
Abstract
The ability to extract the discriminative features remains a fundamental task of object detection, especially for small objects. Many mainstream object detection models, use the feature pyramids structure, a kind of fusion approaches, to predict objects of different scales. This traditional fusion strategy aims to merge different feature maps by linear operation, which does not allow the model to learn the complementary relationship between spatial information and semantic information. To address this problem, we develop a non-linear embedded network (NlENet) to achieve multi-scale fusion, which can learn the potential complementary relationship through end-to-end autonomous learning and get a more accurate performance. There are three main blocks in this proposed network, residual convolution unit (RCU), multi-resolution fusion and chained residual pooling. Due to the flexibility of the NlENet, we can embed it into many mainstream detection frameworks with few modification. We confirm that our fusion network can extract richer and more accurate features and achieve a better object detection performance on the COCO2017 dataset.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Object detection is a fundamental task of computer vision. Object detection is defined as locating and classifying all objects in an input image. One of the most effective ways to improve results is learning robust and comprehensive feature representation. So some early works, such as Fast R-CNN [2], try to compute a single feature map through a CNN and use it to complete detection. However, as the network gets deeper, the feature map we computed will lose a lot of spatial detail information, which is disadvantageous for detection because the detection requires precise spatial position. So many current works focus on how to get more accurate spatial information and more discriminative semantic information. In many current mainstream methods, such as RetinaNet [14], Mask-RCNN [5], feature fusion is an essential tool to improve the accuracy of object detection, especially for small objects. As shown in Fig. 1, The core fusion idea of these work is the feature pyramid network(FPN) [13], which fuses feature maps at different sacles which are extracted from the original image in the backbone network instead of using single feature map. It is known that the high-level feature maps in the network are rich in semantic information but lacking spatial information, while the low-level feature maps, in contrast, contain rich spatial information but lack semantic information. FPN makes use of both high level feature maps and low level feature maps via adding a upside down path to transfer the semantic information to the lower part of the network, leading to a feature representation containing both rich semantic information and rich spatial information, which can probably improve the detection result. Howerver, there is no nonlinear structure in FPN, and the complementary relationship between spatial information and semantic information can not be captured, which limits the performance of the model. Therefore, the core contribution of this paper is to propose a new fusion rule based on network learning, which can obtain the potential complementary relationship between spatial information and semantic information through end-to-end autonomous learning.

FPN framework. These feature maps are extracted from different locations in the backbone network. The yellow boxes represent the fusion operator of FPN. For each input feature map, FPN will give a corresponding fused feature map. The specific fusion strategy is shown in the yellow dotted box. It consists of an upsampled layer, a convolutional layer and a linear summation. In particular, the upsampled layer is not necessary if there is only one input. (Color figure online)
In this paper, we adopt a elaborated feature fusion strategy for object detection. The main idea is to develop a non-linear embedded network to achieve multi-scale fusion. Non-linear operators have advantages over linear operators about extracting features. The idea of non-linearity is widely used in machine learning, manifold learning and neural networks, which is shown good performance. The embedded network structure makes our method more flexible and can be integrated into multiple network structures. Specifically, we design a refined network to capture both semantic and spatial information at the same time, allowing it automatically extract discriminant information from different layers and learn the optimal combination. There are three main blocks in our fusion network, residual convolution unit (RCU), multi-resolution fusion and chained residual pooling. Compared to the FPN, the non-linear fusion will exploit more semantic information and spatial information, leading a more accurate object detector. We propose a convolutional network named NlENet, that is, non-linear embedded network, by incorporating this new feature fusion strategy. Experimental evaluation was conducted on the COCO dataset [7] and the results validated that our fusion framework do have better performance.
In our paper, the contributions can be summarized as the followings.
-
1.
We introduce a non-linear embedded network (NlENet) which can obtain the potential complementary relationship between spatial information and semantic information through end-to-end autonomous learning and combine them to get a more accurate performance.
