
Abstract
Feature pyramid is a basic component in recognition systems for detecting objects of different scales. In order to construct the feature pyramid, most existing deep learning methods combine features of different levels based on a pyramidal feature hierarchy (e.g. SSD, Faster-RCNN). However, it lacks attention to those informative features. In this paper, we propose a gated feature pyramid network (GFPN) extracting informative features to enhance the representation ability of feature pyramid. GFPN consists of gated lateral modules and a top-down structure. The former automatically learns to focus on informative features of different scales, and the latter is used to combine the refined features. By using GFPN on SSD, our method achieves 80.1 mAP on VOC 2007 with an inference time of 11.9 ms per image, which improves the accuracy of FPN applied to SSD by 0.5% and adds marginal efficiency cost.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others
Keywords
1 Introduction
Recognizing objects varying from scales and sizes is a fundamental challenge in computer vision. Recent advances in object detection [1, 2] are driven by the success of deep convolutional networks, which naturally integrate rich features with different resolution and semantic information. Different from those which directly use single feature maps (Fig. 1(a)), SSD [11] first exploits the inherent pyramidal feature hierarchy for multi-scale detection (Fig. 1(b)), which facilitates recognition of objects at different scales. However, the low level features in the inherent pyramidal feature hierarchy lack semantic information, which is not good for visual classification.

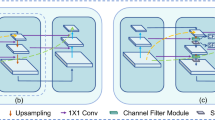
(a) Recent detector using only single scale features for detection. (b) Detector using feature hierarchy for multi-scale detection. (c) Using a feature pyramid to build high-level semantic feature maps at all scales. (d) Our proposed Gated Feature Pyramid (GFPN) is more accuracy than (c) and of comparable efficiency like (b).
In order to enhance the semantic of feature maps at all scales, a top-down architecture with lateral connections is developed to combine different-level features to build feature pyramid. FPN [10] first proposes the method to build a feature pyramid based on a basic Faster R-CNN [14] with marginal extra cost, and achieves significant improvements on COCO detection benchmark [23]. RefineDet [20] constructs a feature pyramid based on a pruned SSD [11], and achieves better results than two-stage methods and maintains comparable efficiency of one-stage approaches. However, these constructions of feature pyramid only utilize the existing pyramidal feature hierarches and do not concentrate on the informative features, such as objectiveness features, which is better for prediction.
In this paper, we propose a gated feature pyramid network (GFPN) to build the targeted feature pyramid. GFPN consists of gated lateral modules and a top-down structure. The former one automatically learns to focus on informative features of different scales. The lateral one is used to combine the refined features. In order to validate the effectiveness of our method, we use GFPN and FPN on SSD [11] respectively. Without bells and whistles, the former one achieves state-of-the-art result on PASCAL VOC2007 detection benchmark [3], and surpasses the lateral one by 0.5% with marginal extra cost.
2 Related Work
2.1 Object Detection
In general, modern object detection methods based on CNNs can be divided into two groups: two-stage methods and one-stage methods. Two-stage methods, such as R-CNN [5], SPPnet [7], Fast R-CNN [15], Faster R-CNN [14], Mask R-CNN [8], first perform a region proposal generation and then make the prediction on each proposal. R-CNN [6] firstly combines selective search [18] region proposals generation and CNN-based classification. Faster R-CNN [14] replaces the selective search by Region Proposal Network (RPN), making proposal generation become a learnable part. One-stage detectors consider the classification and bounding box regression in a single network, including Over-feat [16], YOLO [13], SSD [11], YOLO9000 [12]. Among them, YOLO [13] uses only single scale features for multi-scale objects detection, and has high efficiency.
SSD [11] firstly predicts objects in multi-scale layers by distributing default boxes with different scales, which improves the accuracy of generic objects with high efficiency. In this paper, we focus on SSD [11] with the consideration of its high efficiency and comparable accuracy of two-stage approaches.
2.2 Feature Pyramid
Combining features from different layers is a basis component in many recent proposed object detectors [4, 9, 10, 17]. FPN [10] first proposes the method to build a feature pyramid based on a basic Faster R-CNN with marginal extra cost, and achieves significant improvements on COCO detection benchmark. TDM [17] proposes top-down modulation to improve performance for hard examples. DSSD [4] first tries to construct the feature pyramid on SSD [11]. In this paper, we propose a gated feature pyramid network to improve the performance of feature pyramid with marginal extra cost.
