
Abstract
Health consumers engage in social interactions in online health communities (OHCs) to seek or provide social support. Automatic classification of social support exchanged online is important for both researchers and practitioners of online health communities, especially when a large number of messages are posted on regular basis. Classification of social support in OHCs provides an efficient way to assess the effectiveness of social interactions in the virtual environment. Most previous studies of online social support classification are based on “bag-of-words” assumption and have not considered the semantic meaning of words/terms embedded in the online messages. This research proposes a classification framework for online social support using the recent development of word space models and deep learning methods. Specifically, doc2vec models, bag-of-words representations, and linguistic analysis methods are used to extract features from the text messages that are posted in OHC for online social interaction or social support exchange. Then a deep learning model is applied to classify two major types of social support (i.e., informational and emotional support) expressed in OHC reply messages.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Health consumers are increasingly participating in online health communities (OHCs) to seek social support from others to better deal with their health conditions [1, 2]. With the advancement and wide adoption of the Internet, social support exchange, which traditionally occurs in a physical setting with face-to-face interactions between the giver and the recipient, has been gradually moved to the online setting such as an online health community. An important task for OHC research and practice is to automatically categorize social support embedded in online messages, especially when a large amount of social support is exchanged in the virtual environment. The automatic classification of social support helps practitioners and researchers to better understand social interactions in OHCs and thus provides insights regarding how the OHCs can be managed to better serve the needs of community participants. For example, assessing social support contribution of participants can provide a way for the OHC to detect leaders in the community so that social support seekers can be more efficiently directed to these leaders. In general, evaluation of social interactions in online communities sets a basis for more advanced motivational mechanisms (or affordances) such as voting and commenting that can incentivize ongoing engagement and contribution of participants [3]. As OHC participants tend to use particular writing styles and elements in expressing social support in their online messages [4], social support classification based on linguistic features extracted from online messages has been shown to be efficient. However, previous studies on online social support classification (e.g., [2, 4, 5]) are based on the approach of bag-of-words (BOW), which represents a document as a vector of terms ignoring their positions and semantic connections between them.
This study applies deep learning methods to the classification of social support exchanged in online health communities. Particularly, this study applies the doc2vec model to represent each OHC message. The doc2vec model [6] is an extension of the word2vec model [7]. Two variants of doc2vec are distributed memory model of paragraph vectors (DM) and distributed bag of words (DBOW). The word space models trained by word2vec and doc2vec have been shown to be able to capture semantic meanings and perform well in a variety of natural language processing tasks such as sentiment analysis [8], Wikipedia article quality assessment [9], and news classification [10]. However, there is no extant study that applies and evaluates the recent development of word space models as well as deep learning methods for online social support classification. The current research aims to fill the knowledge gap by addressing the following research question:
Research Question: How can we use deep learning and word space models to classify social support exchanged in online health communities?
The organization of this paper is as follows. First, research background is introduced in the next section. Then, the framework of online social support classification is proposed, followed by an experiment to evaluate the proposed method. Lastly, preliminary results and conclusions are discussed.
2 Background
2.1 Online Social Support Exchange
Social support refers to the degree to which a person’s fundamental social needs such as affection, approval, belonging, identity, and security are met through interactions with others [11, 12]. Online social support is usually exchanged in online health communities (OHCs) where health care consumers can ask questions, share experience/information, or seek/provide support. A typical scenario of social support exchange in OHCs is initiated by a participant posting a message on a specific health condition or topic, followed by other participants’ replies to this discussion. Online social support exchange plays an essential role for the self-management of health conditions and the change of health behaviors, as it has been found to benefit participants by improving their health knowledge and attitudes [2].
The two types of social support most frequently exchanged in OHCs are: (1) informational support that refers to the offering of detailed information, facts, suggestions, or news about the health situation or ways of better dealing with the situation; and (2) emotional support that expresses emotional concerns such as care, love, sympathy, understanding, and encouragement. This study focuses on the classification of these two major types of social support exchanged in online health communities, using deep learning and word-embedding methods as reviewed in the following subsections.
