
Abstract
Erector spinae muscle (ESM) is an important muscle in the torso region. Changes of sizes, shapes and densities in the cross section of the spinal column muscles have been found in chronic low back pain, degenerative lumbar sclerosis and chronic obstructive pulmonary disease. However, the image features of the ESM are measured manually by the physician. Therefore, automatic recognition in three dimensions (3D) not only for the limited two-dimensional (2D) section but also for the whole ESM is required. In this study, we realize automatic recognition of the ESMs and its attachment region on the skeleton using a 2D deep convolutional neural network. Each cross section of the 3D computed tomography (CT) image is input as a 2D image to the fully convolutional network. Then, the obtained result is reconstructed into a 3D image to obtain the recognition result of the ESM and its attachment region on the skeleton. ESM and attached area are extracted manually from the CT images of 11 cases and used for evaluation. In the experiments, automatic recognition was performed for each case using the leave-one-out method. The mean recognition accuracy of ESM and attached area was \(89.9\%\) and \(65.5\%\), respectively for the Dice coefficient. In this study, although there is over-extraction in the recognition of the attachment region, the initial region has been acquired successfully and it is the first study to simultaneously recognize the ESMs and its attachment region on the skeleton.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
- Erector spinae muscles
- Skeletal muscles
- Deep convolutional neural networks
- Fully convolutional networks
1 Introduction
Erector spinae muscles (ESMs) are important muscles acting on extension and rotation at the trunk. In the chronic low back pain and the degenerative lumbar scoliosis (DLS), changes of the size, shape and density of the cross-sectional area (CSA) of the ESMs are found [1, 2]. Furthermore, in the chronic obstructive pulmonary disease, the cross sectional area of the ESMs of the 12th thoracic vertebra is an excellent prognostic factor [3]. However, image analysis of these spinal column erector muscles is performed manually by clinicians. Therefore, the measurements suffer from inter-clinician reliability and intra-clinician reproducibility. In addition, spinal erector muscle is relatively large and has many adjacent muscles, extraction requires expertise and time consuming manual work. For these reasons, the current analysis remains limited to two-dimensional (2D) CSA, and investigation of the relationship between muscle and disease using three-dimensional (3D) area of ESM has not been realized.
Automatic recognition of skeletal muscle using computed tomography (CT) images is divided into 2D and 3D based methods. Wei et al. [4] realized the atlas based method to recognize the ESM automatically. In addition, there is automatic recognition method of skeletal muscle using finite element method (FEM) [5]. We proposed a deep convolutional neural network (CNN) based method to automatically recognize the ESM in the 12th thoracic section and obtained an average Jaccard coefficient (JC) of \(82.4\%\) [6]. On the other hand, in the method based on 3D, the goal is to obtain a 3D region of skeletal muscle. We created a computational anatomical model imitating muscle running and realized automatic recognition of surface parts [7] and deep muscles [8]. Moreover, in the automatic recognition method of ESM using random forest, the average Dice coefficient (DC) was \(93.0\,{\pm }\,2.1\%\) [9]. In addition, Yokota et al. [10] realized automatic recognition of skeletal muscle in hip and femoral region by hierarchical multi-atlas method.
Analysis of diseases associated with the ESM [1,2,3] requires extracting a section corresponding to the level of the medullary node of the vertebrae. Furthermore, recognition of the anatomical attachment position of the skeletal muscle is important for generation of a computed anatomical model on the CT image and appropriate utilization of the model. Actually, in the creation of a muscle running model, the origin and insertion of each muscle is used [7, 8]. In addition, in recognition of skeletal muscle at the shoulder part, recognition accuracy was improved by utilizing the structural features of the scapula which is the attachment part of the muscle in model building [11]. Therefore, recognition of the anatomical attachment position information on the muscle on the skeleton is necessary for construction and utilization of the model, analysis of the relationship between muscle and disease, as well as muscle recognition.
In this study using 2D-deep CNN, we aim to acquire not only muscle recognition results, but also regional information of origin and insertion which becomes attachment area on the skeleton which is necessary for muscle analysis.

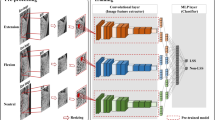
A network of automatic recognition of erector spinae muscle and its attached areas on the skeleton. In three-dimensional (3D) to two-dimensional (2D) image sampling, each section is extracted from the computed tomography image as input images. In 2D to 3D label voting, recognition results of each section are integrated into a 3D image. Details of the fully convolutional network are described in Fig. 2.
