
Abstract
The spatial pyramid matching has been widely adopted for scene recognition and image retrieval. It splits the image into sub-regions and counts the local features within the sub-region. However, it has not captured the spatial relationship between the local features located in the sub-region. This paper proposes to construct the multi-scale attributed graphs which involve the vocabulary label to characterize the spatial structure of the local features at different scales. We compute the distances of any two attributed graph corresponding to the image grids and find the optimal matching to aggregate. Then we poll the distances of graphs at different scales to build the kernel for image classification. We conduct our method on the Caltech 101, Caltech 256, Scene Categories, and Six Actions datasets and compare with five methods. The experiment results demonstrate that our method can provide a good accuracy for image categorization.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Image Categorization, which has a quite wide range of applications, such as face recognition, scene classification and pedestrian tracking, is a challenging task in computer vision. It is undoubtedly of great theoretical and practical significance to study the robust and accurate image classification algorithm. How to find the correct classification of an unlabel image from a large scale image database has been a research spot for several decades and numerous methods have been developed.
The approach bag of words (BoW) has been widely used in image classification [1,2,3]. BoW based methods use image visual features (e.g. SIFT [4]) to build a dictionary of visual words and computing a histogram for each image for recognition. However, the BoW method does not contain spatial and structural information of the image. In this respect, one limitation of the BoW approach is that it can not encode the spatial distribution of visual words within an image.
To characterize the spatial layout of the local features, the spatial pyramid [5] divides the image into different regions at different levels and computes a BoW for each region, and the final image descriptor as the concatenation of the histograms from all regions. For the same reason, latent pyramidal regions (LPR) [6] are trained by combining the benefits of spatial pyramid representation using nonlinear feature coding and latent SVM. Yang et al. [7] proposed the linear spatial pyramid matching using sparse coding (ScSPM) and Wang et al. [8] proposed the locality-constrained linear coding method to improve the ScSPM method by adding the local constraints. In order to obtain the vector based on BoW with certain invariance, Cao etc. presented two methods of linear BoW and annular BoW to improve the robustness to some degree [9].
In recent years, graph matching algorithms have been applied to solve image classification [10, 11]. One of the most popular methods to perform graph matching is the graph edit distance [12,13,14,15]. Jouili et al. [12] used Hungarian method with a vector which encodes vertices and edges of the same representation to compute a suboptimal cost of edit distance. Zhou et al. [16] proposed a deformable graph matching method to match graphics that are subject to global rigid and non rigid geometric constraints. The bag of graph [13] and bag of visual graphs [14] combines the spatial locations of interest points and their labels defined in terms of the traditional visual-word codebook to define a set of connected graphs, then defines descriptors for image classification based on graph local structures. Lee et al. [17] generalizes the formula of hyper-graph matching to cover arbitrary sequence of feature relations and obtained a new graph matching algorithm by reinterpreting the concept of random walk on hyper-graph. Zhang et al. [18] proposed a saliency-guided graphlet selection algorithm for image categorization. In the multi-graph-view respects, Wu et al. [19] proposes a multi-graph-view model to represent and classify complex targets. Mousavi et al. [20] generated a graph pyramid based on the selected graph summarization algorithm to provide the required information for classification.
The matching node embeddings [21] is presented as the graph kernel based on the pyramid match kernel. It restricts the matchings only between vertices that share same labels. However, the interest points have not assigned labels. Thus this method is not competent for the graph based on interest points without tags. Our approach takes this into account that applying the weighted Hungarian method to find the most similar graph, that can be a good way to overcome this problem.
In this paper, we propose to construct a multi-scale attributed graph model for image classification, where the spatial structure relation between the interest points of the image at different scales are captured. The graphs are pruned to give more efficient structure information for categorization. At each scale, the distance of the attributed graphs are calculated to find the optimal matched graphs. Final the distances are accumulated with weight to built the kernel for SVM.
The rest of the paper is organized as follows. We first present the proposed multi-scale attributed graph for image representation in Sect. 2, and then compute the distance between the attributed graphs corresponding to image grids in Sect. 3. In Sect. 4, the kernel for classification is built by accumulating the distances between the matched graphs. The experimental results on four public datasets are presented and discussed in Sect. 5. Finally, conclusions are drawn in Sect. 6.
2 The Multi-scale Attributed Graph Model for Image Representation
To describe the structure and spatial features of the images at different scales, we define multi-scale attributed graphs \(G^l =(V^l,E^l,A^l)\), where l denotes the scale or level factor, the nodes set \(V^l=\{v_1,v_2,\cdots ,v_n\}\) corresponds to the image feature points \(F = \{f_1,f_2,\cdots ,f_n\}\), which obtained by extracting the SIFT features of the images in our experiment, the edges set \(E^l = \{e_{ij}\}\) are constructed by delaunay triangulation, and \(A^l\) denotes the attribute of the node set \(V^l\), for a node \(v_i\), its attribute is defined as,
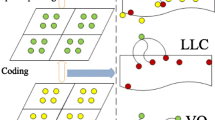
where \(av_i\) is the label of node \(v_i\) which corresponds to the feature point \(f_i\). In terms of the widely used bag of words, we assign a vocabulary label to each node, \(degree(v_i)\) is the degree of the node \(v_i\), \(\{ae_i\}\) is the attribute set of all the edges which are adjacent to the node \(v_i\). There exist many methods for constructing graph based on images, such as k-nearest neighbor graph [22] and deep learning hash [23]. We use the delaunay triangulation method here for its stability and efficiency. To characterize the image structure at different scale, we split an image into a sequence of grids at each scale \(l\in (0,\ldots ,L)\), such that a total of \(S =2^{sl}\) image grids are obtained, where s is the dimension of the images. For each grid, we construct an attributed graph on the feature points, as shown in Fig. 1. These graphs form the multi-scale structure representation of an image.