-
2.
We give a concise and persuasive theoretical analysis to prove that our method is theoretically valid.
-
3.
According to experimental results, our method can improve the performance of object detection tasks, and due to the flexibility of the NlENet, we can embed it into the backbone network of many mainstream detection tasks with minor modifications.
The rest of this paper is organized as follows. Section 2 briefly reviews the related works on object detection and fusion strategy. Details of the proposed method and some analysis are presented in Sect. 3. Experimental results are reported in Sect. 4, and Sect. 5 concludes the whole paper.
2 Related Work
2.1 Object Detectors
The sliding-window method, in which a classifier is applied on a dense image grid, has a long history [14]. For example, Viola et al. [16] used boosted object detectors for face detection. At this stage, many feature extraction methods are based on hand-engineered features due to computational constraints. The HOG and SIFT feature [18] have been widely used at this stage. The DPMs [17] extends the original dense approach to make the entire framework more flexible, and this approach ranks top-one result for many years on the PASCAL dataset [19]. Although the sliding-window method has been very successful in the traditional computer vision, with the arrival of deep learning [6], more frameworks based on convolutional neural networks [14] appear and become the mainstream method of object detection rapidly.
2.2 Two-Stage Detectors
In the modern object detection, the most famous method is based on a two-stage approch [14]. This kind of method divides object detection into two steps. The first step is to generate a series of candidate proposals that contain all the objects in the image and remove a large number of backgrounds. The second step is to classify these proposals into foreground classes or background. R-CNN [3] is a classical two-stage framework based on deep learning, which upgraded the second-stage classifier to a convolutional network and improved a lot in accuracy. There are many works to extend R-CNN. For example, Fast R-CNN [2] speeded up by employing an end-to-end training procedure. Faster R-CNN [20] introduces a new module, namely Region Proposal Networks(RPN), which integrated proposal generation with the second-stage classifier into a single convolution network. Until now, the Faster R-CNN method was still the classic way of two-step detection, and a lot of work was done in order to improve its performance [4].
2.3 One-Stage Detectors
Although the two-step approach has been very successful, there are still some limitations. The main disadvantage is that it takes too much time to generate the candidate proposals in the first step. The one-step approaches are to improve speed, but their accuracy trails that of two-stage methods. It is a trade-off problem. OverFeat [11] was one of the first modern one-stage object detectors based on deep network. The SSD [8] and YOLO [10] are recent models in one-stage methods. The core idea is to divide the original image into several grids, and to execute classification and regression on each grid. SSD has a nearly 10% higher AP than YOLO while the speed of YOLO is almost three times faster than that of SSD [14].
Based on the strengths and weaknesses of one-step and two-step approaches, there are also some works [14] to design a good and fast framework. There are two common ways to consider this problem, which are making two-step models faster or make one-step models more accurate. RetinaNet [14] is a simple one-step network designed to achieve the accuracy of two-step models and the speed of one-step models. This model uses a new loss function that adjusts the weight of the positive and negative samples in the one-step method to improve the accuracy of the model.
2.4 Multi-scale Fusion
When an input image is forwardly calculated in the network, the feature maps will contain less spatial information, and the semantic information will gradually increase. This phenomenon will result in inaccurate location about object detection, especially for some small objects. Feature fusion is an effective way to improve the ability of feature representation. A number of recent methods [24] improve detection and segmentation by using different layers in a convolution network, beacuse the low-level feature contains more spatial information and the high-level feature contains more semantic information. For example, SSD [8] and MS-CNN [1] predict objects at multiple layers but do not fuse the hierarchical features. U-Net [21] and Stacked Hourglass networks [22] exploits sample fusion, lateral or skip connections, that associate low-level feature maps through spatial and semantic levels. FPN and RetinaNet combine traditional feature pyramid methods with neural networks to produce more discriminative features by using multi-scale methods while guaranteeing detection speed. However, this linear fusion operator does not make full use of these two kind information, which is just a linear combination.

