3 Classification of positive and negative samples
Longitudinal data from 12 eyes in 12 patients with CNV at the First Affiliated Hospital with Nanjing Medical University were included in this paper. Experts manually draw CNV region as the ground truth. The ROIs of each B-scan are extracted to construct training data using sliding window method, and then we can extract 3D HOG features from the ROIs. Experiment has proved 64 \(\times \) 128 (width height) is the best image size for extracting HOG feature [9]. Therefore, we resize all the preprocessed images to 512 \(\times \) 128. For the z (azimuthal) direction, the slide window size is 1, which means that three continuous B-scans are selected.
As shown in Fig. 3(a), the size of sample is 64 \(\times \) 128 \(\times \) 3. For the x direction, the optimum step size is 16. Tiny step size will lead to high similarity between training samples, which will reduce the efficiency and increase time cost. On the contrary, it will affect the accuracy of detection. If the training sample is within the red manual division line we mark it as the positive sample. In contrast, we mark it as the negative sample (Fig. 3(b)). However, when the sliding window contains positive and negative samples (the yellow rectangle in Fig. 3(b)), we mark it as the positive sample if the number of columns containing CNV exceeds the half width of the sliding window, the negative sample or not. Based on the above procedures, we will get 3712 training samples for each SD-OCT volumetric image.

Construct training samples.
2.4 3D-HOG Feature Extraction
HOG descriptors provide a dense overlapping description of image regions [9]. The main idea of HOG feature is that the appearance and shape of local objects can be well described by the directional density distribution of gradients or edges. In this paper, we extend the traditional HOG feature from 2D to 3D by considering adjacent pixel information more effectively. The basic process is as follows:
-
(1)
Gamma space standardization. We firstly normalize the input image with Gamma standardization to adjust image contrast, reduce the influence of local shadows, and suppress the noise interference.
$$\begin{aligned} I(x,y,z)=I(x,y,z)^{Gamma} \end{aligned}$$(1)where Gamma is set to 0.5 here.
-
(2)
Image gradient calculation. Then the gradient magnitude is computed by:
$$\begin{aligned} G(x,y,z)=\sqrt{G_x(x,y,z)^2+G_y(x,y,z)^2+G_z(x,y,z)^2} \end{aligned}$$(2)
where \(G_x(x,y,z)\), \(G_y(x,y,z)\) and \(G_z(x,y,z)\) represent the image gradients along the x, y and z directions, respectively.
In 2D images, we only need to calculate the gradient direction in x-y plan. However, the gradient direction in x-z plan can also be calculated in 3D images. Considering computational complexity, gradient information in y-z plan is ignored. Then the gradient direction in the x-y and x-z plans are calculated as
-
(3)
Construction of gradient orientation histogram. Firstly, the gradient direction of each cell will be divided into 9 directions in x-y and x-z plans. Hence, there are 81 bins of histogram to count the gradient information in each cell. In this way, each pixel in the cell is graded in the histogram with a weighted projection (mapped to a fixed angular range) to obtain a gradient histogram, that is, an 81-dimensional eigenvector corresponding to the cell. The gradient magnitude is used as the weight of the projection. Then, the feature vectors of all cells in a block are concatenated to obtain the 3D-HOG feature. Finally, 3D-HOG features from all overlapping blocks are concatenated to the ultimate features for random forest classification.
2.5 Similarity measurement and model update
For each patient, the CNV characteristic will change along with the medication and time. Therefore, it is necessary to update the trained random forest model. Since OCT volumetric images at different moments will shift, we use en face projection images rather than B-scans to measure the similarity between the training and testing cubes.
Because the brightness, contrast, and structure of the projection image will change along the diversification of CNV, structural similarity index (SSIM) [10] is suitable for similarity measure between projection images. If the similarity between the current and first projection images is larger than the average similarity, we extract 3D-HOG feature and use the trained model to directly predict the location of CNV. Otherwise, the detection results from the previous moment are utilized to construct the training samples in which the corresponding predict probability in the detection result is over 90%. Then the previous trained model is refined with new training data to obtain the final CNV detection results.
2.6 Post-processing
The width of sliding window (Fig. 3(a)) will influence the accuracy of CNV detection. If we reduce the width, the detection accuracy will also be reduced due to high similarity between training samples. To make the detected CNV boundary smoother, the tradeoff between the CNV boundaries of two adjacent cubes is taken as the new CNV boundary of the current cube.
3 Experiments
Our algorithm was implemented in Matlab and ran on a 4.0 GHz Pentium 4 PC with 16.0 GB memory. We obtained 258 SD-OCT volumetric image datasets from 12 eyes in 12 patients with CNV to quantitatively test our algorithm. The SD-OCT cubes are 512 (lateral) \(\times \) 1024 (axial) \(\times \) 128 (azimuthal) corresponding to a 6 \(\times \) 6 \(\times \) 2 mm\(^3\) volume centered at the retinal macular region generated with a Cirrus HD-OCT device.
We quantitatively compared our automated results with the manual segmentations drawn by expert readers. Five metrics were used to assess the CNV area differences: correlation coefficient (cc), p-value of Mann-Whitney U-test (p-value), overlap ratio (Overlap), overestimated ratio (Overest) and underestimated ratio (Underest).
3.1 Quantitative Evaluation
Table 1 shows the agreement of CNV projection area in the axial direction between our automated result and the ground truth. From Table 1, we can observe that the correlation coefficient (0.9070) and overlap ratio (83.96%) are high for CNV projection area. The low p-value (<0.05) indicates that there are significant differences in the segmented CNV projection area between our automated method and the manual rater. The overestimated ratio (8.95%) and underestimated ratio (7.10%) are similar.
3.2 Qualitative Analysis
Figure 4 shows the CNV detection results in B-scan where the green transparent areas represent our automated detection results and the red lines are the manual segmentation. Due to the complex characteristic of CNV, it is difficult for the CNV detection. However, our proposed method is effective to deal with many difficulties, such as (1) non-uniform reflectivity within CNV ((a)(c)(d)(l)), (2) blur and obscure CNV up boundary ((c)(i)(k)(l)), (3) invisible CNV down boundary (a)–(e) and (g)–(l), (4) influence of other retinal diseases (cystoid edema (c), hyper-reflective foci (g), and neurosensory retinal detachment (h) (j)), and (5) the great difference of CNV sizes ((e)(j)).

