
Abstract
As edge computing and hybrid clouds gain momentum, migrating virtual machines between datacenters is becoming increasingly important. Whether such migration is performed live or not, it starts with a full copy of a virtual disk over the network. This initial copy is consuming the bulk of the transfer time and network use. Improving this copy is the focus of our paper. While compression can somewhat help with this, we propose a novel technique, which we call teleportation. Teleportation assembles disk images directly at the destination from the pieces of other, unrelated disk images already present there. Since the data found at the destination doesn’t have to be sent over, our prototype has achieved 3.4x increase in network throughput (comparing to compression).
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
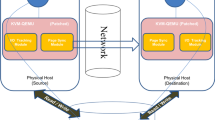
Teleportation takes advantage of the fact that file systems align files inside a disk image on 4 KB block boundaries. We calculate a hash of each block in each disk image. If the same file (such as ntdll.dll) is present in two separate disk images, the hash of each block of that file would be present in the set of hashes of either disk image. Teleportation process is shown in Fig. 1.

Teleportation process.
Teleportation starts with the source endpoint calculating 256-bit cryptographic hashes of each block [❶] and sending them to the teleporter [❷]. The teleporter tries to find the block with the same hash among the blocks which belong to other disk images already present at the destination by doing a hash table lookup [❸]. If a matching block is found [❹], it doesn’t need to be sent over the network, otherwise it is requested from the source [❺, ❻].
The biggest challenge in teleporter implementation is memory efficiency. The hashes we use are 32 bytes long. If we hash just one terabyte of disk image data and put all the hashes in memory, they would occupy 8 GB of memory. Instead of keeping hashes in memory, our implementation stores hashes in disk files, which we call hash files. Keeping hashes on disk allows us to use 9x less memory per cache entry. Hashes in the hash file follow the same logical order as blocks in the disk image, thus preserving locality of reference.
The most important insight we had when designing teleporter was that most files inside the disk image are not fragmented. Because of this, once the 1st block of a file (which we call head) got matched, in all likelihood, the sequence of blocks that follows would match too. This has two important implications. The first one is that it is sufficient to keep in memory information about the head of each file - the rest of the blocks of that file can be found by reading subsequent hashes from the hash file. By using this technique, teleporter started using 10x less memory. The second implication is that 2nd and subsequent blocks of the file can be matched with no extra disk I/O. This works because a unit of disk I/O is 4 KB, so every time teleporter performs a read from a hash file, 128 hashes are fetched into memory. As the result, teleporter performs very little disk I/O when the blocks do match. Teleporter detects file heads by analyzing content of each block.
When the blocks don’t match, teleporter uses hash fingerprints to probabilistically reduce disk I/O. Fingerprint is a small 8-bit hash derived from the 256-bit hash of a block. Fingerprints are stored in memory inside the cache items instead of full hashes. When fingerprints don’t match, there is no need to fetch hashes from the disk to compare, so most of unsuccessful disk I/O is eliminated.
As a result of the aforementioned design choices, we ended up with a hash matching system that performs matching with very few disk reads, while having a very small memory footprint. This matching system is a cornerstone of our design.
This paper makes the following contributions:
-
Use of strong/weak head recognition (Sect. 2.3) for sequence discovery.
-
Use of hash files to preserve referential locality for hashes stored on disk and reduce memory footprint (Sect. 2.5).
-
Use of block sequences to reduce both the amount of disk I/O (Sect. 2.6) and memory footprint (Sect. 2.10).
-
Novel space-efficient cache (Sect. 2.9) that combines cuckoo hashing with LRU-approximating cache replacement policy.
-
Probabilistic cache admission policy (Sect. 2.10) that affects cache item’s lifetime.
-
Use of indirect addressing (Sect. 2.11) to reduce size of each cache entry by 7 bits.
-
Alignment of sequences in the sequence cache on the 128-block boundaries to reduce disk I/O (Sect. 2.15).
-
Novel cache coherence protocol (Sect. 2.16) that does not require notifying teleporter when destination blocks get modified.
-
Use of grain table compression (Sect. 2.17) to reduce the memory footprint of the destination endpoint.
2 Design
Source endpoint is covered in Sects. 2.1–2.4, teleporter is covered in Sects. 2.5–2.15, and destination endpoint is covered in Sects. 2.16 and 2.17.
2.1 Parallelism
For both regular network copy and teleportation, it is important to perform major activities in parallel. For regular copy, these activities are reading, sending, and writing. For teleportation, there are two additional activities - hashing (done on the source endpoint) and matching (performed on the teleporter). We process blocks in batches and use the pipelining paradigm for parallelism (Fig. 2). There are dedicated threads for each activity, and each batch of blocks is processed in order by each thread.

