
Abstract
This paper presents a new method of image captioning, which generate textual description of an image. We applied our method for infant sleeping environment analysis and diagnosis to describe the image with the infant sleeping position, sleeping surface and bedding condition, which involves recognition and representation of body pose, activity and surrounding environment. In this challenging case, visual attention as an essential part of human visual perception is employed to efficiently process the visual input. Texture analysis is used to give a precise diagnosis of sleeping surface. The encoder-decoder model was trained by Microsoft COCO dataset combined with our own annotated dataset contains relevant information. The result shows it is able to generate description of the image and address the potential risk factors in the image, then give the corresponding advice based on the generated caption. It proved its ability to assist human in infant care-giving area and potential in other human assistive systems.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Sudden Infant Death Syndrome (SIDS) [1] has been a leading cause of death among babies younger than 1 year old. It is the sudden, unexplained death that even after a complete investigation [2], still hard to find a cause of the death. Although the exact cause of SIDS is still unknown, we can reduce the risk of SIDS and other Sleep-related causes of infant death by providing a safe infant sleeping environment.
Previous research was mostly about monitoring motion or physical condition of infants, but to the best of our knowledge there is no application for Sleep environment diagnosis yet. And considering the advice from American Academy of Pediatrics (AAP) [7] to reduce risk of SIDS is through provide a safe infant sleeping environment.
In our opinion, Sleep environment diagnosis is needed, to help parents or caregivers aware of risk factors and realize what can be improved. To this end, we proposed a system to help generate the analysis of infant sleeping position and sleeping environment. Given a photograph of the infant sleeping or just the sleeping environment, it can generate natural-language description of the analysis.
It is a process used both natural language processing and computer vision to generate textual description of an image. And can be viewed as a challenging task in scene understanding, as it not only need to express the local information as object recognition task do, it also need to show higher level of information, the relationship of local information. There has been a significant progress made in Image captioning recent years, with development of Deep Learning (CNN and LSTM) and large-scale datasets. Instead of performing object detection and organizing words in sequence, several encoder-decoder frameworks [3,4,5] used deep neural network trained end-to-end.
Visual Attention [6] is an essential part of human visual perception, it also plays an important role in understanding a visual scene by efficiently locate region of interest and analyze the scene by selectively processing subsets of visual input. This is especially important when the scene is cluttered with multiple elements, by dynamically process salient features it can help us better understand primary information of the scene.
In this paper, we describe the approach of generating the analysis of the infant sleeping environment, which incorporated visual attention model to efficiently to narrow down the search and speed up the process. Different from other image captioning task, which usually just aimed to give a general description of the scene, we also need more detailed information regarding to certain area of interest. In our case, the bedding condition is essential for the analysis, we extracted image’s texture feature to conduct analysis.
The contributions of this paper are the following: We introduced a new framework of image captioning in special case to help diagnosis and analysis the infant sleeping environment, both low and high level of visual information were used to give a caption that not only shows the relation of visual elements, but also give the detailed information of the certain area of interest. We validated our method on the real-world data, which shows the satisfactory performance.
2 Related Work
2.1 Image Captioning
Recently, image captioning has been a field of interest for researchers in both academia and industry [10,11,12]. Some classic models are mainly template-based [24,25,26] methods, combine detected words from visual input and sentence fragments to generate the sentence using pre-defined templates. These methods are limited in generating variety of words, could not achieve a satisfactory performance. With the development of deep learning and inspired by the sequence to sequence training with neural network used in machine translation problem, Karpathy et al. [11] proposed to align sentence snippets to the visual regions by computing a visual-semantic similarity score. Vinyals et al. [13] used LSTM [18] RNNs for their model. They used CNN to encode image then passed to LSTM to encode sentences.
2.2 Visual Attention
The visual attention models are mainly categorized into Bottom-up models and top-down models [6]. Bottom-up attention models are based on the image feature of the visual scene. Such as histogram-based contrast (HC) and region-based contrast (RC) algorithm proposed in [15]. Top-down attention models are driven by the observer’s prior knowledge and current goal. Minh et al. proposed recurrent attention model (RAM) [16] to mimic human attention and eye movement mechanism, to predict future eye movements and location to see at next time step. Based on RAM, recurrent visual attention model (DRAM) [17] was proposed to expand it for multiple object recognition by exploring the image in a sequential manner with attention mechanism, then generate a label sequence for multiple objects. Xu et al. [14] introduced an attention-based model to generate neural image caption, a generative LSTM can focus on different attention regions of the visual input while generating the corresponding caption. It has two variants: stochastic “hard” attention, trained by maximizing a variational lower bound through the reinforcement learning, and deterministic “soft” attention, trained using standard back-propagation techniques.
