
Abstract
Words changing their meanings over time reflects various shifts in socio-cultural attitudes and conceptual structures. Understanding semantic change of words over time is important in order to study models of language and cultural evolution. Word embeddings methods such as PPMI, SVD and word2vec have been evaluated in recent years. These kinds of representation methods, sometimes referring as semantic maps of words, are able to facilitate the whole process of language processing. Chinese language is no exception. The development of technology gradually influences people’s communication and the language they are using. In the paper, a huge amount of data (300 GB) is provided by Sogou, a Chinese web search engine provider. After pre-processing, the Chinese language corpus is obtained. Three different word representation methods are extended to including temporal information. They are trained and tested based on the above dataset. A thorough analysis (both qualitative and quantitative analysis) is conducted with different thresholds to capture different semantic accuracy and alignment quality of the shifted words. A comparison between three methods is provided and possible reasons behind experiment results are discussed.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Using neural network for word embedding learning was first proposed as NNLM (Neural Network Language Model) [1]. Since then, word embedding methods have been proved to have excellent results in semantic analysis tasks [13]. It is evident that embedding is not only able to catch statistical information but syntactic information as well. Complex linguistic problems, such as exploring semantic change of words in discrete time periods [8] can thus be tackled properly. Moreover, embedding methods were used to detect large scale linguistic change-points [9] as well as to seek out regularities in acquiring language, such as related words tending to undergo parallel change over time [15].
Word2vec is typical low dimensional (usually from 50 to 300) word embedding method based on neural network, while SVD (Singular Value Decomposition) is a typical low dimensional word representation method based on matrix decomposition. These methods have achieved the state-of-the-art results in many diachronic analysis tasks [4, 5, 10] and diachronic-based applications [3, 16]. However, due to the inconsistent context and the stochastic nature of the above embedding methods, words in different periods cannot be easily encoded into the same vector space [6]. Also, due to the absence of Chinese historical corpus [6], currently diachronic analysis on Chinese is not studied well. The previous work normally encoded words from different time periods into separate vector spaces first, and then aligned the learned low-dimensional embeddings [9]. The inherent uncertainty of embeddings will lead to high variability of a given word’s closest neighbors [7]. The alignment approximates the relationship among vector spaces and forcibly consolidates inconsistent contexts onto a common context that will augment neighbor words’ variability. Moreover, as the pair of word context fluctuates over time, the forcible consolidation will tamper word semantics undesirably.
The problem of alignment can be avoided by not encoding words to low-dimensional space [8]. Among them, the Positive Point-wise Mutual Information (PPMI) [14] outperforms a wide variety of other high-dimensional approaches [2]. PPMI naturally aligns word vectors by constructing a high-dimensional sparse matrix, with each row representing a unique word, and each column corresponding to it’s context. Unfortunately, compared with low dimensional methods, PPMI introduces additional problems. In particular, building the PPMI matrix will consume a lot of computing resources in high-dimensional sparse environment. Though PPMI wards off alignment issues, it does not enjoy the advantages of low dimensional embeddings such as higher efficiency and better generalization.
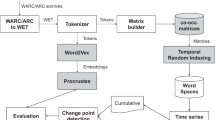
In this paper, we first introduce three popular word representation methods, the PPMI, PPMI-based SVD and word2vec. Then we will introduce the experiment setup, including the data, data preprocessing and the evaluation metrics. Finally we will discuss the experiment results, the application of word diachronic analysis on Chinese and future works.
2 Related Work
Many contributions about word representation have been done by other researchers. In this paper, we mainly use three word representation methods. We choose PPMI as our sparse word representation method, which makes use of word co-occurrence information as its vector. We choose PPMI-based SVD and word2vec as our low-dimension word representation methods. The PPMI-based SVD can take the advantage of co-occurrence information and frequency information in the PPMI matrix. The word2vec can be considered as a neural network based word representation method which can take the advantage of the nonlinear expression ability of neural networks. We will introduce these three methods in detail in the following sections.
