
Abstract
In this paper, we propose a multi-view clustering algorithm based on fast search and find of density peaks. We combined the original clustering algorithm with co-training to handle multi-view data and implement self-adapting cluster center selecting through cluster fusion. Based on the assumption that a point would be assigned to the same cluster in all views, we search for the clustering result that agree across the views by continually modifying one view with the clustering from another view. We demonstrate the efficacy of the proposed algorithm on several test cases.
This work was partially supported by the National Natural Science Foundation of China (61876136), China Postdoctoral Science Foundation (2018M633585), Natural Science Basic Research Plan in Shaanxi Province of China (2018JQ6060), the Doctoral Starting up Foundation of Northwest A&F University (2452015302), and Students Innovation Training Project of China (201710712064).
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Unlabeled data exist in nature widely, and labeling each sample in a big-scale data in multi-view learning costs a lot of time and work. Thus, we focus on unsupervised learning. Clustering algorithms are widely used in unsupervised learning, which aim to partition elements based on their similarity. Many clustering algorithms have been proposed such as K-means clustering algorithm seeking to minimize the average squared distance between points in the same cluster [1], spectral clustering [2] dividing the graph up into several subgraphs exploiting the properties of the Laplacian of the original graph and Density-Based Spatial Clustering of Applications with Noise (DBSAN) [3] viewing clusters as high-density areas. In 2014, a clustering algorithm based on fast search and find of density (DPC) was proposed in [4], which was formed by the idea that cluster centers are characterized by a higher density than their neighbors and by a relatively large distance from points with higher densities. The DPC algorithm has attracted attention by its good performance on automatically excluding outliers and recognizing clusters irrespective of their shape and of the dimensionality of the space.
In real world, we have access to lots of features from single object, and limited information can be obtained through an individual view. Hence, we attempt to obtain more information through observing an object in multiple views. For examples, we can take a photo of an object in different angles or even by different sensors. Different views make up for the lack of information in single-view learning. Motivated by this factor, many multi-view learning methods have been proposed. In [5], Laplacian support vector machines (SVMs) [6] is extended from supervised learning to multi-view semi-supervised learning. Canonical Correlational Analysis (CCA) [7,8,9], Bilinear Model (BLM) [10] and Partial Least Squares (PLS) [8, 11, 12] are popular unsupervised approaches in multi-view learning [13]. In 2015, Later Multi-View Linear Discriminant Analysis (MLDA) [14] was proposed through combining CCA and Linear Discriminant Analysis (LDA) [15]. Linear Discriminant Analysis is a single-view learning method seeking an optimal linear transformation that maps data into a subspace. Multi-View Intact Space Learning (MISL) proposed in [16] aims to find a space from several views, which assumes that different views are generated from an intact view. Differing from many multi-view approaches, MISL focuses on the insufficiency of each view. However, we do not pay attention to whether each view is sufficient or not, but focus on how to combine the information of multiple views. Therefore, we focus on co-training [17] which is widely used in multi-view learning.
Recently, many clustering methods are applied in multi-view learning. In 2013, a multi-view method, which combines spectral clustering with co-training is proposed in [18]. In 2015, a Co-Spectral Clustering Based Density Peak is proposed in [19], which replaces k-means in spectral clustering with DPC and combines the exteneded spectral clustering with co-training. In 2016, a Multi-View Subspace Clustering is proposed in [20], which performs subspace clustering on each view simultaneously, meanwhile guarantees the consistence of the clustering structure among different views.
Some clustering methods demand preset number of clusters such as k-means and spectral clustering. In this paper, we extend the cluster centers selection of the orignal DPC with cluster fusion to implement self-adaptive cluster centers selection which remains unsolved in [4]. We propose an adjusted co-training framework for DPC which varies weights of views according to views’ aggregation. Combining the extended DPC and adjusted co-training, the proposed approach is runed without sensitive parameters.
2 Related Work
2.1 Co-training
Co-training [17] was proposed for problems of semi-supervised learning setting, in which we have access to both labeled and unlabeled samples in two distinct views. It considered the problem of using a small set of labeled samples to boost the performance of unsupervised learning. It has its basis on two assumptions: each view is sufficient for classification independently, and the views are conditionally independent given the labels.
Given the labeled training set L and the unlabeled training set U, here we outline the process of co-training:
-
Create a pool \(U'\) of examples with u examples chosen randomly from U
-
Loop for k iterations:
-
Use L to train a classifier \(h_1\) that considers only the \(x_1\) portion of x
-
Use L to train a classifier \(h_2\) that considers only the \(x_2\) portion of x
-
Allow \(h_1\) to label p positive and n negative examples from \(U'\)
-
Allow \(h_2\) to label p positive and n negative examples from \(U'\)
-
Add these self-labeled examples to L
-
Randomly choose \(2p+2n\) examples from U to replenish \(U'\).