2 Method
2.1 Overview
The proposed method is based on the automatic recognition method of multiple organs in 3D CT images using deep CNN [12]. The outline of this method is shown in Fig. 1. The input image is a torso CT image, and the output image is a label image of the spinal column erector muscle and the attached region on the skeleton. First, 2D images of three anatomical sections are obtained from input CT images. Thereafter, each 2D cross-sectional image is input to deep CNN, and region recognition is performed on each 2D cross-sectional image. Finally, recognition results in each obtained cross section are integrated as 3D images using label probabilities. A fully convolutional network (FCN) [13] is used for region recognition in the 2D section. In the training process in FCN, a CT image and a ground truth image obtained by extracting ESM and attachment areas on the skeleton of the ESM are used.
2.2 3D to 2D Image Sampling and 2D to 3D Label Voting
In our proposed method, 2D cross-sectional images are generated from 3D CT images as input images. Then, the ESM which is a target region in the 2D cross section and its attached region are recognized, and finally the recognition result in each cross section is reconstructed into a 3D image. It should be noted that each voxel on the 3D CT image belongs to a plurality of 2D cross-sectional images. In other words, by recognizing a target region with respect to a 2D image of a plurality of cross sections, it is aimed at enhancing recognition accuracy by performing label prediction a plurality of times for each voxel. Here, 2D images of three orthogonal cross sections, axial, coronal and sagittal, are created. As a result, each voxel is always arranged in three 2D images. After region recognition using 2D images, each voxel obtains three recognition results for each section. The result of recognition of each section is integrated into a 3D image using majority voting. The final label is determined by the maximum value of the product of the probabilities of each cross section.

Fully convolutional network structure of our proposed method (K: kernel size, S: stride).
2.3 ESM and Its Attachment Region Segmentation Using FCN
In this method, FCN is used in order to perform region recognition in 2D images of each section generated from a 3D image. The structure of FCN is composed of two layers, which are down sampling layer and up sampling layer, respectively. First, abstract information is extracted in the down sampling layer, and in the latter half of the up sampling layer, labels are predicted in pixel units. Each parameter of FCN is optimized by learning.
Figure 2 shows the FCN structure used in the proposed method. The down sampling layer consists of sixteen \(3\,{\times }\,3\) convolution layers, five pooling layers and three full connected layers based on the network structure of VGG 16 [14]. In the FCN, the full connected layer in VGG 16 is replaced by a convolution layer. The last \(1\,{\times }\,1\) convolution layer sets the number of labels classified channels. In this method, it is the three regions of the background, the ESM and its attachment region on the skeleton. The up sampling layer is composed of three deconvolution layers and two convolution layer. This network has a skip structure that uses the information lost in the convolution layer of the VGG 16 in the deconvolution layer. The network with one deconvolution layer is called FCN-32s and learning of FCN is repeated with the addition of deconvolution layer to construct FCN-16s, FCN-8s. In this method, the output of FCN-8s is taken as the recognition result of the 2D image. The activation function uses a rectified linear unit (ReLU).
2.4 Input Label Image
In the learning process of the network, the original image and the ground truth image are used. For the ground truth image, manually segmented images are used. An example of the ground truth image is shown in Fig. 3. Figure 3(a) shows the whole ESM in a 3D representation. A pair of the muscles are present on both sides of the body. The middle diagram shows the attachment area on the skeleton. Here, in the dorsal side of the ribs and the transverse process of the thoracic vertebra, the area on the skeleton which is in attached with the muscle is defined as the ground truth. This corresponds to the origin and insertion of the iliopsoas muscle and the longissimus muscle among the muscles constituting the ESM. In the learning process, the ESM and the attachment region on the skeleton are learned at the same time. Figure 3(b) shows a cross section where the ground truth on the original CT.