2.1 PPMI
In the PPMI, words are represented by constructing a high dimensional sparse matrix \(M \in R^{|V_w| \times |V_c|}\) where each row denotes a word w, and each column represents a context c. The value of the matrix cell \(M_{ij}\) is the PPMI value that suggests the associated relationship between the word \(w_i\) and the context \(c_j\), the value of matrix cell \(M_{ij}\) is obtained by:
2.2 PPMI-Based SVD
SVD embeddings implement dimensionality reduction over a sparse high-dimensional matrix S, of which each row represents a word and each column corresponds to a potential feature of the word. More concretely, SVD decomposes the sparse matrix S into the product of three matrices, \(S = U \cdot V \cdot T\), where both U and T are orthonormal, and V is a diagonal matrix of singular values ordered in the decent direction. In V, the top limited number of singular values retain most features of the word, that is, by keeping the top d singular values, we have \(S_d = U_d \cdot V_d \cdot T_d\) which approximates S, then the word embedding \(\overrightarrow{W}\) is approximated by:
2.3 Word2vec
Bengio et al. [1] mentioned that language neural network model can be used in other ways to reduce the number of training parameters, such as recurrent neural networks. In order to quickly obtain a good word vector set, Mikolov et al. [12] invented a word vector training tool named word2vecFootnote 1. It includes two models: the CBOW (Continuous Bag-Of-Word) model and the Skip-gram (continuous Skip-gram) model.
Both models are feed-forward neural network models, without the nonlinear hidden layer of the neural language model in [1]. This modification greatly simplified model structure and reduced training time.
In this paper, we use Skip-gram model as word2vec training model. Given an intermediate word \(w_t\) as the priori knowledge to predict the context of the other words, the training process of the Skip-gram model is implemented by maximizing the value of \(W_{t+j}\) in Eq. (4).
where |V| denotes the size of word dictionary obtained from the training corpus, c represents the number of context words before or after the middle word. p(.) is a softmax regression function shown as Eq. (5):

where \(v_w\) and \(v_w'\) are the vector representations for the input layer and the output layer respectively.
In this paper, we use Skip-gram model with negative-sampling from word2vec (in this paper, we name it as SGNS), which is a fast and effective method to build a word representation.
2.4 Detect Diachronic Changes
We detect semantic change-point of the word by measuring the semantic similarity of its two profiles in respective time periods. The measure is as follows:
where cos() calculates the cosine similarity of two vectors, which is between [0, 1]. \(w^{x1}\) and \(w^{x2}\) are profiles referring to exactly the same word w but appearing in periods of x1 and x2, respectively. Smaller value means more significant difference, that is, the meaning of word shifts greatly over time. We measure the semantic difference of a specific word at every two periods.
2.5 Alignment Method
In order to compare word vectors from different time-periods, we must align the vectors from different time-periods. The PPMI is naturally aligned, but PPMI-based SVD and word2vec is not naturally aligned, these two method may result in arbitrary orthogonal transformations. According to [6], we use orthogonal Procrustes to align the learned word representations. Suppose \(W^{(t)} \in \mathbb {R}^{d \times |V|}\) as the matrix of word embeddings learned at year t. We align the embeddings by optimizing:
3 Experiment Results
3.1 Preprocessing
Dataset. In this paper, we use a large set of search engine crawled web pages provided by Sogou Lab [11]. Provided data is organized as XML style label texts. The data is raw XML labeled data and has no time tag in labels. After we analyzed the data, we found that the URL of every document may contain time information (this usually occurs in news sites). So, in this experiment, we use the URL provided time information.
To extract the time information from document data, we use regex to match time pattern like “YYYY-MM-DD” or “YYYY_MM_DD” in url, urls without this pattern will be deleted. Then we apply a filter that can clean all html labels and other useless symbols to build the final training corpus.