The multi-scale attributed graph extraction from an cougar body.

The graph model for an image in Caltech 101. (a) The delaunay triangulation graph on the feature points; (b) Our graph constructed after pruning.
Since the images have not been preprocessed as segmentation or salient analysis, the images usually have the objective, background and noise. The multi-scale attributed graphs built from the original image will contains the additional structure information which is not related to the objective. For example, Fig. 2(a) shows the attributed graph constructed from an image in Caltech 101 at level 0. We can see that one point in the background in the lower right corner of the image is connected to feature of the aircraft. Furthermore, the feature points of the tail and the head of the aircraft are also connected. However, these edges are useless to reflect the structure of the aircraft and not helpful for image classification. Therefore, we consider to prune the graph, specifically, remove the edges which connect the points with long distance and short distance, as shown in Fig. 2(b). Let m be the value of the longest edge of the constructed graphs for one image, we delete the edges longer than \(\beta m\) and shorter than \(\alpha m\), where \(0<\alpha<\beta <1\). In the experiments, we choose \(\alpha = 0.1\) and \(\beta = 0.6\). Because experiments show that the short edges can not improve the classification but increase the computational complexity. We can effectively avoid the error structure with the complicated background, and focus on the local structure of the image by pruning edges and constructing the multi-scale attributed graphs. Moreover, the graph after pruning becomes sparse and computational efficient.
3 Graph Distance Based on Node Attributes
To match the multi-scale structure between two images, we compute the distance between the multi-scale graphs constructed from two images. The graph distance is obtained based on the node attributes using the heterogeneous euclidean overlap metric (HEOM) [12], which can handle the numeric and symbolic attributes of nodes. The distance of two nodes \(v_i\) and \(v_j\) is defined as their distance between the node attribute \(\mathbf {A}_i\) and \(\mathbf {A}_j\),
where N refers the length of the longest node signature of \(v_i\) and \(v_j\), and