Our framework. Our framework mainly consists of three processes. The first one is feature extraction, which uses the forward calculation of the network to extract feature maps with different sizes. The second one is the NlENet, which use the non-linear operator and embedded way to fuse the feature maps and enhance the information in each feature map. The last one is detection, sending each feature map to the corresponding detection sub-network to perform the corresponding task.
3 Proposed Method
3.1 Framework
Our model consists of a backbone network and a series of sub-networks, and each of sub-networks contains two tasks, classification and regression. The number of sub-networks depends on the number of NlENet. For the input image, the backbone network is used to extract the feature maps of different network layers and create new corresponding fused feature maps by our fusion strategy, which is similar to FPN but the core idea is completely different. The classification network and the regression network accept the output of the backbone network, and the final result is calculated through a corresponding network structure. In order to ensure the speed of the one-step method, both sub-networks only contain few regular units, which is shown in Fig. 2. Following the work [13], we design a pyramid based on the ResNet architecture [23]. We extract feature maps in the backbone network from the bottom to up, where the feature map scale changes, and donate as { \(C_3\),\(C_4\),\(C_5\),\(C_6\),\(C_7\) } where the subscript means pyramid level. From \(C_3\) to \(C_7\), the scale of feature maps in the pyramid is reduced by 2 times. All of these feature maps have 256 channels.
In order to handle the unbalanced samples problem, we use focal loss [14] as our optimization goal, which is defined as Eq. 1. The variable \(p_t\) is a simple variant of the binary classification probability that can be derived from the model. Focal loss is essentially an extension of the cross-entropy loss. The parameters \(\alpha _t\) and \(\gamma \) are control factors based on experience. In practice, we usually set \(\alpha _t=0.25\) and \(\gamma =2\).

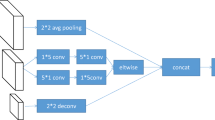
Fusion network. There are three main blocks in NlENet, including residual convolution unit (RCU), multi-resolution fusion and chained residual pooling. The dashed line of the input feature maps indicates that the module can accept up to two inputs, and if there is only one input, the middle layer’s operation, multi-resolution fusion is not needed. Due to multi-layer pooling, this structure as a whole is a non-linear operator.
3.2 Fusion Strategy
The structure of the NlENet is shown in Fig. 3. The whole process of fusion can be divided into three main steps, residual convolution unit, multi-resolution fusion and chained residual pooling, which is inspired by the general structure of RefineNet [15] used in semantic segmentation.
The residual convolution unit (RCU), is a simplified version of the convolutional block in the ResNet, and the original batch-normalization layer is removed. The number of filters is equal to that of the feature map channels in backbone network. This is a transitional module, which finetunes the weights of original backbone network layer to adapt our object detection task. Considering the time consume and numbers of parameters, we usually use two RCUs in one blocks for tuning in our network.
The multi-resolution fusion block aims to integrate all inputs into a fused high-resolution feature map. This block first apply convolutions for multi-inputs in odrer to adaption. This convolution does not change the shape of each feature map. After that, we upsample all the small feature maps to the largest scale and add up all of them to get the fused feature maps. If there is only one input, the addition is not needed, but the rest operations of the block can not be ignored.