The word segmentation tool jiebaFootnote 2 is applied for Chinese word segmentation (including the compound words).
After these preprocessing, we finally get about 52,324,791 lines of data consisting 467,826,233 words (225,182 unique words).
3.2 Number of Discovered Shift Words
The detection of linguistic change is shown by searching for semantically shifting words among time-periods and how many such kind of words are identified clearly in a given time slot. Two corpora, “Corpus 1998-2002” and “Corpus 2008-2012” are picked up because the two of 5-year range may exhibit the semantic shifting of the development process of Internet in China. We compare the semantic similarity of word vectors between two periods of time for each word. Moreover, in order to build a comprehensive understanding of the linguistic change, we identify shifting words with five different thresholds (the semantic similarities thresholds are set to 0.1, 0.2, 0.3, 0.4 and 0.5, respectively). The results are shown in Table 1. It is PPMI that detects the largest number of shifting words under the same conditions. From the Table 1. We can also find that the number of detected words of PPMI, SVD and SGNS are mainly distributed under 0.1, 0.4 and 0.5. This shows a interesting fact that the result of these three method have different distribution.
3.3 Visualizing Semantic Evolution of Words
We select some semantic changed words in the corpus generated by our methods, visualize them in three periods (1998–2002, 2003–2007 and 2008–2012). To draw the visualization for a given semantic-changed word, we extract words which are semantically similar neighbors in each period, placing them around the word at different distances according to the vector distance between the word and its neighbors. The visualization of semantic changed words are shown in Figs. 1 and 2. In Fig. 1, we can find that the meaning of “copy” in Chinese changes its mean at about 2008–2012, moving towards “arena” in English. In Fig. 2, we can find that the meaning of “apple” in Chinese changes its mean at about 2003–2007, moving towards to “Apple Inc.” in English.

Visualization of “copy” in Chinese

Visualization of “apple” in Chinese
3.4 Discussions
Here we will discuss about three problems in our diachronic analysis result:
-
How to find the representation of the semantically active words, given that they may change in meaning over time.
-
How to judge a historical word embedding method is effective quantitatively.
-
How to find a relationship between diachronic shift words, linguistic evolution and social changes.
As discussed in Sect. 1, words from different time periods cannot be easily projected into the same dense vector space. Suppose now they are directly represented in a single dense vector space, what would we do to trace their semantic change? Even though every word has a different profile in each corpus, together they have to be represented by one unique vector. That is, it remains unchanged in the varying time period and sensitive context of the word. Also, the word embeddings learn word representations in global which can also make polysemous words not stable. So it’s still a problem need further study.
In this paper, we use different word distance thresholds to find the shifted words. As lack of ground truth data to reveal known word shifts, this may be a quantitative way to evaluate word embedding methods. But this kind of method is simple and inaccurate. A possible direction is to apply density analysis on word embedding results.
Also, as the result of our work, we can find the diachronic shift words, how to create a relationship between shift words, linguistic evolution and social changes is the next question. A possible direction is to design a global distance evaluation algorithm to embody the linguistic evolution, another possible direction is to use some social change event to analyze its relationship between shift words and social changes.
4 Conclusion and Future Work
Though low-dimensional method enjoy higher efficiency and better generalization, high-dimensional word representation methods still have its own advantages. In this paper, we use both high-dimensional and low-dimensional word representation method to build word vectors among time-periods. As current research have seldom work on Chinese corpus analysis, we use a large mount of data from Sogou search engine crawled pages to perform this analysis. After using three word representation method to train this Chinese corpus, we use different thresholds to get shifted words from the representation and visualize semantic evolution of words.
In the future, we mainly focus on research directions talked in discussion. The very next research topic is trying to reveal the relationship between word meaning shifts, linguistic evolution and social changes in Chinese corpus. We will also try to build a Chinese word shift ground truth data in order to achieve word shift evaluation quantitatively.