where
and range is used to normalize the distance of the numeric attribute.
The distance between an attributed graph corresponding to the grid i in image \(I_1\) and an attributed graph corresponding to the grid j in image \(I_2\) at the same scale is computed as [12]:
where \(\bar{M}\) is the optimum graph matching cost of two attributed graphs \(G_1(i)\) and \(G_2(j)\), the \(\mathbf {M}\) is the distance matrix of two attributed graphs that each element of matrix corresponds to the distance between a vertex of graph \(G_1(i)\) and a vertex of graph \(G_2(j)\). The node matching between two attributed graphs \(G_1(i)\) and \(G_2(i)\) is carry out by the hungarian method. Then the optimum graph matching cost \(\bar{M}\) is computed by calculating the sum of the distance between two correspondence points. \(|\mathbf {M}|\) is a normalization constant that refers to the number of matched vertices. \(|G_1(i)|\) is the number of vertices in graph \(G_1(i)\). The Eq. (5) represents the matching cost normalized by the matching size, and is effected by the sizes of the two graphs.
4 Multi-scale Attributed Graph Kernel Computation
When the distances between any two attributed graphs corresponding to two grids in the different images are computed at a scale, for convenience, we use the efficient hungarian method to find the optimal matched graphs correspond to two different images and get c distances \(\{D_1, D_2, \cdots , D_c\}\) between the matched graphs. Inspired by the concept of graph kernel [24], which compares and counts the common subgraphs between two graphs. We compute a kernel by accumulating the distances between the matched graphs from two images, i.e.
where \(w_i\) is the reciprocal of the total number of vertices of the matched graphs corresponding to two grids.
The final kernel is then the sum of all the level kernels,
where the weight associated with level l is set to \(\frac{1}{2^{L-l}}\), which are inversely proportional to the number of the grids which increases as the level increases. The multi-scale attributed graph match kernel we built is a positive semidefinite kernel matrix which can be used by SVM for classification. We summarize the proposed image categorization model in Algorithm 1.

5 Experiments
In this section, we conduct comparative experiments on four benchmark datasets: Caltech 101 [27], Caltech 256 [28], Scene Categories [29], and Six Actions [30]. The performance of the proposed multi-scale attributed graph match kernel is evaluated and compared with traditional bag of words (BoW) [3], the spatial pyramids (SP) [5], BoVG-SP [14], fine-grained dictionary learning (FDL) [25] and word spatial arrangement (WSA) [32] respectively. The experimental results are summarized and analyzed. All experiments are implemented in Matlab 8.6 and executed on a Intel Core i7-6700 3.4 GHz CPU with 16 GB of memory and no effort made to optimize algorithm speed.
5.1 Dataset
The Scene Categories dataset is composed of fifteen scene categories. Each category has 200 to 400 images, and average image size is \(300\times 250\) pixels. In experiments, we randomly select 40 images of each class for training and 20 images per class for testing to evaluate the impact of different approaches in image categories.
The Caltech 101 dataset consists of a total of 9146 images, split between 101 different object categories. Each object category contains between 40 and 800 images on average. Each image is about \(300\times 200\) pixels in dimension. We use SIFT detector, a codebook of size 300 and 30 images per class for training and the rest for testing.
The Caltech 256 dataset is collected in a similar manner of Caltech 101 which split into a set of 256 object categories containing a total of 30607 images.
The Six Actions dataset collect about 2400 images in total for six action queries, each action class contains about 400 images and the size of each class are \(200\times 200\) pixels.
5.2 Baseline
This paper adopts the method in [3] as the baseline approach. The 128-D SIFT descriptors are used for feature extraction and the experiment uses K-means method to get the codebook of size 300. With the increase of scale l, the effect of characterizing image structure is better, but when the scale is larger than 3, the number of grids is too large, the complexity of the algorithm is greatly increased but the improvement of accuracy is limited. Thus the scale level of the multi-scale attributed graph is set to \(L=3\). The LIB-SVM [31] is employed for classification training.
5.3 Results
Table 1 shows the classification results on four datasets. As we can see our method and FDL produce the higher classification accuracy than other methods. Our method achieves highest recognition rates on Scene Categories, Caltech 101 and Six Actions dataset. Taking Scene Categories for example, it is clear that the classification accuracy of MsAG is 79.67%, which is higher than others.

Confusion matrix for the Scene Category dataset. Average classification rates for individual classes are listed along the diagonal. The entry in the \(i^{th}\) row and \(j^{th}\) column is the percentage of images from class i that were misidentified as class j.

Classification accuracy for different training set sizes on Caltech 101.

Performance of BoW, SP, BoVG-SP, FDL, WSA and MsAG on Six Actions.

Different codebook size on the performance of BoW, SP, BoVG-SP and MsAG on (a) Six Actions, (b) Scene Category.