-
2.2 Clustering by Fast Search and Find of Density Peaks
Given the distance between data points, density peaks clustering (DPC) [4] chooses data points surrounded by neighbours with lower local density as cluster centers. For data point \(p_i\), two quantities \(\rho _i\) and \(\delta _i\) need to be calculated. \(\rho _i\) indicates the number of points that distances between point \(p_i\) and these points are less than the cutoff distance \(d_c\). \(\delta _i\) indicates the distance between point \(p_i\) and its nearest neighbour with higher local density, and \(\delta _i\) is defined as
One can choose \(d_c\) so that the average number of neighbors is around \(1\%\) to \(2\%\) of the total number of points in the data set.
For the point with highest density, \(\delta _i\) is defined as \(\delta _i = \max _j(d_{ij})\). Expect the point with highest density, each point and its nearest neighbour with higher local density are assigned to the same cluster temporarily.
Data points with high \(\rho \) and high \(\delta \) or with high \(\gamma \) defined as \(\gamma =\rho \delta \) are selected as cluster center.
To exlude outliers, for each cluster, the algorithm finds a border region, defined as the set of points assigned to that cluster but being within a distance \(d_c\) from data points belonging to other clusters. Then the algorithm finds the point with highest density within its border region for each cluster. Its density is denoted by \(\rho _b\). A point is considered part of the cluster core (robust assignation), if their density is higher than \(\rho _b\) of its cluster. Otherwise, it is considered part of the cluster halo (suitable to be considered as noise).
3 A Co-training Approach for Multi-view Density Peak Clustering
3.1 Adjusted Co-training Framework
The main idea of the standard co-training is training several classifiers through results producted by themselves. Thus, in the proposed approach, views are modified with their clustering results. In a modified view \(v'_a\), distances between two data points belonging to the same cluster in another view \(v_b\) are supposed to decrease according to the aggregation of \(v_b\) denoted by \(A_b\), and other distances maintain unchanged. Specifically, given the adjacency matrix \(D_b\) of view \(v_b\), we first obtain labels \(L_b\) by clustering and calculate modification weight matrix \(W_b\) defined as:
In Eq. (3), \(Size(L_{bi})\) denotes the size of the cluster which includes data point \(p_i\) in view \(v_b\).
The modified view \(v'_a\) is defined as
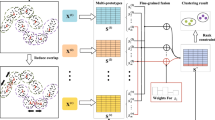
Similar with the standard co-training, we modify each view with another view’s clustering result through some iterations. The modification will be ended when all views’ clustering results are the same or \(max_iA_i\) is less than a preset threshold T. The brief process of the proposed approach is shown in Fig. 1.

The brief process of the proposed approach
3.2 Cluster Center Selection and Cluster Fusion
A problem remains unsolved in the orignal DPC is how to select cluster centers automatically and accurately. To help select cluster centers, the author introduced a quantity \(\gamma \) defined as \(\gamma _i = \delta _i\rho _i\) for each data point i, whose value is enormously large for cluster centers [4]. Since we attempt to produce the clustering result through iterations in our adjusted co-training framework, DPC doesn’t have to perform perfectly in cluster centers selection during each iteration. Thus, we simply select points whose \(\gamma \) is higher than the average value of \(\gamma \) as temporary cluster centers to ensure that the expected cluster centers are included in the set of chosen points. After this step, we fuse some excessive clusters based on the border region of cluster center defined in [4].
The boder region of a cluster is originally used to find the cluster halo which can be regarded as outliers [4]. We discard its function for excluding outliers, and instead we apply it in merging excessive clusters produced by the cluster centers selection. In the process of calculating border densities, for each cluster \(C_i\) in we record its border cluster denoted by \(BC_{i}\) within whose border region the border density \(\rho _{Bi}\) is obtained, where \(\rho _{Bi}\) and \(BC_{i}\) are defined as
where \(CL_x\) denotes the cluster which data point \(p_x\) belongs to, and \(\rho _x\) denotes the local density of data point \(p_x\).
If the local density of the cluster center in cluster \(C_i\) is less than \(\rho _{Bi}\), cluster \(C_i\) will be mergerd with \(BC_{i}\) and the center of new cluster will be the orignal center of \(BC_{i}\).
4 Experiment
4.1 Experiment Setup
To demonstrate the efficiency of the proposed approach, we compare our co-trained density peak clustering approach with following baselines:
-
Best Single View (BSV) Selecting most informative view where clustering result achieving the highest scores.