2.2 Deep Learning
Machine learning methods have been applied in various applications such as image recognition, default detection, customer churn prevention, and sentiment classification. Deep learning is a representation learning method that employs multiple processing layers of neural networks to learn a hierarchy of abstract representations of data for regression or classification [13]. A deep learning neural network architecture contains a stack of multiple layers, each layer mapping the input to output. Those multiple layers (usually non-linear) can learn complicated yet minute features from the raw data. Compared with classical machine learning methods in which features need to be refined/extracted by human experts, deep learning methods learn the multi-layer abstract representations of raw data for subsequent regression or classification. Thus, deep learning has a great potential for empowering many business applications such as Fintech [14], manufacturing [15], and enterprise social media management [16].
2.3 Word Embedding
Application of machine learning algorithms to textual data analysis such as social support classification and sentiment analysis requires a way of representing the unstructured textual data as numerical numbers. Previous studies on online social support classification (e.g., [2, 4, 5]) used the bag of words (BOW) approach to quantify textual messages exchanged in OHCs. That is, OHC messages are represented as a form of term-by-document matrix. The BOW representation assumes that a document is a collection of words/terms, thus important information regarding the positions of words and semantic connections between words is not captured. Also, BOW method usually leads to feature vectors with very high dimensionality, which often need a manual or algorithm-driven feature selection procedure to reduce the dimensionality of data for machine learning algorithm training. A general BOW method involves multiple steps including tokenizing textual data, stemming, filtering out stop-words, creating term-by-document matrices, and selecting features.
Word embedding refers to a set of techniques that represent words or phrases of a vocabulary in a continuous low-dimensional vector space. Word embedding methods minimize the distance between a word and its context words in the vector space such that similar words are close to each other in the space model. Compared to methods based on bag of words, word embedding approaches can build a word vector space that captures the syntactic and semantic characteristics of words, thus improving the performance of various regression or classification tasks. Recently word2vec model [7] has become attractive as a word embedding method that is learned from artificial neural networks.
A primary benefit of word2vec model is that it can be trained by a large amount of unlabeled data (i.e., unsupervised learning) using a neural network structure with two layers. Two techniques of word2vec, as depicted in Fig. 1, include: (1) continuous bag of words (CBOW) which predicts a word from its context words, and (2) skip-gram which, on the opposite direction, predicts context words from the current word.

(adapted from [7])
Word2vec models
As word2vec models only provide vector representation for individual words, the results cannot be directly used for social support classification or other text classification that is at the document (or message) level. A typical way of representing documents is to aggregate all the vectors of words occurring in a document as the embedding representation of the document [e.g., 17]. However, such aggregation does not guarantee an appropriate representation of similar documents.
The doc2vec model [6] extends the word2vec approach to unsupervised leaning of continuous representations of documents, paragraphs, or sentences. Two variations of doc2vec are: (1) distributed memory (DM) model of paragraph vectors which is similar to the CBOW model in word2vec, and (2) distributed bag of words (DBOW) which is analogous to the skip-gram model in word2vec. As shown in Fig. 2, the DM model uses both the document/paragraph vector and word vectors to predict the center word in the context, while the DBOW model trains the document/paragraph vector to predict words in a small window. This study applies both the DM and DBOW models to represent OHC messages.

(adapted from [6])
Doc2vec models
3 A Framework for Social Support Classification
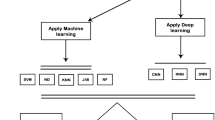
Figure 3 presents a framework for the classification of social support exchanged in online health communities.

Framework of online social support classification.
First, textual messages are collected from OHCs. These messages are then cleaned and various features including document embedding features using doc2vec, bag-of-words features, and linguistic features are trained or extracted from the textual data. All these features are treated as the input of a deep learning model which classifies whether an OHC message expresses informational support or emotional support. At the evaluation stage, various performance measures such as accuracy, AUC (area under curve), precision, recall, and F1 score can be used to evaluate the performance of the trained algorithm.
4 Research Method
An experiment was conducted to evaluate the proposed framework of social support classification. The details are explained in the following subsections.
4.1 Dataset
A dataset of 1830 forum reply messages was collected from a US-hosted online health community dedicated to the topics of depression. Each message was manually coded as whether it expresses informational support or emotional support. The manual labels were treated as the ground truth for validation. This is an imbalanced dataset with 249 messages expressing informational support and 417 messages expressing emotional support among all 1830 replies. The whole dataset was split into a training set of 1281 observations (70%) and a test set of 549 observations (30%).
4.2 Textual Data Processing
The raw OHC messages were preprocessed to extract important features for classification modeling. In total, 1055 features were trained or extracted from the textual data. These features include the following four major types that capture significant textual characteristics of social support expression in these messages. The total number of features of each type is shown in parentheses.