Partial results of image classification on the Six Actions database.
Figure 3 shows a confusion matrix between the fifteen scene categories, confusion occurs between the classes like kitchen, bedroom, living room, and also between some natural classes, such as coast and open country. The curves in Fig. 4 shows the classification accuracy for different training set sizes on Caltech 101. We partition the dataset into train images (5, 10, 15, 20, 25 and 30 images per class) and test images (limit the number of test images to 30 per class). The figure shows that the accuracy increases with the training size. Our approach has always been better than the other methods when the number increases from 5 to 30. In Fig. 5, the experimental results on Six Actions show that the results of our method is consistent with that on Caltech 101.
Then we compare the classification accuracies of each method for different codebook sizes, the FDL and WSA methods do not involve codebook, so we do not compare them in this experiment. As shown on Fig. 6, classification accuracy increases when the codebook size increases from 200 to 500 and remains obtain similar results on both datasets when the size is lager than 300. Comparatively, considering the time consumption of the algorithm, we set the size of the codebook to 300.
Figure 7 shows partial results of image classification on Six Actions database using the MsAG, which show that our method had better recognition accuracy on each label category. Meanwhile, the performance of our method is stable in similar categories problem. We believe that our approach is still very competitive in other conditions.
6 Conclusion
In this paper, we explore the multi-scale attributed graph construction and matching kernel for image classification. This may provide a further step to utilize the structure information for image recognition. The comparisons on four standard datasets with five approaches, which are BoW, SP, FDL, WSA and BoVG-SP, show the efficiency of our approach.
Our work has been limited the simple edge construction using delaunay triangulation, there are several nature extension that can be taken advantage of. First, we can build different edge sets to form the local structure for image. Second, one can use various graph distance computation for more accurate graph matching.
References
Penatti, O.A.B., Valle, E., da S. Torres, R.: Encoding spatial arrangement of visual words. In: San Martin, C., Kim, S.-W. (eds.) CIARP 2011. LNCS, vol. 7042, pp. 240–247. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-25085-9_28
Boureau, Y.L., Bach, F., Lecun, Y., Ponce, J.: Learning mid-level features for recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, vol. 26, pp. 2559–2566 (2010)
Sivic, J., Russell, B.C., Efros, A.A., et al.: Discovering objects and their location in images. In: Tenth IEEE International Conference on Computer Vision, vol. 1, pp. 370–377 (2005)
Lowe, D.G.: Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 60(2), 91–110 (2004)
Lazebnik, S., Schmid, C., Ponce, J.: Beyond bags of features: spatial pyramid matching for recognizing natural scene categories. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, vol. 2, no. (1/2), pp. 2169–2178 (2006)
Sadeghi, F., Tappen, M.F.: Latent pyramidal regions for recognizing scenes. In: Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds.) ECCV 2012. LNCS, vol. 7576, pp. 228–241. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-33715-4_17
Yang, J., Yu, K., Gong, Y., et al.: Linear spatial pyramid matching using sparse coding for image classification. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 1794–1801 (2009)
Wang, J., Yang, J., Yu, K., et al.: Locality-constrained linear coding for image classification. In: IEEE Conference on Computer Vision and Pattern Recognition, vol. 119, pp. 3360–3367 (2010)
Cao, Y., Wang, C., Li, Z., et al.: Spatial-bag-of-features. In: IEEE Conference on Computer Vision and Pattern Recognition, vol. 238, pp. 3352–3359 (2010)
Silva, F.B., Werneck, R.D.O., Goldenstein, S., et al.: Graph-based bag-of-words for classification. In: International Conference on Pattern Recognition, vol. 74, pp. 266–285 (2018)
Bunke, H., Allermann, G.: Inexact graph matching for structural pattern recognition. In: International Conference on Pattern Recognition Letters, vol. 1, no. 4, pp. 245–253 (1983)
