
Abstract
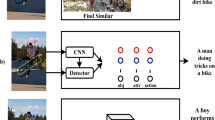
Image captioning is gaining attention due to the recent developments in the deep neural architectures. But the gap between semantic concepts and the visual features is a major challenge in image caption generation. In this paper we have developed a method to use both visual features and semantic features for the caption generation. We discuss briefly about the various architectures used for visual feature extraction and Long Short Term Memory (LSTM) for caption generation. An object recognition model has been developed to identify the semantic tags in the images. These tags are encoded along with the visual features for the captioning task. We have developed an Encoder-Decoder architecture using the semantic details along with the language model for the caption generation. We evaluated our model with standard datasets like Flickr8k, Flickr30k and MSCOCO using standard metrics like BLEU and METEOR.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Jaing, W., Ma, L., Chen, X., Zhang, H., Liu, W.: Learning to guide decoding for image captioning. In: Thirty Second AAAI Conference on Artificial Intelligence (AAAI – 2018), pp. 6959–6966 (2018)
Kinghorn, P., Zhang, L., Shao, L.: A hierarchical and regional deep learning architecture for image description generation. Pattern Recogin. Lett. 119, 1–9 (2017)
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft COCO: common objects in context. In: Computer Vision–ECCV 2014, pp. 740–755 (2014)
Tariq, A., Foroosh, H.: A context - driven extractive framework for generating realistic image descriptions. IEEE Trans. Image Process. 26(2), 619–632 (2017)
Pennington, J., Socher, R., Manning, C.D.: GloVe: global vectors for word representation (2014)
Plummer, B.A., Wang, L., Cervantes, C.M., Caicedo, J.C., Hockenmaier, J., Lazebnik, S.: Flickr30k entities: collecting region-to-phrase correspondences for richer image-to-sentence models. IJCV 123(1), 74–93 (2017)
Zhou, B., Lapedriza, A., Xiao, J., Torralba, A., Oliva, A.: Learning deep features for scene recognition using places database. In: Proceedings Advantages Neural Information Processing Systems, pp. 487–495 (2014)
Gan, Z., Gan, C., He, X., Pu, Y.: Semantic compositional networks for visual captioning. In: CVPR, pp. 1–10 (2017)
Yao, T., Pan, Y., Li, Y., Mei, T.: Incorporating copying mechanism in image captioning for learning novel objects. In: CVPR, pp. 6580–6588 (2017)
Vinyals, O., Toshev, A., Bengio, S., Erhan, D.: Show and tell: a neural image caption generator. In: CVPR (2015)
Mao, J., Xu, W., Yang, Y., Wang, J., Huang, Z., Yuille, A.: Deep captioning with multimodal recurrent neural networks. In: ICLR (2015)
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhutdinov, R., Zemel, R.S., Bengio, Y.: Show, attend and tell: neural image caption generation with visual attention. In: ICML (2015)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Aravindkumar, S., Varalakshmi, P., Hemalatha, M. (2020). Generation of Image Caption Using CNN-LSTM Based Approach. In: Abraham, A., Cherukuri, A.K., Melin, P., Gandhi, N. (eds) Intelligent Systems Design and Applications. ISDA 2018 2018. Advances in Intelligent Systems and Computing, vol 940. Springer, Cham. https://doi.org/10.1007/978-3-030-16657-1_43
Download citation
DOI: https://doi.org/10.1007/978-3-030-16657-1_43
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-16656-4
Online ISBN: 978-3-030-16657-1
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)