3 Background and Requirement
American Academy of Pediatrics (AAP) Task Force on SIDS recommend place infant in a supine position, [7] let them wholly sleep on their back until 1 year of age. Research shows that the back-sleeping position carries the lowest risk of SIDS. Side sleeping is nor safe and not advised.
And it’s necessary to use a firm sleep surface covered by a fitted sheet without other bedding and soft objects, keep soft objects such as pillow or comforters and loose bedding such as blanket away from the sleep area.
It also recommended that infants should share the bedroom, but sleep on a separate surface designed for baby. Room-sharing but no bed-sharing removes the possibility of suffocation, strangulation, and entrapment that may occur when the infant is sleeping in the adult bed.
In the past, there had been a lot of research or devices developed for safety of infant, such as smart baby monitor [8], equipped with camera, microphone and motion sensor, so that parents can stream on their mobile devices and get to know the baby’s sleeping patterns. Home apnea monitor were also used for similar purposes [9], monitoring infant’s heart rate and oxygen level.
Although these seems helpful and make monitoring infant easier, AAP still advised not to use home cardiorespiratory monitors as a strategy to reduce the risk of SIDS, as it hasn’t shown scientific evidence to decrease the incidence of SIDS.
In short, in this case, we should analyze the infant sleeping position, bedding condition and soft objects to help diagnose the infant sleeping environment.
4 Approach
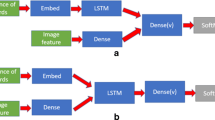
In this section, we describe our algorithm and the proposed architecture (Fig. 1).

Architecture of the model, (\( \alpha_{\text{t}} \): attention vector, a: annotation vector, x: texture vector. \( \varvec{z}_{\text{t}} \): context vector, \( \varvec{h}_{\text{t}} \): hidden state, \( \varvec{y}_{\text{t}} \): generated sentence)
4.1 Encoder
We first encode input image I to a sequence of words. Normalize the input image to size of 224 × 224. VGG net [22] was used to generate D-dimensional annotation vectors ai, which describe different local region of the image. Without losing detailed local information, features by 14 × 14 × 512 dimension from Conv5_3 layer was used here.
We employ Soft attention [14] to generate D-dimensional context vector \( \hat{\varvec{z}}_{t} \). Context \( \hat{\varvec{z}}_{t} \) of Current step is weighted sum of previous context by weight of \( \alpha_{\text{t}} \), which measures how much attention gain in each pixel:
\( \alpha_{t} \) can be derived from hidden state \( h_{t} \) of previous time step.
\( e_{{\text{ti}}} \) stores information from previous time step where \( f_{att} \) is attention model.
4.2 Texture Analysis
Texture are also important in our analysis, to get a detailed description of the bedding area, we also extract texture feature to train our model. Gray Level Cooccurrence Matrix (GLCM) [19] is used to characterize the texture by quantifying differences between neighboring pixel values (vertically or horizontally) within a specified window of interest. Suppose the gray level has been quantized to \( N_{g} \) Levels [21]. GLCM defines a square matrix whose size is equal to the \( N_{g} \). \( P_{\text{ij}} \) in the location (i, j) of the matrix means the co-occurrence probability for co-occurring pixels with gray levels i and j. The GLCM features used were listed in table. Energy measures local uniformity. Contrast measures the local variations. Entropy reflects the degree of disorder in an image. Homogeneity Measures the closeness of the distribution of elements [21]. We extracted GLCM matrices using 4 different offsets (1, 2, 3 and 4 pixels) and phases (0°, 45°, 90°, 135°). SVM (support vector machines) [28] are used for classification of different texture classes (Table 1).
4.3 Decoder
To generate the hidden state, we used LSTM [18] to simulate the memory of every time step based on context vector, previous hidden state and previous generated word. \( \varvec{i}_{t} \), \( \varvec{f}_{t} \), \( \varvec{c}_{t} \), \( \varvec{o}_{t} \), \( \varvec{h}_{t} \) are the input, forget, memory, output and hidden state of the LSTM. Input \( i_{t} \), output \( o_{t} \) and forget \( f_{t} \) controls other states, can be derived from the context vector z and hidden state of last hidden state.
Input gate \( \varvec{i}_{t} \), forget gate \( \varvec{f}_{t} \), output gate \( \varvec{o}_{t} \) are activated by sigmoid function. Input modulation gate \( \varvec{g}_{t} \) is activated by tanh function. T denote an affine transformation with learned parameters. D, m and n are the dimension of feature vector, embedding and LSTM units respectively. \( {\mathbf{E}} \) is an embedding matrix. y is the caption generated.