3 Experiment
CT images used in this study are non-contrast torso CT images taken by Light Speed Ultra 16 (manufactured by General Electric) at Gifu University Hospital, Japan. All the data have an isotropic voxel resolution of 0.625 mm. The size of the data ranges from \(512\,{\times }\,512\,{\times }\,802\) voxels to \(512\,{\times }\,512\,{\times }\,1031\) voxels. Eleven cases were used for the experiment and evaluated by the leave-one-out method. In learning, we used VGG 16’s model trained with ImageNet ILSVRC-2014 data set [14] as a preliminary learning model. The DC, JC, recall rate and precision rate are used to evaluate recognition results of spinal column erector muscle and attached region on the skeleton.
For the implementation environment, the GPU uses 12 GB of NVIDIA GeForce TITAN - X, and the framework uses Caffe.

Ground truth image. (a) Erector spinae muscle (green) and skeleton (gray). (b) Muscle attachment region on the skeleton (red). (c) Erector spinae muscle (green) and its attachment region on the skeleton (red). (Color figure online)
4 Results
Recognition results of ESMs in 11 cases are shown in Table 1. The mean JC of ESM recognition result was \(81.7\,{\pm }\,3.2\%\), and the average DC was \(89.9\,{\pm }\,2.0\%\). The average JC of recognition results of the ESM on the twelfth thoracic vertebra section was \(85.6\,{\pm }\,3.7\%\), and the average DC was \(92.2\,{\pm }\,2.2\%\). In addition, Table 2 shows the recognition result of the attachment region on the skeleton. The average JC of the recognition result of the attachment area on the skeleton was \(48.8\,{\pm }\,3.7\%\), and the average DC was \(65.5\,{\pm }\,3.3\%\). Figure 4 shows an example of the recognition result in 2D, and Fig. 5 shows the recognition result in 3D.

Example of the recognition result in two-dimensional cross sections. (a) Original computed tomography images. (b) Ground truth images. (c) Recognition results.

(a) Ground truth. (b) Recognition result.
5 Discussion
The automatic recognition result of the ESM using 2D-deep CNN achieved an average DC of \(89.9\,{\pm }\,2.0\%\). The achieved accuracy is slightly worse than that achieved by our random forest based ESM recognition method [9]. Although both methods used the same training dataset, we attribute the less accurate results to the fact that deep CNN requires more learning cases as compared with conventional machine learning methods. On the other hand, the mean JC in the 12th thoracic vertebral section of this method was \(85.6\,{\pm }\,3.7\%\). This is a high recognition accuracy compared with the average Jaccard coefficient of \(82.4\%\) in the automatic recognition method of the ESM in the 12th thoracic section using deep CNN in our previous study [6]. In this study, we consider not only the learning of the axial cross section but also the sagittal and the coronal sections, so in large skeletal muscle such as the ESM, learning process using both coronal and sagittal section is effective. Although the numerical value of the muscle attachment accuracy is low, as shown in Figs. 4 and 5, the origin and insertion region is well recognized. The anatomical attachment site of skeletal muscle is one of the essential elements for orthopedic intervention and is important as well as recognition of skeletal muscle region.
In the next step, it is necessary to conduct a large-scale experiment with an increased number of cases and to verify the ESM recognition accuracy in deep CNN. However, it is not easy to create many ground truth of large and complex skeletal muscles such as the ESM. Therefore, it is necessary to efficiently generate a learning image in deep CNN by using our method using high speed and high performance random forest [9].
6 Conclusion
In this study, automatic recognition of ESMs and its attachment region on the skeleton in torso CT image by using deep CNN was performed. As a result of the leave-one-out cross validation test using eleven cases, the average Dice coefficient of ESM was \(89.9\,{\pm }\,2.0\%\). In the 12th thoracic vertebra, the mean Jaccard coefficient was \(85.6\,{\pm }\,3.7\%\). This result shows that automatic recognition is realized with high coincidence ratio in clinically important two-dimensional cross section, and it is a result that enables quantitative analysis by 3D. Although numerical recognition accuracy was low, simultaneous automatic recognition of the skeletal muscle and its anatomical attachment site, origin and insertion, was realized. For future work, we aim to clarify the relationship of 3D ESM using the recognized muscle region and its attachment position on the skeleton.