CNV detection results and each image represents different example of patients.

CNV projection images with result of our method and expert manually for the right eye of a patient for 25 imaging dates between 2013 and 2015.
Because our detection precision is high and robust in B-scan images, we can also obtain a relatively high segmentation precision in their projection images. Figure 5 shows the CNV projection images collected at 25 time points of one patient in two years, corresponding to Fig. 4(a). In Fig. 5, the red lines are the manual segmentation and the green lines are our segmentation in the projection images. It can be seen from Fig. 5 that our automated CNV detection is similar with the manual segmentation.
4 Conclusions
In this paper, we presented an automated CNV detection method based on object tracking strategy for time series SD-OCT volumetric images. In order to fully represent space consistency of CNV in SD-OCT volumetric images, 3D-HOG features are conducted for CNV classification. We update random forest models persistently to make our model more robust, which can improve the accuracy of detection. According to the CNV detection results in B-scans, quantitative evaluation is performed on OCT projection images. The experiments on 258 SD-OCT volumetric images with CNV demonstrate that our method is effective and can achieve a high correlation with the manual segmentations.
References
Jager, R.D., Mieler, W.F., Miller, J.W.: Age-related macular degeneration. New Engl. J. Med. 358(24), 2606–2617 (2008)
Donoso, L.A., Kim, D., Frost, A., Callahan, A., Hageman, G.: The role of inflammation in the pathogenesis of age-related macular degeneration. Surv. Ophthalmol. 51(2), 137–152 (2006)
Miyata, M., Ooto, S., Hata, M.: Detection of myopic choroidal neovascularization using optical coherence tomography angiography. Am. J. Ophthalmol. 165, 108–114 (2016)
Abdelmoula, W.M., Shah, S.M., Fahmy, A.S.: Segmentation of choroidal neovascularization in fundus fluorescein angiograms. IEEE Trans. Biomed. Eng. 60(5), 1439–1445 (2013)
Jia, Y., Bailey, S.T., Wilson, D.J.: Quantitative optical coherence tomography angiography of choroidal neovascularization in age-related macular degeneration. Ophthalmology 121(7), 1435–1444 (2014)
Gao, S.S., et al.: Quantificaton of choroidal neovascularization vessel length using optical coherence tomography angiography. J. Biomed. Opt. 21(7), 76010 (2016)
Zhu, S., Shi, F., Xiang, D.: Choroid neovascularization growth prediction with treatment based on reaction-diffusion model in 3-D OCT images. IEEE J. Biomed. Health Inform. 21(6), 1667 (2017)
Xi, X., Meng, X., et al.: Learned local similarity prior embedded active contour model for choroidal neovascularization segmentation in optical coherence tomography images. SCIENCE CHINA Inf. Sci. (2017). https://doi.org/10.1007/s11432-017-9247-8
Dalal, N., Triggs, B.: Histograms of oriented gradients for human detection. In: IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp. 1063–6919 (2005)
Wang, Z., Bovik, A.C.: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13(4), 1057–7149 (2004)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Li, Y., Niu, S., Ji, Z., Fan, W., Yuan, S., Chen, Q. (2018). Automated Choroidal Neovascularization Detection for Time Series SD-OCT Images. In: Frangi, A., Schnabel, J., Davatzikos, C., Alberola-López, C., Fichtinger, G. (eds) Medical Image Computing and Computer Assisted Intervention – MICCAI 2018. MICCAI 2018. Lecture Notes in Computer Science(), vol 11071. Springer, Cham. https://doi.org/10.1007/978-3-030-00934-2_43
Download citation
DOI: https://doi.org/10.1007/978-3-030-00934-2_43
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-00933-5
Online ISBN: 978-3-030-00934-2
eBook Packages: Computer ScienceComputer Science (R0)