2.3 Attention Mechanism
Attention mechanism is widely used in object recognition [19, 21, 22]. Residual Attention [19] proposes a soft weight attention to adaptively generate the attention-aware features. SENets [21] introduces a channel attention to existing state-of-the-art classification architectures, and wins first place on ILSVRC dataset. Harmonious attention network [22] proposes the harmonious attention which combines the mentioned two kinds of attention mechanism. In this paper, we introduce a gated connection which is a kind of channel attention.
3 Gated Feature Pyramid Network
We aim to build a gated feature pyramid based on SSD model, which is the state-of-the-art object detector with respect to accuracy-vs-speed trade-off. In this section, first we briefly introduce SSD and the improvement we have made on it. And then we present the gated feature pyramid, which consists of gated lateral modules and the top-down structure.
3.1 Single Shot Multibox Detector
The single-shot multibox detector (SSD) can be divided into two parts: (1) a shared feedforward convolution network, and (2) a set of sub-networks for classification and regression which do not share computation. The former part takes VGG-16 [24] as base network and adds several additional feature layers, which produce a pyramidal feature hierarchy consisting of feature maps at several scales. The lateral one spreads dense predefined anchors on selected feature maps provided by the former part, and then applies two convolutional layers to predict the classification and location of objects respectively. In total, SSD adopts 6 prediction layers to predict different size of objects, for example, conv4_3 for smallest objects, conv11_2 for largest objects. Considering that shallow layers are lack of enough semantic information, SSD [11] forgoes using shallower layers (e.g. conv3_3). Thus it misses the opportunity to use the high resolution maps of the feature hierarchy.
Considering that feature pyramid can introduce semantic information to all scales of the feature hierarchy, we add a new prediction layer on conv3_3 to improve the performance for small objects. To avoid adding too much computational burden, we only use one size of anchors with one kind of aspect ratios, as Table 1 shows.
3.2 Gated Lateral Modules
Our goal is to ensure that the feature pyramid network can select the meaningful features at different scales, so it can enhance the useful features which will further improve the representation ability of feature pyramid network. To achieve this, we propose the gated lateral modules. As Fig. 2 shows, it consists of a normal convolutional layer, a channel attention mechanism and an identity mapping, which is inspired by Residual Attention [19] and SENets [21]. In the following, we will give a detailed presentation of these modules.

An overview of our proposed GFPN and a detailed structure of gated lateral modules.
Convolutional Layer.
This convolutional layer is designed to reduce the channel dimensions of input feature maps. In this paper, the channel dimensions of each selected feature maps are reduced to 256 by a 3 \( \times \) 3 convolutional layer, which also play a role in enhancing the representation ability of networks.
Channel Attention Mechanism.
The aim of channel attention is to enhance the targeted features. We apply Squeeze-and-Excitation block [21] as our channel attention, which consists of two stages, namely, the squeeze stage and the excitation stage. The former stage is designed for global information embedding, and the latter one for inter-channel dependency modelling. This channel attention mechanism will enhance the sensitivity of targeted features so that they can be exploited by feature pyramids.
Identity Mapping.
We apply an element-wise sum operation to obtain the final outputs, which consists of the weighted features and original features. The motivation of this design is to ensure that the channel attention mechanism will not break the good property of original features, particularly inspired by Residual Attention [19].
As Fig. 3 shows, the mean activations of some feature maps become smaller after the gated lateral modules, which means that useless features are suppressed, and useful features are enhanced.

Visualization of mean activations before and after gated lateral modules. The left column is the input image, the two columns on the right show the mean activations of feature maps of each selected layer. We only show the results of conv3_3 and conv4_3 for better exhibition.
3.3 Top-Down Structure
Each feature combination module is designed to combine the targeted features and the high-level features, which aims to further enhance the representation ability of the feature pyramid. A detailed example of the feature combination module is illustrated in Fig. 4. It consists of three parts: a deconvolution layer, an element-wise sum operation and a 3 \( \times \) 3 convolutional layer. The deconvolution layer transforms the dimensions of high-level feature maps from \( H \times W \times 256 \) to \( 2H \times 2W \times 256 \). Then an element-wise sum operation is applied to obtain the combined features, which are high spatial resolution and semantic strongly. In order to enhance the representation ability of each prediction module, we add a 3 \( \times \) 3 convolutional layer, particularly inspired by DSSD [4].