Memory \( \varvec{c}_{t} \) is the core of the LSTM, derived from memory of last word generated and \( \varvec{g}_{t} \), the forget state \( \varvec{f}_{t} \) controls memory of previous word. \( \odot \) is element-wise multiplication.
And hidden state \( \varvec{h}_{t} \) was calculated from memory and controlled by output \( \varvec{o}_{t} \). Then use fully connected layer to generate current word \( y_{t} \).
5 Experiment
5.1 Data Collection
To train our model, we collect data from several sources: open dataset (Microsoft COCO), images collected from internet, and photos captured by us.
Microsoft COCO [23] is a large-scale object detection, segmentation, and captioning dataset. The Microsoft COCO 2014 captions dataset contains 82,783 training, 40,504 validation, and 40,775 testing images. It has variety of objects and scenes, from indoor to outdoor and annotated with sentence describe the scene. Each image has several corresponding annotations.
Although Microsoft COCO dataset works for majority of general Image captioning task, it still lake of some data that specialized for our scenario. To address this issue, we collected data that contains infant, cribs, soft objects, and bedding. Then manually annotate them. For example, in the scenario (a) “baby sleep on tummy” under Sect. 5.3 Experiment Result, note that each image doesn’t have to include all the required information; just a subset of the needed information for each individual image is enough, in the event that the dataset overall covers every aspect. For example, we collected images where the baby is sleeping on his back, other images contained only crib with bedding, and some images contained different kind of bedding objects such as pillow, comforter and blanket.
In addition to Microsoft COCO dataset, we collected and annotated 1,843 images related to the baby’s sleeping position. The corresponding annotation for those images indicated that 1,463 out of the 1,843 images included bedding objects. And 357 images contain comprehensive visual content which usually have multiple elements in single image.
5.2 Training
As aforementioned, we used pre-trained VGG net model to create annotation vector, and besides that, we also used SVM specialized in classify bedding from the texture feature extracted from image. Then we used the ratio in Microsoft COCO dataset to separate our own dataset into training, validation and test set. It took around 3 days to train the model on Nvidia Quodro K6000 GPU.
SVM is trained using subset of the dataset that contains only bedding materials. We’ve compared accuracy rate with applying texture classification with 5 layer CNN using raw input images. Experiment shows our GLCM feature based method achieved accuracy rate 95.48%, outperforms 5 layer CNN’s result (68.72%) on our dataset.
5.3 Experiment Result
We blurred out infants’ faces in input image out of privacy concern. It shows three typical scenarios. Attention map generated by attention model highlighted important regions where the algorithm focused on (Fig. 2).

Input image (first column), attention map (second column), caption generated
Captions generated from the image indicated the required information regarding to infant sleep position, soft object and bedding condition, and as post processing, it gives the instruction or advice to fix the detected issue. In Fig. 2(a), the generated caption “baby sleep on tummy on soft bedding” suggests the following two issues: 1. Wrong sleeping position; and 2. Inappropriate bedding material. After the machine translation step, the post processing generates specific instructions related to the detected issues, such as advising to “please let baby sleep on back”; or “please change to fitted sheet”, etc. Similarly, the blanket in Fig. 2(b) was detected, which is also one of the common risk factors. In Fig. 2(c) when there is no infant in the picture, our method still can generate caption stated the issue of soft bedding by texture analysis. It is helpful to provide a safe infant sleeping environment.
To evaluate the result and to analyze how well it describes the issue in the given image, we calculated the precision rate and recall rate [27] of the result. When interpreting the result, a true positive means it successfully addressed the corresponding issue; and a false positive means it detected the issue that does not occur in the image; while a true negative means that there is no issue in the image, and the caption shows the same way; and finally, a false negative means that it missed an issue that occurred in the image (Table 2).
The precision rate = True positive/(True positive + False positive) = 81.3%
The recall rate = True positive/(True positive + False negative) = 88.4%
6 Conclusion
We proposed a new framework of image captioning to help diagnosis the infant sleeping environment which is essential to reduce risk of SIDS. In addition to a general description, a detailed relevant information was generated in order to give a constructive advice accordingly. Most of the test set generated correct caption which addresses the potential danger factor that occurs in the image. The proposed method would achieve better performance with higher-quality extensive data. Although this method was applied on infant sleeping environment, it would also find real-world applications, such as in the case of real-world assistive systems and any other case where natural language is generated as the output and facilitates the interaction, making the human–computer interaction more convenient.
