
Abstract
Limiting the model size of a kernel support vector machine to a pre-defined budget is a well-established technique that allows to scale SVM learning and prediction to large-scale data. Its core addition to simple stochastic gradient training is budget maintenance through merging of support vectors. This requires solving an inner optimization problem with an iterative method many times per gradient step. In this paper we replace the iterative procedure with a fast lookup. We manage to reduce the merging time by up to \(65\%\) and the total training time by \(44\%\) without any loss of accuracy.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
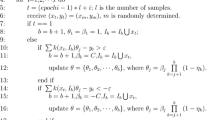


Notes
- 1.
- 2.
Note that with increasing number of passes (or epochs) the standard deviation does not tend to zero since the training problem is non-convex due to the budget constraint.
References
Bottou, L., Lin, C.J.: Support Vector Machine Solvers, pp. 1–28. MIT Press, Cambridge (2007)
Bottou, L.: Large-scale machine learning with stochastic gradient descent. In: Lechevallier, Y., Saporta, G. (eds.) COMPSTAT 2010, pp. 177–186. Physica-Verlag, Heidelberg (2010). https://doi.org/10.1007/978-3-7908-2604-3_16
Burges, C.J.: Simplified support vector decision rules, pp. 71–77. Morgan Kaufmann (1996)
Chang, C.C., Lin, C.J.: LIBSVM: a library for support vector machines. ACM Trans. Intell. Syst. Technol. 2, 27 (2011)
Cortes, C., Vapnik, V.: Support-vector networks. Mach. Learn. 20(3), 273–297 (1995)
Cui, J., Li, Z., Lv, R., Xu, X., Gao, J.: The application of support vector machine in pattern recognition. IEEE Trans. Control Autom. (2007)
Fine, S., Scheinberg, K.: Efficient SVM training using low-rank kernel representations. J. Mach. Learn. Res. 2(Dec), 243–264 (2001)
Graf, H.P., Cosatto, E., Bottou, L., Dourdanovic, I., Vapnik, V.: Parallel support vector machines: the cascade SVM. In: NIPS (2005)
Hare, S., et al.: Struck: structured output tracking with kernels. IEEE Trans. Pattern Anal. Mach. Intell. 38(10), 2096–2109 (2016)
Hsieh, C.J., Chang, K.W., Lin, C.J., Keerthi, S.S., Sundararajan, S.: A dual coordinate descent method for large-scale linear SVM. In: ICML (2008)
Hsieh, C.J., Si, S., Dhillon, I.: A divide-and-conquer solver for kernel support vector machines. In: International Conference on Machine Learning (ICML), pp. 566–574 (2014)
Joachims, T.: Text categorization with support vector machines: learning with many relevant features. In: Nédellec, C., Rouveirol, C. (eds.) ECML 1998. LNCS, vol. 1398, pp. 137–142. Springer, Heidelberg (1998). https://doi.org/10.1007/BFb0026683
Joachims, T.: Making large-scale SVM learning practical. In: Advances in Kernel Methods - Support Vector Learning. MIT Press, Cambridge (1999)
Ladicky, L., Torr, P.: Locally linear support vector machines. In: International Conference on Machine Learning (ICML), pp. 985–992 (2011)
Lewis, D.P., Jebara, T., Noble, W.S.: Support vector machine learning from heterogeneous data: an empirical analysis using protein sequence and structure. Bioinformatics 22(22), 2753–2760 (2006)
Lin, G., Shen, C., Shi, Q., van den Hengel, A., Suter, D.: Fast supervised hashing with decision trees for high-dimensional data. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2014)
Mohri, M., Rostamizadeh, A., Talwalkar, A.: Foundations of Machine Learning. MIT Press, Cambridge (2012)
Nguyen, D., Ho, T.: An efficient method for simplifying support vector machines. In: Proceedings of the 22nd ICML, pp. 617–624 (2005)
Noble, W.S.: Support vector machine applications in computational biology. In: Schölkopf, B., Tsuda, K., Vert, J.P. (eds.) Kernel Methods in Computational Biology. MIT Press, Cambridge (2004)
Rahimi, A., Recht, B.: Random features for large-scale kernel machines. NIPS 3(4) (2007)
Schölkopf, B., et al.: Input space versus feature space in kernel-based methods. IEEE Trans. Neural Netw. 10(5), 1000–1017 (1999)
Shalev-Shwartz, S., Singer, Y., Srebro, N., Cotter, A.: Pegasos: primal estimated sub-GrAdient SOlver for SVM. Math. Program. 127(1), 3–30 (2011)
Steinwart, I.: Sparseness of support vector machines. J. Mach. Learn. Res. 4(Nov), 1071–1105 (2003)
Vapnik, V.: The Nature of Statistical Learning Theory. Springer, New York (1995). https://doi.org/10.1007/978-1-4757-2440-0
Wang, Z., Crammer, K., Vucetic, S.: Breaking the curse of kernelization: budgeted stochastic gradient descent for large-scale SVM training. J. Mach. Learn. Res. 13, 3103–3131 (2012)
Wen, Z., Shi, J., He, B., Li, Q., Chen, J.: Thunder-SVM (2017). https://github.com/zeyiwen/thundersvm
Mu, Y., Hua, G., Fan, W., Chang, S.F.: Hash-SVM: scalable kernel machines for large-scale visual classification. In: IEEE Conference on Computer Vision and Pattern Recognition (2014)
Yu, J., Xue, A., Redei, E., Bagheri, N.: A support vector machine model provides an accurate transcript-level-based diagnostic for major depressive disorder. Transl. Psychiatry 6(10), e931 (2016). https://doi.org/10.1038/tp.2016.198
Zanni, L., Serafini, T., Zanghirati, G.: Parallel software for training large scale support vector machines on multiprocessor systems. J. Mach. Learn. Res. 7, 1467–1492 (2006)
Zhang, H., Berg, A.C., Maire, M., Malik, J.: SVM-KNN: discriminative nearest neighbor classification for visual category recognition. In: Conference on Computer Vision and Pattern Recognition, vol. 2, pp. 2126–2136. IEEE (2006)
Zhang, K., Lan, L., Wang, Z., Moerchen, F.: Scaling up kernel SVM on limited resources: a low-rank linearization approach. In: AISTATS (2012)
Zhang, T.: Solving large scale linear prediction problems using stochastic gradient descent. In: International Conference on Machine Learning (2004)
Zhu, Z.A., Chen, W., Wang, G., Zhu, C., Chen, Z.: P-packSVM: parallel primal gradient descent kernel SVM. In: IEEE International Conference on Data Mining (2009)
Acknowledgments
We acknowledge support by the Deutsche Forschungsgemeinschaft (DFG) through grant GL 839/3-1.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Glasmachers, T., Qaadan, S. (2019). Speeding Up Budgeted Stochastic Gradient Descent SVM Training with Precomputed Golden Section Search. In: Nicosia, G., Pardalos, P., Giuffrida, G., Umeton, R., Sciacca, V. (eds) Machine Learning, Optimization, and Data Science. LOD 2018. Lecture Notes in Computer Science(), vol 11331. Springer, Cham. https://doi.org/10.1007/978-3-030-13709-0_28
Download citation
DOI: https://doi.org/10.1007/978-3-030-13709-0_28
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-13708-3
Online ISBN: 978-3-030-13709-0
eBook Packages: Computer ScienceComputer Science (R0)