Jouili, S., Mili, I., Tabbone, S.: Attributed graph matching using local descriptions. In: Blanc-Talon, J., Philips, W., Popescu, D., Scheunders, P. (eds.) ACIVS 2009. LNCS, vol. 5807, pp. 89–99. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-04697-1_9
Silva, F.B., Tabbone, S., Torres, R.D.S.: Bog: a new approach for graph matching. In: International Conference on Pattern Recognition, pp. 82–87 (2014)
Silva, F.B., Goldenstein, S., Tabbone, S., et al.: Image classification based on bag of visual graphs. In: IEEE International Conference on Image Processing, vol. 2010, pp. 4312–4316 (2014)
Hashimoto, M., Cesar, R.M.: Object detection by keygraph classification. In: Torsello, A., Escolano, F., Brun, L. (eds.) GbRPR 2009. LNCS, vol. 5534, pp. 223–232. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-02124-4_23
Zhou, F., Torre, F.D.L.: Deformable graph matching. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, vol. 9, pp. 2922–2929 (2013)
Lee, J., Cho, M., Lee, K.M.: Hyper-graph matching via reweighted random walks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, vol. 42, pp. 1633–1640 (2011)
Zhang, L., Hong, R., Gao, Y.: Image categorization by learning a propagated graphlet path. IEEE Trans. Neural Netw. Learn. Syst. 27(3), 674–685 (2016)
Wu, J., Pan, S., Zhu, X., et al.: Multi-graph-view learning for complicated object classification. In: International Conference on Artificial Intelligence, pp. 3953–3959. AAAI Press (2015)
Mousavi, S.F., Safayani, M., Mirzaei, A., et al.: Hierarchical graph embedding in vector space by graph pyramid. In: International Conference on Pattern Recognition, vol. 61, pp. 245–254 (2017)
Nikolentzos, G., Meladianos, P., Vazirgiannis, M.: Matching node embeddings for graph similarity. In: Proceedings of the 31st Conference on Artificial Intelligence, AAAI, pp. 2429–2435 (2017)
Dong, W., Moses, C., Li, K.: Efficient k-nearest neighbor graph construction for generic similarity measures. In: International Conference on World Wide Web, pp. 577–586. ACM (2011)
Song, J., Gao, L., Zou, F.: Deep and fast: deep learning hashing with semi-supervised graph construction. Image Vis. Comput. 55, 101–108 (2016)
Harchaoui, Z., Bach, F.: Image classification with segmentation graph kernels. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, vol. 76, pp. 1–8 (2007)
Shu, X., Tang, J., Qi, G.J.: Image classification with tailored fine-grained dictionaries. IEEE Trans. Circuits Syst. Video Technol. 28(2), 454–467 (2018)
Grauman, K., Darrell, T.: The pyramid match kernels: discriminative classification with sets of image features. In: Proceedings of the Tenth IEEE International Conference on Computer Vision, vol. 2, pp. 1458–1465 (2005)
Li, F.F., Fergus, R., Perona, P.: Learning generative visual models from few training examples: an incremental Bayesian approach tested on 101 object categories. In: IEEE CVPR Workshop on Generative-Model Based Vision, vol. 106, no. 1, pp. 59–70 (2007)
Griffin, G., Holub, A., Perona, P.: Caltech-256 object category dataset. In: California Institute of Technology (2007)
Li, F.F., Perona, P.: A Bayesian hierarchical model for learning natural scene categories. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp. 524–531 (2005)
Li, P., Ma, J.: What is happening in a still picture? In: International Conference on Pattern Recognition, pp. 32–36 (2011)
Chang, C.C., Lin, C.J.: LIBSVM: a library for support vector machines. ACM Trans. Intell. Syst. Technol. 2(3), 1–27 (2011)
Penatti, O.A.B., Silva, F.B., Valle, E., et al.: Visual word spatial arrangement for image retrieval and classification. In: International Conference on Pattern Recognition, vol. 47, no. 2, pp. 705–720 (2014)
Acknowledgment
The authors would like to thank the anonymous referees for their constructive comments which have helped improve the paper. The research is supported by the National Natural Science Foundation of China (Nos. 61502003, 71501002, 61472002 and 61671018), Natural Science Foundation of Anhui Province (No. 1608085QF133).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Hu, D., Xu, Q., Tang, J., Luo, B. (2018). Multi-scale Attributed Graph Kernel for Image Categorization. In: Lai, JH., et al. Pattern Recognition and Computer Vision. PRCV 2018. Lecture Notes in Computer Science(), vol 11258. Springer, Cham. https://doi.org/10.1007/978-3-030-03338-5_51
Download citation
DOI: https://doi.org/10.1007/978-3-030-03338-5_51
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-03337-8
Online ISBN: 978-3-030-03338-5
eBook Packages: Computer ScienceComputer Science (R0)