The distribution of the information amount. The x-axis represents the amount of spatial information and the y-axis represents the amount of semantic information. The yellow area is mainly the range of high-level feature maps, and the blue area represents the range of low-level feature maps. The red dotted line is the output of \(F_l(L_l,L_h)\) which represents the location of the output after the linear fusion, and the green dotted line, the output of \(F_n(L_l,L_h)\) , represents the distribution of the output after executing the non-linear fusion. Solid dots of different colors represent an instance of different distributions. It can be very intuitive to find that non-linear strategy is able to capture more information. (Color figure online)
The chained residual pooling block is a higher-level process for fused feature maps and we can understand it as finding more useful information. It is interested that this module is designed as a cascaded form. This means that you can connect the fundamental unit in this module as many times as you want. The fundamental unit is consisted of only one pooling layer and one convolutional layer. The inputs of this block will be connected with an ReLU activation layer then will be sent to this fundamental unit. Another fundamental unit can be cascaded after this one if necessary. The output feature maps of all pooling blocks are fused together with the input feature map through the summation. These chained units aim to capture more widely context from a large image region. Due to the non-linear pooling operation, the fitting ability of the whole operator has been improved, which is very important in the network structure. The final step of our operator is another RCU. Following the RefineNet, this results in a sequence of three RCUs between each block. The goal here is to employ non-linearity operations for further processing or for final prediction [15]. In addition, this layer does not change the feature shape.
3.3 Analysis
In this part we will give a simple and intuitive proof to explain why our nonlinear operator works, compared with other fusion strategies. We define I as the information contained in the feature maps. Next, we define \(I_s\) as semantic information and \(I_l\) as spatial information in the feature map. We can naturally get the equation \(I=I_s \oplus I_l\) when ignoring the noise and other random factors.
We define a parameter space D consisting of \(I_s\) and \(I_l\). As mentioned, the high-level feature map contains rich semantic information and little spatial information, but the low-level feature map is on the opposite. We divide the parameter space into four regions to roughly describe the distribution of the information amount for the different feature maps. As shown in Fig. 4, high-level feature maps will be concentrated in the yellow block, the low-level features will gather in the blue block. The green dot represents an instance of a specific feature map in our network.
Let’s consider the fusion operation. We define a binary operator \(F(\cdot , \cdot )\) accepting that two different layers of feature maps as input. We use \(L_l\) and \(L_h\) to represent the features from the lower level and the features from the upper level respectively. If we use a linear version of the F, noted as \(F_l\), the output is only a weighted summation of the original input information. This strategy indeed gather the two information together, but at the same time, there is a loss of both kinds of information, which is more like the “average” of the two kinds of information. In the parameter space D, the output is only distributed on the red dotted line between the two green dots because the output is only linear weighted sum of the input. If we use the our fusion operator in this paper, noted as \(F_n\), the operator’s non-linear fusion ability is increased, which allows the operator to capture more information and make the fused feature map more discriminative.
In short, because of the introduction of nonlinear operations in NLEnet, such as chained residual pooling, the two kinds of information are more complementary in the fusion process, rather than a simple linear combination, which embodies the advantages of each feature. There is a significant improvement in the detection results.
4 Experiments
4.1 Dataset
We conducted our experiment on the COCO dataset [7] with 80 categories. For training, we use the COCO trainval35k split. We report our result by evaluating on the minival split [14]. We evaluate the COCO-style Average Recall(AR) and Average Precision(AP) on small, medium and large objects, whose definition is in the work [7]. In order to obtain a good model, the backbone network is pre-trained on the ImageNet classification set [23] and then fintuned on our COCO detection dataset. We use the pre-trained ResNet-50 models that are publicly available. Our code is implemented using Keras.
4.2 Implementation Detail
Our structure is trained end-to-end. We adopt Adam training on 4 GPUs. The size of the image entered on the network is fixed to \(224\times 224\). A mini-batch contains 4 images and 256 anchors per images. During training, network converges after 1500 epochs. The learning rate is first set to \(10^{-4}\), which is then divided by 10 at 600 iterations. Training the whole framework on 4 GPUs takes about 2 days on COCO. We use a random horizontal flip and vertical flip, the probability is 0.5. In addition, we also introduce a random translation (up to one-tenth of its side length) and scaling (between 1 and 1.2 times), which make our model more robust. During testing, execution time on NVIDIA GeForce 1080Ti is roughly 84msec for an image of shape \(1000\times 800\times 3\).