-
Doc2vec DM features (300)
-
Doc2vec DBOW features (300)
-
Bag-of-words TF-IDF features (362)
-
Linguistic features (93)
The doc2vec features (both DM and DBOW) were trained by using the Python implementation of doc2vec in the Gensim package [18]. Word embeddings were trained on the same research dataset.
To extract bag-of-words features, reply messages collected from the online health communities were first tokenized and changed to lower case. Non-letter terms were filtered out in the data analysis. Stop words such as “the”, “is”, “of”, “an”, and “a” were removed from the documents. Then, the Porter stemming method [19] was applied to remove term suffices. Finally, a TF-IDF (term frequency-inverse document frequency) matrix was created to represent the relative importance of frequent terms in OHC reply messages. Figure 4 shows the word clouds of the 150 most frequent stemmed terms occurring in informational support messages and emotional support messages respectively.

Word clouds of social support messages in online health communities.
The linguistic features were calculated by the software tool LIWC [20]. LIWC is a widely used linguistic analysis tool, with its reliability and validity verified by many studies [20,21,22].
4.3 Feature Importance
The importance of the four sets of features was assessed by applying a random forests algorithm on informational support classification. Figure 5 shows the importance scores of all features. Table 1 summarizes the top 200 most important features from all the 1055 features. A substantial portion of the top 200 most important features are trained from doc2vec models, with 52% of features trained from the distributed memory (DM) model and 42% trained from the distributed bag of words (DBOW) model. In contrast, only 6% of the top 200 most important features come from the traditional bag of words approach and the LIWC linguistic analysis. This provides clear evidence that the word2vec models can better capture important features for online social support classification than the traditional bag of words and linguistic analysis methods.

Feature importance.
4.4 Predictive Modeling
A deep learning neural network was used to classify whether an OHC reply message expresses informational and emotional social support. As an OHC reply may provide both informational and emotional support, two classifiers were trained and evaluated, each classifying one type of social support. As the dataset is imbalanced, classification algorithms tend to introduce bias by predicting the more frequent classes. To deal with the imbalanced dataset, class weights were set to be inversely proportional to their frequency in the training set.
5 Preliminary Result
Figure 6 shows the accuracy and loss of each social support classifier over time. Overall, the informational support classifier reaches an accuracy of 87.4%, while the emotional support classifier has an accuracy of 83.8%.

Performance of social support classifiers over time.
For the future work, a couple of other classification methods including logistic regression, support vector machine, decision tree, and random forests will be used to compare with the suggested deep learning neural network. Grid search strategy will also be used to tune hyper-parameters in the learning algorithms, in order to further improve the classification performance of the algorithms. Further, other performance metrics such as AUC, precision, recall, and F1 score can be applied to more comprehensively evaluate the performance of deep learning classification method. In addition, using pre-trained word embeddings may also improve the performance of text classification [23]. Lastly, more labelled data can be collected as deep learning needs a lot of training samples.
6 Conclusion
Online health communities have attracted significant attention from both academic communities and practice [1, 2, 24, 25]. This study proposes a framework that incorporates doc2vec representation models and deep learning methods into the classification of social support exchanged in online health communities. The findings will provide important implications for both research and practice of online health communities. The same approach can also be applied in or extended to a variety of other settings such as online knowledge communities where an important effort is to assess the quality of knowledge contribution expressed in participants’ posts [3].