An example with details of top-down structure.
4 Experiments on Object Detection
In this section, we evaluate the performance of the proposed detector by comparing it with the state-of-the-art methods. And the experimental details are also given.
4.1 Result on Pascal VOC
GFPN is trained on VOC 2007 and 2012 trainval sets, and tested on VOC 2007 test set. For the improved SSD which adds conv3_3 to predict smaller objects, we use a batch size of 16 with 300 \( \times \) 300 inputs, and started the learning rate at 10−1 for the first 80 K iterations, then decrease it at 120 K iterations and 160 K iterations by a step of 10−1. We take this well-trained SSD model as the pre-trained model for the GFPN. Meanwhile, the gated lateral modules, the top-down structure and the prediction sub-networks are initialized with bias b = 0 and ‘Xavier’ weight [6]. After that, the initial learning rate is set as 10−1 for the first 80 K iterations, and decreases to 10−3 at 120 K and 10−5 at 160 K.
Table 2 shows the comparisons of GFPN with the state-of-the-art one-stage detectors. It can be seen that GFPN reaches 80.1% for the 300 × 300 input. GFPN surpasses SSD300 and SSD321 by 2.8% and 3.0%. Compared with those approaches that utilize FPN (e.g. DSSD321, RefineDet), GFPN also achieves relatively higher accuracy. In summary, our proposed detector achieves the state-of-the-art performance.
4.2 Running Time Performance
The running time of GFPN is evaluated with batch size 8 on a machine with NVIDIA Titan Ti, CUDA8.0 and cuDNN v7. Table 3 shows the comparisons of speed with the state-of-the-art one-stage detectors. It is clear that our detector takes 11.9 ms to process an image with input sizes 300 × 300. The speed of GFPN is slightly lower than that of the fastest SSD300 but still satisfies the requirement of real-time detection. Moreover, our detector can achieve the most excellent accuracy. For practical applications, GFPN achieves the state-of-the-art performance with the best trade-off between accuracy and efficiency.
4.3 Ablation Study
To demonstrate the effectiveness of different components in GFPN, we design three variants and validate them on PASCAL VOC2007 [3]. As shown in Table 4, the three variants, namely, gated lateral modules, feature pyramid and conv3_3, are added to the single-shot framework respectively. Meanwhile, for a fair comparison, we set the training iteration, batch size and input size as the same. The models are trained on PASCAL VOC 2007 and 2012 trainval sets, and tested on PASCAL VOC 2007 test set.
How important is low-level features?
To evaluate the effectiveness of the conv3_3, we add a new prediction layer on conv3_3, as Table 1 shows. Table 4 of col 4 and col 5 shows the results of our improved SSD and the pure SSD. It is clear that the accuracy increase 0.3% mAP from 77.3% to 77.6%. The result shows that the low-level features do helps promote the performance of detectors. To further validate this conclusion, we conduct experiments based on feature pyramid. As col 1 and col 2 of Table 4 shows, the addition of conv3_3 improves the accuracy of FPN based on pure SSD by 0.4%.
How important are gated lateral modules?
To validate the effectiveness of gated lateral modules, we apply the gated lateral modules on each chosen layer of SSD. As shown in col 1 and col 2 of Table 4, we observe a significant improvement of performance with gated lateral connection. The result shows the gated lateral modules play a critical role in enhancing the target-specific features to improve the detection performance.
4.4 Detection Analysis on PASCAL VOC2007
We show some qualitative results on PASCAL VOC2007 test set in Fig. 5. A score threshold of 0.6 is used to display these images. Different colors of the bounding boxes indicate different object categories. From Fig. 5, GFPN achieves an excellent performance on generic object detection. Even for the occlusion, the detection result is satisfactory.

Qualitative results of GFPN on the PASCAL VOC 2007 test set. VGG16 is used as the backbone network. The training data is PASCAL VOC 2007 and 2012 trainval sets.
5 Conclusion
In this paper, we propose a gated feature pyramid network (GFPN) for object detection. To address the problem that feature pyramid does not focus on the targeted features, we introduce a gated feature pyramid, which utilizes the idea of attention mechanism to enhance the meaningful features. We apply the GFPN on SSD, and train the combined module on PASCAL VOC 2007 and 2012 datasets. The result demonstrates the effectiveness of our method.