References
Bengio, Y., Ducharme, R., Vincent, P., Jauvin, C.: A neural probabilistic language model. J. Mach. Learn. Res. 3, 1137–1155 (2003)
Bullinaria, J.A., Levy, J.P.: Extracting semantic representations from word co-occurrence statistics: a computational study. Behav. Res. Methods 39(3), 510–526 (2007)
Garg, N., Schiebinger, L., Jurafsky, D., Zou, J.: Word embeddings quantify 100 years of gender and ethnic stereotypes. Proc. Nat. Acad. Sci. 115(16), E3635–E3644 (2018)
Grayson, S., Mulvany, M., Wade, K., Meaney, G., Greene, D.: Exploring the role of gender in 19th century fiction through the lens of word embeddings. In: Gracia, J., Bond, F., McCrae, J.P., Buitelaar, P., Chiarcos, C., Hellmann, S. (eds.) LDK 2017. LNCS (LNAI), vol. 10318, pp. 358–364. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-59888-8_30
Hamilton, W.L., Leskovec, J., Jurafsky, D.: Cultural shift or linguistic drift? Comparing two computational measures of semantic change. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing, vol. 2016, p. 2116. NIH Public Access (2016)
Hamilton, W.L., Leskovec, J., Jurafsky, D.: Diachronic word embeddings reveal statistical laws of semantic change. arXiv preprint arXiv:1605.09096 (2016)
Hellrich, J., Hahn, U.: Bad company—neighborhoods in neural embedding spaces considered harmful. In: Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, pp. 2785–2796 (2016)
Jatowt, A., Duh, K.: A framework for analyzing semantic change of words across time. In: IEEE/ACM Joint Conference on Digital Libraries (JCDL), pp. 229–238. IEEE (2014)
Kulkarni, V., Al-Rfou, R., Perozzi, B., Skiena, S.: Statistically significant detection of linguistic change. In: Proceedings of the 24th International Conference on World Wide Web, pp. 625–635. International World Wide Web Conferences Steering Committee (2015)
Levy, O., Goldberg, Y., Dagan, I.: Improving distributional similarity with lessons learned from word embeddings. Trans. Assoc. Computat. Linguist. 3, 211–225 (2015)
Liu, Y., Chen, F., Kong, W., Yu, H., Zhang, M., Ma, S., Ru, L.: Identifying web spam with the wisdom of the crowds. ACM Trans. Web (TWEB) 6(1), 2 (2012)
Mikolov, T., Chen, K., Corrado, G., Dean, J.: Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781 (2013)
Mikolov, T., Yih, W.t., Zweig, G.: Linguistic regularities in continuous space word representations. In: Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 746–751 (2013)
Turney, P.D., Pantel, P.: From frequency to meaning: vector space models of semantics. J. Artif. Intell. Res. 37, 141–188 (2010)
Xu, Y., Kemp, C.: A computational evaluation of two laws of semantic change. In: CogSci (2015)
Yan, E., Zhu, Y.: Tracking word semantic change in biomedical literature. Int. J. Med. Informatics 109, 76–86 (2018)
Acknowledgement
This work was supported by National Undergraduate Training Program for Innovation and Entrepreneurship (No. 201810635003), National Natural Science Foundation of China (No. 61877051) and CSTC funding (No. cstc2017zdcy-zdyf0366).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Xu, X., Cao, Y., Li, L. (2019). Exploring Semantic Change of Chinese Word Using Crawled Web Data. In: Bakaev, M., Frasincar, F., Ko, IY. (eds) Web Engineering. ICWE 2019. Lecture Notes in Computer Science(), vol 11496. Springer, Cham. https://doi.org/10.1007/978-3-030-19274-7_7
Download citation
DOI: https://doi.org/10.1007/978-3-030-19274-7_7
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-19273-0
Online ISBN: 978-3-030-19274-7
eBook Packages: Computer ScienceComputer Science (R0)