-
Feature Concatenation (FC) Concatenating the features from each view, and then running a clustering algorithm on the joint features.
-
Kernel Addition (KA) Combining different kernels by adding them. As suggested in [21], this seemly simple approach often leads to near optimal results as compared to more sophisticated approaches for classification. It can be noted that kernel addition reduces to feature concatenation for the special case of linear kernel. In general, kernel addition is same as concatenation of features in the Reproducing Kernel Hilbert Space [18].
-
Kernel Product (element-wise) (KP) Multiplying the corresponding entries of kernels and applying a clustering algorithm on the resultant matrix. For the special case of Gaussian kernel, element-wise kernel product would be same as simple feature concatenation if both kernels use same width parameter \(\sigma \) [18].
In the section of experiments, we compare performances of DPC with Density Peak Spectral Clustering (DPSC) proposed in [19] combined with above baselines and co-training. DPSC replaces k-means in spectral clustering with DPC to determine number of clusters without preset parameters. The self-adaptive cluster selection is the advantage of the proposed approach as well. Therefore, we compare the proposed approach with DPSC and co-trained DPC instead of spectral clustering or other clustering algorithms requiring sensitive parameters.
4.2 Dataset
-
Synthetic Dataset
Our synthetic data consists of 3 views. Each view consists of 2000 data points in two-dimension space (\(x_0, x_1, x_{2} \in \mathbb {R}^2\)) and four central points \((p_0=(1, 1), p_1=(-1,-1), p_2=(1, -1), p_3=(-1, 1))\). The distribution of data points follows
$$\begin{aligned} ||x_i - p_{(i \ mod \ 4)}||_{\infty } \leqslant r\end{aligned}$$(7)where r is a given range for generating data points randomly. We define the true label of data point \(x_i\) as \(L_i = i \ mod \ 4\). We evaluate the proposed approach with a synthesis dataset containing three views as shown in Fig. 2.
-
MNIST Handwritten Digit
One real-world dataset is taken from the handwritten digits (0–9) data from the MNIST dataset (Modified National Institute of Standards and Technology database). The dataset is consisted of 1000 examples. Digit images are described in two ways: Histogram of Oriented Gradient (HOG) [22] (view-1) and binaryzation (view-2). This dataset will exam the proposed approach’s performance on features extracted with different methods from the same samples.
-
IXMAS Actions Dataset
The IXMAS dataset contains recordings of 14 actions from different angles. Images from each angle are regarded as samples in one view. HOG is applied for describing features in views of different angles. This dataset will exam the proposed approach’s performance on samples taken from different angles.

Three images showing distribution of data points in three views. The range r in view (A) is 0.8; in view (B) is 1.0; and in view (C) is 1.2. Each shape or colour represents one expected cluster.
4.3 Results
The clustering results are evaluated with adjusted rand score (adj-RI) [23] and normalized mutual information score (NMI) [24].
Table 1 shows the clustering result on synthetic dataset. Our approach outperforms all baselines by a significant margin. The feature concatenation is the second best one among remaining baselines. Compared with DPSC, the proposed approach integrates information in three views and avoids degradation of performance.
Table 2 shows the clustering result on MINST digit dataset. Our approach outperforms all the baselines in adj-RI score and its NMI score is close to the best one. Performances of kernel addition and kernel product are close to that of the best single view.
Table 3 shows the clustering results on IXMAS action dataset. On this dataset, our approach outperforms all baselines by a significant margin. Except the co-trained DPC, other baselines combined with DPC perform worse than the Best Single View combined with DPC do.

adj-RI scores in different views vs number of iterations of co-trained DPC for Synthetic dataset

adj-RI scores in different views vs number of iterations of co-trained DPC for MNIST dataset

adj-RI scores in different views vs number of iteration of co-trained DPC for IXMAS action dataset
Figures 3, 4 and 5 show adj-RI scores in different datasets with increase of the number of iterations. The proposed approach complete clustering by few steps of iteration.
5 Conculusion
We extend the original density peak clustering method from single-view learning to multi-view learning with the idea of co-training. In our adjusted co-training framework, distances between data points belonging to the same cluster decrease during iteration according to the clustering result for another view. In our adjusted density peak clustering method, cluster centers are selected simply, and then excessive clusters produced by the simple cluster center selection are merged according to densities of points in the border area of clusters. Based on these extensions, the co-trained density peak clustering method outperforms other baselines in experiments. The proposed approach has the ability to integrating information in views and avoiding degradation of performance through few steps of iteration.