References
Sean, B., Zitnick, C.L., Kavita, B., Ross, G.: Inside-outside net: detecting objects in context with skip pooling and recurrent neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2874–2883 (2016)
Jifeng, D., Yi, L., Kaiming, H., Jian, S.: R-FCN: object detection via region-based fully convolutional networks. In: Advances in Neural Information Processing Systems, pp. 379–387 (2016)
Mark, E., Luc, V.G., Christopher, K.W., John, W., Andrew, Z.: The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 88(2), 303–338 (2010)
Cheng-Yang, F., Wei, L., Ananth, R., Ambrish, T., Alexander, C.B.: Dssd: Deconvolutional single shot detector. arXiv preprint arXiv:1701.06659 (2017)
Ross, G., Jeff, D., Trevor, D., Jitendra, M.: Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 580–587 (2014)
Xavier, G., Yoshua, B.: Understanding the difficulty of training deep feedforward neural networks. In: Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, pp. 249–256 (2010)
He, K., Zhang, X., Ren, S., Sun, J.: Spatial pyramid pooling in deep convolutional networks for visual recognition. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8691, pp. 346–361. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10578-9_23
Kaiming, H., Georgia, G., Piotr, D., Ross, G.: Mask R-CNN. In: IEEE International Conference on Computer Vision (ICCV), pp. 2980–2988 (2017)
Tao, K., Fuchun, S., Anbang, Y., Huaping, L., Ming, L., Yurong, C.: Ron: reverse connection with objectness prior networks for object detection. In: IEEE Conference on Computer Vision and Pattern Recognition, vol. 1, pp. 2 (2017)
Tsung-Yi, L., Piotr, D., Ross, G., Kaiming, H., Bharath, H., Serge, B.: Feature pyramid networks for object detection. In: CVPR, vol. 1, p. 4 (2017)
Liu, W., et al.: SSD: single shot MultiBox detector. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9905, pp. 21–37. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46448-0_2
Joseph, R., Ali, F.: Yolo9000: Better, faster, stronger. In: IEEE
Joseph, R., Santosh, D., Ross, G., Ali, F.: You only look once: unified, real-time object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 779–788 (2016)
Shaoqing, R., Kaiming, H., Ross, G., Jian, S.: Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39(6), 1137–1149 (2017)
Ross G.: Fast R-CNN. In: IEEE International Conference on Computer Vision, pp. 1440–1448 (2015)
Pierre, S., David, E., Xiang, Z., Micha, M., Rob, F., Yann, L.C.: Overfeat: integrated recognition, localization and detection using convolutional networks. In: International Conference on Learning Representations (2014)
Abhina, S., Rahul, S., Jitendra, M., Abhinav, G.: Beyond skip connections: Top-down modulation for object detection. arXiv preprint arXiv:1612.06851 (2016)
Uijlings, J.R.R., et al.: Selective search for object recognition. Int. J. Comput. Vis. 104(2), 154–171 (2013)
Fei, W., et al.: Residual attention network for image classification. arXiv preprint arXiv:1704.06904 (2017)
Shifeng, Z., Longyin, W., Xiao, B., Zhen, L., Stan, Z.L.: Single-shot refinement neural network for object detection. arXiv preprint arXiv:1711.06897 (2017)
Hu, J., Shen, L., Sun, G.: Squeeze-and-Excitation Networks. In: CVPR (2017)
Li, W., Zhu, X., Gong, S.: Harmonious attention network for person re-identification. In: CVPR (2018)
Lin, T.-Y., et al.: Microsoft COCO: common objects in context. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8693, pp. 740–755. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10602-1_48
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: Computer Science. (2014)
Acknowledgements
This work is supported by Natural Science Foundation (NSF) of China (61836008, 61472301).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Xie, X., Liao, Q., Ma, L., Jin, X. (2018). Gated Feature Pyramid Network for Object Detection. In: Lai, JH., et al. Pattern Recognition and Computer Vision. PRCV 2018. Lecture Notes in Computer Science(), vol 11259. Springer, Cham. https://doi.org/10.1007/978-3-030-03341-5_17
Download citation
DOI: https://doi.org/10.1007/978-3-030-03341-5_17
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-03340-8
Online ISBN: 978-3-030-03341-5
eBook Packages: Computer ScienceComputer Science (R0)