At the same time, we have designed a contrast network, RetinaNet-FPN, to prove the validity of our framework. The structure of this network is basically the same as that of Fig. 2. The only difference is that we have replaced the NLE unit with the FPN element as shown in Fig. 1. In the process of experiment, the same experimental parameters and training process are adopted.
4.3 Parameter Analysis
Due to the flexibility of NlENet, we can insert it into the backbone network through a variety of ways. In this section, we will analyze the relationship between the number of NLENet and the detection results and the whole network performance. We denote K as the number of NlENet, and different K correspond to different pyramid structures. For example, when \(K=2\), that means that we want to fuse \(C_3\) and \(C_4\), these two feature maps. The first NlENet receives \(C_3\) and outputs \(N_3\), and the second NlENet receives \(N_3\) and \(C_4\) and outputs \(N_4\). Specifically, when K equals 0, there is no feature fusion in the network at this time, and this will be used as the baseline in our experiment.
We use two evaluation methods to evaluate the network performance, that is, AP curve and performance curve. AP has already been introduced in the Sect. 4.1. The performance curve describes the average contribution of each embedded network to the whole network performance improvement, which can be described by the formula as:
As shown in Fig. 5, with the increase of K, the accuracy of network is also improved. This phenomenon confirms that our NlENet in this paper can learn the potential complementary relationship between spatial information and semantic information. However, the performance curve tells us that NlENet can not be stacked indefinitely. With the increase of K, the performance of each embedded network first rises and then gradually decreasing when reaching the maximum. When \(K=4\), each NlENet can reach the best performance. If we continue to fuse more features, the network will pay too much attention to detail information, such as background noise, which is detrimental to performance.

Parameter Analysis. The left diagram shows the different stacking structures of NlENet under different K value. K represents the number of NlENet, and \(N_i\) represents the output of the network when \(N_{i-1}\) and \(C_i\) are input. Specifically, \(N_3\) has only one input \(C_3\). The right picture shows the accuracy of detection (blue curve) and the average performance (yellow curve) of each NlENet under different K value. The horizontal axis represents the value of K. (Color figure online)
4.4 Result
Our experiment is designed to prove the effectiveness of our fusion operator. In this experiment, we compare our method with another widely used fusion structure, FPN. The experimental results are shown in Table 1. The experimental results show that our embeded network improves the result of object detection, which has a 4% performance improvement over the RetinaNet. Specifically, the detection of small objects is the largest increase on AP evaluation, which shows that our method can indeed capture more spatial information in the feature map, and also have a good performance for small objects.
We also made a visualization to clearly show the improvement of NlENet in Fig. 6. This visualization result shows the different fusion of the feature maps extracted from the backbone network. We can also treat each line in this diagram as a process of information integration during the network forward computation. It can be clearly seen that (a) NlENet alleviates the dissipation of spatial information, which promotes high-level feature maps can also capture spatial information transmitted from lower layers, especially for small objects; (b) high-level semantics gradually penetrate into lower layers, which leads to higher response values of semantic-related content in low-level feature maps; (c) NlENet guides the overall detection framework to focus on areas closely related to high-level semantics, greatly suppressing background and noise, especially for edge noise. Compared with the fusion strategy in the RetinaNet, our method is more powerful and accurate.

Visualization of feature maps. This picture respectively visualizes the results of the fusion under the RetinaNet and our framework. Each column in the figure is a fusion of feature maps extracted from different locations in the backbone network.
5 Conclusion
In this work, we develop a elaborated embeded feature fusion network for object detection, which can obtain the potential complementary relationship between spatial information and semantic information through end-to-end autonomous learning and combine them to get a more accurate performance. Then we give a brief analysis about the advantages of our fusion strategy. Finally, NlENet is pretty flexible and can be integrated into other networks with minor modifications.