References
Chen, L., Straub, D.: The impact of virtually crowdsourced social support on individual health: analyzing big datasets for underlying causalities. In: Proceedings of the 21st Americas Conference on Information Systems, pp. 1–8 (2015)
Chen, L., Baird, A., Straub, D.: Fostering participant health knowledge and attitudes: An econometric study of a chronic disease-focused online health community. J. Manag. Inf. Syst. 36(1), 194–229 (2019)
Chen, L., Baird, A., Straub, D.: Why do participants continue to contribute? Evaluation of usefulness voting and commenting motivational affordances within an online knowledge community. Decis. Support Syst. 118, 21–32 (2019)
Wang, Y.-C., Kraut, R., Levine, J.M.: To stay or leave?: the relationship of emotional and informational support to commitment in online health support groups. In: Proceedings of the ACM 2012 Conference on Computer Supported Cooperative Work, pp. 833–842. ACM, 2145329 (2012)
Wang, X., Zhao, K., Street, N.: Social support and user engagement in online health communities. In: Zheng, X., Zeng, D., Chen, H., Zhang, Y., Xing, C., Neill, D.B. (eds.) ICSH 2014. LNCS, vol. 8549, pp. 97–110. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-08416-9_10
Le, Q., Mikolov, T.: Distributed representations of sentences and documents. In: International Conference on Machine Learning, pp. 1188–1196 (2014)
Mikolov, T., Chen, K., Corrado, G., Dean, J.: Efficient estimation of word representations in vector space. In: Proceedings of Workshop at the International Conference on Learning Representations (2013)
Liang, H., Fothergill, R., Baldwin, T.: Rosemerry: a baseline message-level sentiment classification system. In: Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), pp. 551–555 (2015)
Dang, Q.V., Ignat, C.-L.: Quality assessment of Wikipedia articles without feature engineering. In: Proceedings of the 16th ACM/IEEE-CS on Joint Conference on Digital Libraries, pp. 27–30. ACM (2016)
Trieu, L.Q., Tran, H.Q., Tran, M.-T.: News classification from social media using twitter-based doc2vec model and automatic query expansion. In: Proceedings of the Eighth International Symposium on Information and Communication Technology, pp. 460–467. ACM (2017)
Thoits, P.A.: Conceptual, methodological, and theoretical problems in studying social support as a buffer against life stress. J. Health Soc. Behav. 23, 145–159 (1982)
Kaplan, B.H., Cassel, J.C., Gore, S.: Social support and health. Med. Care 15, 47–58 (1977)
LeCun, Y., Bengio, Y., Hinton, G.: Deep learning. Nature 521, 436–444 (2015)
Siau, K., et al.: Fintech empowerment: Data science, AI, and machine learning. Cutter Bus. Technol. J. 31, 12–18 (2018)
Wang, J., Ma, Y., Zhang, L., Gao, R.X., Wu, D.: Deep learning for smart manufacturing: Methods and applications. J. Manuf. Syst. 48, 144–156 (2018)
Moqbel, M., Nah, F.F.-H.: Enterprise social media use and impact on performance: the role of workplace integration and positive emotions. AIS Trans. Hum.-Comput. Interact. 9, 261–280 (2017)
Enríquez, F., Troyano, J.A., López-Solaz, T.: An approach to the use of word embeddings in an opinion classification task. Expert Syst. Appl. 66, 1–6 (2016)
Rehurek, R., Sojka, P.: Software framework for topic modelling with large corpora. In: Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks. Citeseer (2010)
Porter, M.F.: An algorithm for suffix stripping. Program 14, 130–137 (1980)
Pennebaker, J.W., Boyd, R.L., Jordan, K., Blackburn, K.: The development and psychometric properties of LIWC2015. University of Texas at Austin, Austin, TX (2015)
Tausczik, Y.R., Pennebaker, J.W.: The psychological meaning of words: LIWC and computerized text analysis methods. J. Lang. Soc. Psychol. 29, 24–54 (2010)
Pennebaker, J.W., Francis, M.E.: Cognitive, emotional, and language processes in disclosure. Cogn. Emot. 10, 601–626 (1996)
Lau, J.H., Baldwin, T.: An empirical evaluation of doc2vec with practical insights into document embedding generation. arXiv preprint arXiv:1607.05368 (2016)
Chen, L., Baird, A., Straub, D.: An analysis of the evolving intellectual structure of health information systems research within the information systems (IS) discipline. J. Assoc. Inf. Syst. 1–48 (2019, forthcoming)
Chen, L., Baird, A., Straub, D.: The evolving intellectual structure of the health informatics discipline: a multi-method investigation of a rapidly-growing scientific field. Working Paper, Georgia State University (2014)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Chen, L. (2019). A Classification Framework for Online Social Support Using Deep Learning. In: Nah, FH., Siau, K. (eds) HCI in Business, Government and Organizations. Information Systems and Analytics. HCII 2019. Lecture Notes in Computer Science(), vol 11589. Springer, Cham. https://doi.org/10.1007/978-3-030-22338-0_14
Download citation
DOI: https://doi.org/10.1007/978-3-030-22338-0_14
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-22337-3
Online ISBN: 978-3-030-22338-0
eBook Packages: Computer ScienceComputer Science (R0)