References
https://www1.nichd.nih.gov/sts/about/SIDS/Pages/default.aspx. Accessed 01 June 2018
https://www.cdc.gov/sids/data.htm. Accessed 01 June 2018
Kiros, R, Salakhutdinov, R., Zemel, R.S.: Unifying visual-semantic embeddings with multimodal neural language models. arXiv preprint arXiv:1411.2539 (2014)
Mao, J., Xu, W., Yang, Y., et al.: Deep captioning with multimodal recurrent neural networks (m-RNN). arXiv preprint arXiv:1412.6632 (2014)
Wu, Q., Shen, C., Liu, L., et al.: What value do explicit high level concepts have in vision to language problems? In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 203–212 (2016)
Liu, X., Milanova, M.: Visual attention in deep learning: a review. Int. Rob. Auto. J. 4(3), 154–155 (2018)
http://pediatrics.aappublications.org/content/early/2016/10/20/peds.2016-2938
https://store.nanit.com/. Accessed 01 June 2018
https://owletcare.com/. Accessed 01 June 2018
Fang, H., Gupta, S., Iandola, F., et al.: From captions to visual concepts and back. In: Proceedings of the IEEE Conference on Computer Vision And Pattern Recognition, pp. 1473–1482 (2015)
Karpathy, A., Fei-Fei, L.: Deep visual-semantic alignments for generating image descriptions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2015)
Socher, R., Karpathy, A., Le, Q.V., et al.: Grounded compositional semantics for finding and describing images with sentences. Trans. Assoc. Comput. Linguist. 2(1), 207–218 (2014)
Vinyals, O., Toshev, A., Bengio, S., et al.: Show and tell: a neural image caption generator. In: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3156–3164. IEEE (2015)
Xu, K., Ba, J., Kiros, R., et al.: Show, attend and tell: Neural image caption generation with visual attention. In: International Conference on Machine Learning, pp. 2048–2057 (2015)
Cheng, M.M., Mitra, N.J., Huang, X., et al.: Global contrast based salient region detection. IEEE Trans. Patt. Anal. Mach. Intell. 37(3), 569–582 (2015)
Mnih, V., Heess, N., Graves, A.: Recurrent models of visual attention. In: Advances in Neural Information Processing Systems, pp. 2204–2212 (2014)
Ba, J., Mnih, V., Kavukcuoglu, K.: Multiple object recognition with visual attention. arXiv preprint arXiv:1412.7755 (2014)
Gers, F.A., Schmidhuber, J., Cummins, F.: Learning to forget: continual prediction with LSTM. Neural Comput. 12, 2451–2471 (2000)
Haralick, R.M., Shanmugam, K.: Textural features for image classification. IEEE Trans. Syst. Man Cybern. 6, 610–621 (1973)
Huang, X., Liu, X., Zhang, L.: A multichannel gray level co-occurrence matrix for multi/hyperspectral image texture representation. Remote Sens. 6(9), 8424–8445 (2014)
Soh, L.K., Tsatsoulis, C.: Texture analysis of SAR sea ice imagery using gray level co-occurrence matrices. IEEE Trans. Geosci. Remote Sens. 37(2), 780–795 (1999)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
Chen, X., Fang, H., Lin, T.Y., et al.: Microsoft COCO captions: data collection and evaluation server. arXiv preprint arXiv:1504.00325 (2015)
Kulkarni, G., Premraj, V., Ordonez, V., et al.: Babytalk: understanding and generating simple image descriptions. IEEE Trans. Patt. Anal. Mach. Intell. 35(12), 2891–2903 (2013)
Mitchell, M., Han, X., Dodge, J., et al.: Midge: generating image descriptions from computer vision detections. In: Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics, pp. 747–756. Association for Computational Linguistics (2012)
Yang, Y., Teo, C.L., Daumé III, H., et al.: Corpus-guided sentence generation of natural images. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing, pp. 444–454. Association for Computational Linguistics (2011)
Davis, J., Goadrich, M.: The relationship between Precision-Recall and ROC curves. In: Proceedings of the 23rd International Conference on Machine Learning, pp. 233–240. ACM (2006)
Hearst, M.A., Dumais, S.T., Osuna, E., et al.: Support vector machines. IEEE Intell. Syst. Appl. 13(4), 18–28 (1998)
Acknowledgements
We greatly appreciate the collaboration with Dr. Rosemary Nabaweesi from University of Arkansas for Medical Sciences for helping us collect data and providing theoretical guidance on SIDS.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Liu, X., Milanova, M. (2019). An Image Captioning Method for Infant Sleeping Environment Diagnosis. In: Schwenker, F., Scherer, S. (eds) Multimodal Pattern Recognition of Social Signals in Human-Computer-Interaction. MPRSS 2018. Lecture Notes in Computer Science(), vol 11377. Springer, Cham. https://doi.org/10.1007/978-3-030-20984-1_2
Download citation
DOI: https://doi.org/10.1007/978-3-030-20984-1_2
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-20983-4
Online ISBN: 978-3-030-20984-1
eBook Packages: Computer ScienceComputer Science (R0)