References
Cai, Z., Fan, Q., Feris, R.S., Vasconcelos, N.: A unified multi-scale deep convolutional neural network for fast object detection. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9908, pp. 354–370. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46493-0_22
Girshick, R.: Fast R-CNN. In: ICCV (2015)
Girshick, R., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for accurate object detection and semantic segmentation. In: CVPR (2014)
Hariharan, B., Arbeláez, P., Girshick, R., Malik, J.: Hypercolumns for object segmentation and fine-grained localization. In: CVPR (2015)
He, K., Gkioxari, G., Dollár, P., Girshick, R.: Mask R-CNN. In: arXiv:1703.06870 (2017)
Krizhevsky, A., Sutskever, I., Hinton, G.: ImageNet classification with deep convolutional neural networks. In: NIPS (2012)
Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft COCO: common objects in context. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8693, pp. 740–755. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10602-1_48
Fu, C.-Y., Liu, W., Ranga, A., Tyagi, A., Berg, A.C.: DSSD: Deconvolutional single shot detector. In: arXiv:1701.06659 (2016)
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.-Y., Berg, A.C.: SSD: single shot multibox detector. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9905, pp. 21–37. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46448-0_2
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: unified, real-time object detection. In: CVPR (2016)
Sermanet, P., Eigen, D., Zhang, X., Mathieu, M., Fergus, R., LeCun, Y.: Overfeat: Integrated recognition, localization and detection using convolutional networks. In: ICLR (2014)
Shrivastava, A., Gupta, A., Girshick, R.: Training region-based object detectors with online hard example mining. In: CVPR (2016)
Lin, T.-Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: CVPR (2017)
Lin, T.-Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. In: ICCV (2017)
Lin, G., Milan, A., Shen, C., Reid, I.: RefineNet: multi-path refinement networks for high-resolution semantic segmentation. In: CVPR (2017)
Viola, P., Jones, M.: Rapid object detection using a boosted cascade of simple features. In: CVPR (2001)
Felzenszwalb, P.F., Girshick, R.B., McAllester, D.: Cascade object detection with deformable part models. In: CVPR (2010)
Lowe, D.G.: Distinctive image features from scale-invariant keypoints. IJCV 60(2), 91–110 (2004)
Everingham, M., Van Gool, L., Williams, C.K., Winn, J., Zisserman, A.: The PASCAL Visual Object Classes (VOC) challenge. IJCV 88(2), 303–338 (2010)
Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: towards real-time object detection with region proposal networks. In: NIPS (2015)
Ronneberger, O., Fischer, P., Brox, T.: U-Net: convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9351, pp. 234–241. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-24574-4_28
Newell, A., Yang, K., Deng, J.: Stacked hourglass networks for human pose estimation. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9912, pp. 483–499. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46484-8_29
Russakovsky, O.: ImageNet large scale visual recognition challenge. IJCV 115(3), 211–252 (2015)
Fu, H., Cheng, J., Xu, Y., Wong, D.W.K., Liu, J., Cao, X.: Joint optic disc and cup segmentation based on multi-label deep network and polar transformation. IEEE Trans. Med. Imaging 37(7), 1597–1605 (2018)
Bell, S., Zitnick, C.L., Bala, K.: Inside-outside net: detecting objects in context with skip pooling and recurrent neural networks. In: CVPR (2016)
Acknowledgment
This project is supported by the Natural Science Foundation of China (61702566, 61573387).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Zhang, Q., Lai, J., Xie, X., Zhu, J. (2018). Exploring Multi-scale Deep Feature Fusion for Object Detection. In: Lai, JH., et al. Pattern Recognition and Computer Vision. PRCV 2018. Lecture Notes in Computer Science(), vol 11259. Springer, Cham. https://doi.org/10.1007/978-3-030-03341-5_4
Download citation
DOI: https://doi.org/10.1007/978-3-030-03341-5_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-03340-8
Online ISBN: 978-3-030-03341-5
eBook Packages: Computer ScienceComputer Science (R0)