References
Arthur, D., Vassilvitskii, S.: K-means++: the advantages of careful seeding. In: Eighteenth ACM-SIAM Symposium on Discrete Algorithms. Society for Industrial and Applied Mathematics, pp. 1027–1035 (2007)
Shi, J., Malik, J.: Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 22(8), 888–905 (2000)
Ester, M., Kriegel, H.P., Xu, X.: A density-based algorithm for discovering clusters in large spatial databases with noise. In: International Conference on Knowledge Discovery and Data Mining, pp. 226–231. AAAI Press (1996)
Rodriguez, A., Laio, A.: Machine learning. Clustering by fast search and find of density peaks. Science 344(6191), 1492 (2014)
Sun, S.: Multi-view laplacian support vector machines. Appl. Intell. 41(4), 209–222 (2013)
Cortes, C., Vapnik, V.: Support-vector networks. Mach. Learn. 20(3), 273–297 (1995)
Cohen, J., Cohen, P., West, S.G., et al.: Applied Multiple Regression/Correlation Analysis for the Behavioral Sciences, 3rd edn, pp. 227–229. L. Erlbaum Associates (2003)
Shawe-Taylor, J., Cristianini, N.: Kernel methods for pattern analysis. Publ. Am. Stat. Assoc. 101(476), 1730–1730 (2004)
Hardoon, D.R., Szedmak, S., Shawe-Taylor, J.: Canonical correlation analysis: an overview with application to learning methods. Neural Comput. 16(12), 2639–2664 (2014)
Tenenbaum, J.B., Freeman, W.T.: Separating style and content with bilinear models. Neural Comput. 12(6), 1247–1283 (2014)
Rosipal, R., Krämer, N.: Overview and recent advances in partial least squares. In: Saunders, C., Grobelnik, M., Gunn, S., Shawe-Taylor, J. (eds.) SLSFS 2005. LNCS, vol. 3940, pp. 34–51. Springer, Heidelberg (2006). https://doi.org/10.1007/11752790_2
Sharma, A., Jacobs, D.W.: Bypassing synthesis: PLS for face recognition with pose, low-resolution and sketch. In: Computer Vision and Pattern Recognition, pp. 593–600. IEEE (2011)
Sharma, A., Kumar, A., Daume, H., et al.: Generalized multiview analysis: a discriminative latent space. In: IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, pp. 2160–2167 (2012)
Sun, S., Xie, X., Yang, M.: Multiview uncorrelated discriminant analysis. IEEE Trans. Cybern. 46(12), 3272 (2016)
Hotelling, H.: Relations Between Two Sets of Variates. Breakthroughs in Statistics, pp. 321–377. Springer, New York (1992)
Xu, C., Tao, D., Xu, C.: Multi-view intact space learning. IEEE Trans. Pattern Anal. Mach. Intell. 37(12), 2531–2544 (2015)
Blum, A., Mitchell, T.: Combining labeled and unlabeled data with co-training. In: Eleventh Conference on Computational Learning Theory, pp. 92–100. ACM (1998)
Kumar, A., Daumé III, H.: A co-training approach for multi-view spectral clustering. In: International Conference on International Conference on Machine Learning, pp. 393–400. Omnipress (2011)
Li, Y., Liu, W., Wang, Y., et al.: Co-spectral clustering based density peak. In: IEEE International Conference on Communication Technology, pp. 925–929. IEEE (2015)
Gao, H., Nie, F., Li, X., et al.: Multi-view subspace clustering. In: IEEE International Conference on Computer Vision, pp. 4238–4246. IEEE (2016)
Cortes, C., Mohri, M., Rostamizadeh, A.: Learning non-linear combinations of kernels. In: International Conference on Neural Information Processing Systems, pp. 396–404. Curran Associates Inc. (2009)
Dalal, N., Triggs, B.: Histograms of oriented gradients for human detection. In: IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2005, pp. 886–893. IEEE (2005)
Manning, C.D., Raghavan, P., Schütze, H.: An introduction to information retrieval. J. Am. Soc. Inf. Sci. Technol. 61(4), 852–853 (2008)
Hubert, L., Arabie, P.: Comparing partitions. J. Classif. 2(1), 193–218 (1985). Assortative pairing and life history strategy - a cross-cultural study. Hum. Nat. 20, 317–330
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Ling, Y., He, J., Ren, S., Pan, H., He, G. (2018). A Co-training Approach for Multi-view Density Peak Clustering. In: Lai, JH., et al. Pattern Recognition and Computer Vision. PRCV 2018. Lecture Notes in Computer Science(), vol 11258. Springer, Cham. https://doi.org/10.1007/978-3-030-03338-5_42
Download citation
DOI: https://doi.org/10.1007/978-3-030-03338-5_42
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-03337-8
Online ISBN: 978-3-030-03338-5
eBook Packages: Computer ScienceComputer Science (R0)