References
Danneels, L., Vanderstraeten, G., Cambier, D., Witvrouw, E., De Cuyper, H., Danneels, L.: CT imaging of trunk muscles in chronic low back pain patients and healthy control subjects. Eur. Spine J. 9(4), 266–272 (2000). https://doi.org/10.1007/s005860000190
Yagi, M., Hosogane, N., Watanabe, K., Asazuma, T., Matsumoto, M.: The paravertebral muscle and psoas for the maintenance of global spinal alignment in patient with degenerative lumbar scoliosis. Spine J. 16(4), 451–458 (2016). https://doi.org/10.1016/j.spinee.2015.07.001
Tanimura, K., et al.: Quantitative assessment of erector spinae muscles in patients with chronic obstructive pulmonary disease. Novel chest computed tomography-derived index for prognosis. Ann. Am. Thorac. Soc. 13(3), 334–341 (2016). https://doi.org/10.1513/AnnalsATS.201507-446OC
Wei, Y., Xu, B., Tao, X., Qu, J.: Paraspinal muscle segmentation in CT images using a single atlas. In: Proceedings of IEEE International Conference on Progress in Informatics and Computing – PIC 2015, pp. 211–215. IEEE (2015). https://doi.org/10.1109/PIC.2015.7489839
Popuri, K., Cobzas, D., Esfandiari, N., Baracos, V., Jägersand, M.: Body composition assessment in axial CT images using FEM-based automatic segmentation of skeletal muscle. IEEE Trans. Med. Imaging 35(2), 512–520 (2016). https://doi.org/10.1109/TMI.2015.2479252
Kume, M., et al.: Automated recognition of the erector spinae muscle based on deep CNN at the level of the twelfth thoracic vertebrae in torso CT images. In: Proceedings of 36th JAMIT Annual Meeting, pp. 74–76 (2017)
Kamiya, N., et al.: Automated segmentation of recuts abdominis muscle using shape model in X-ray CT images. In: Proceedings of 33rd Annual International Conference of the IEEE Engineering in Medicine and Biology Society – EMBC 2011, pp. 7993–7996. IEEE (2011). https://doi.org/10.1109/IEMBS.2011.6091971
Kamiya, N., et al.: Automated segmentation of psoas major muscle in X-ray CT images by use of a shape model: preliminary study. Radiol. Phys. Technol. 5(1), 5–14 (2012). https://doi.org/10.1007/s12194-011-0127-0
Kamiya, N., Li, J., Kume, M., Fujita, H., Shen, D., Zheng, G.: Fully automatic segmentation of paraspinal muscles from 3D torso CT images via multi-scale iterative random forest classifications. In: Proceedings of 32nd International Congress and Exhibition on Computer Assisted Radiology and Surgery - CARS 2018, pp. 18–00047 (2018)
Yokota, F., et al.: Automated muscle segmentation from CT images of the hip and thigh using a hierarchical multi-atlas method. Int. J. Comput. Assist. Radiol. Surg. 13(7), 977–986 (2018). https://doi.org/10.1007/s11548-018-1758-y
Katafuchi, T., et al.: Improvement of supraspinatus muscle recognition methods based on the anatomical features on the scapula in torso CT image. In: Proceedings of International Forum on Medical Imaging in Asia - IFMIA, pp. 315–316 (2017)
Zhou, X., Ito, T., Takayama, R., Wang, S., Hara, T., Fujita, H.: Three-dimensional CT image segmentation by combining 2D fully convolutional network with 3D majority voting. In: Carneiro, G., et al. (eds.) LABELS/DLMIA -2016. LNCS, vol. 10008, pp. 111–120. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46976-8_12
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition – CVPR 2015, pp. 3431–3440. IEEE (2015). https://doi.org/10.1109/CVPR.2015.7298965
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556 (2015)
Acknowledgements
This research was supported in part by a Grant-in-Aid for Scientific Research on Innovative Areas (Grant No. 26108005 and 17H05301), MEXT, Japan.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Kamiya, N. et al. (2019). Automated Recognition of Erector Spinae Muscles and Their Skeletal Attachment Region via Deep Learning in Torso CT Images. In: Vrtovec, T., Yao, J., Zheng, G., Pozo, J. (eds) Computational Methods and Clinical Applications in Musculoskeletal Imaging. MSKI 2018. Lecture Notes in Computer Science(), vol 11404. Springer, Cham. https://doi.org/10.1007/978-3-030-11166-3_1
Download citation
DOI: https://doi.org/10.1007/978-3-030-11166-3_1
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-11165-6
Online ISBN: 978-3-030-11166-3
eBook Packages: Computer ScienceComputer Science (R0)