Serial processing (left) vs pipelining (right).
2.2 Sparse Disks and Zero-Fill
Teleportation handles both flat and sparse disks [1]. In the case of sparse disk, source endpoint sends the sparse disk header and the grain table (a table of pointers to grains - units of allocated disk space) directly to the destination endpoint. Following that, source endpoint reads the disk in the logical grain order (effectively flattening it), and sends the hashes of the data to the teleporter. Destination endpoint receives the data in the flattened order, and uses the grain table to reconstruct the sparse disk. The teleporter is not aware whether the disk is sparse or flat. Hashes of zero-filled blocks are not sent to the teleporter. Information regarding zero-filled or unallocated blocks is sent as an array of bits. Such array is not only small to begin with, it compresses really well.
2.3 Head Recognition
The obvious way to identify file heads is to deploy a VM from the disk image, and install an agent (software to scan the file system) on that VM. We use a novel agent-less approach to identify file heads with high probability. One way to identify a file head is to examine first few bytes of the block. Files frequently incorporate file type metadata by storing a “magic number” at the very start of the file (for example, all the Windows executable files start with “MZ”, all PDF files start with “PDF%”, etc.). If we can find the first few bytes of a block in the known database of magic numbers (this can be a simple hash table lookup), we consider such block to be a strong file head. Another way to identify a file head is based on the observation that the size of most files is not an exact multiple of block size (4 KB). Because of this, most files end with one or more zeroes. We consider the block that has data, but ends with one or more zeroes to be a file tail, so the block right after that is a weak file head. Weak file heads exhibit higher rate of false positives. Information regarding strong and weak heads is sent to the teleporter as an array of bits.
2.4 Compression
The blocks which failed to teleport are compressed before being sent to destination and uncompressed upon arrival. This process further improves network throughput.
2.5 Hash Files
Hash file is a sequence of hashes of disk image blocks written to a disk file (Fig. 3). Hashes in the hash file follow the same order as blocks in the disk image, thus preserving locality of reference. Hash files allow teleporter to save memory by only storing in memory the address of the hash on disk instead of the hash itself. A hash file is 128 times smaller than its disk image.

Hash file.
2.6 Block Sequences
Block sequence is a sequence of blocks that matches between two or more disk images. It often (but not always) corresponds with a file inside a disk image.
Block sequence detection process is shown in Fig. 4. First, source endpoint sends a chain of hashes to the teleporter. Each incoming hash is looked up in the cache until a match is found in a hash file for one of the previously teleported files [❶, ❷]. At this point we can traverse forward both the chain of hashes received from the source and the hashes read sequentially from the hash file [❸]. We continue the traversal until a mismatch is found, thus identifying a sequence of blocks which qualifies for teleportation.

Extending a match into a block sequence.
Once a match is found, block sequence can be identified very efficiently. Chain of hashes received from the source is fully in memory. Since a unit of disk I/O is 4 KB, every time teleporter reads from a hash file, 128 hashes are fetched into memory. As a result, block sequence identification works at amortized speed of 128 blocks per single 4 KB disk I/O.
2.7 Cuckoo Hashing
We didn’t want to use hash table collision resolution algorithm known as separate chaining, because it requires a pointer in each hash table entry, and we didn’t want to waste memory on pointers. Instead, we have used an open addressing method of collision resolution known as cuckoo hashing [2]. Cuckoo hashing is shown in Fig. 5. In cuckoo hashing an item can go into one of two locations (determined by two separate hash functions). If both locations are full, item in one of them is kicked into its alternate location. This process is repeated until all the items are placed.

Cuckoo hashing.
2.8 Cuckoo Hashing with Buckets
Cuckoo hashing works well until a load factor of roughly 49% is reached [3], after which insertions are starting to fail (when a maximum number of displacements was reached, but a vacant slot still wasn’t found). In order to improve the load factor, we turn each location into a bucket (see Fig. 6) that can hold up to 4 entries. This enhancement supports load factors as high as 93%.

Cuckoo hashing with buckets.
2.9 Cuckoo LRU
To turn cuckoo hash table into a cache, we use LRU within each bucket (see Fig. 7). Since a bucket fits into a CPU cache line, we can implement such LRU very efficiently by shifting memory within the bucket. Items are inserted into the top entry of the bucket. When an item is inserted, the rest of the items in the bucket are shifted down. On cache hit, we move the item to the top of the bucket and shift the rest of the items down.

Cuckoo LRU.
2.10 Cache Hierarchy
Teleporter uses a hierarchy of three caches (Fig. 8). Only references to the blocks which were identified by the head recognition as a file head (either strong or weak) are added to any of the caches. Strong heads are added to the C1 cache, and weak heads are added to the C0 cache. When a match occurs in either C0 or C1, the cache item is promoted to a long-term C2 cache. When a match occurs in C2, the item is moved to the top of its bucket. When an item is evicted from C1, it is moved to C0 to prolong its lifetime. Cache sizing is discussed in Sect. 3.8.

Cache hierarchy.
2.11 Hash File and Disk Image Addressing
Hash files not only allow us to not store block hashes in memory, they aid in compact representation of a block address in memory. Because a unit of disk I/O is 4 KB, every time teleporter performs a read from a hash file, 128 hashes are fetched into memory. As a consequence of this, in order to lookup a block by its hash, it is sufficient to know the group of 128 hashes which contains the hash - we can scan through these hashes to find the one we need. This gives us the block offset formula: (b * 128 + h) * 4096, where b is the zero-based index of hash block, and h is the zero-based hash index within the block. Addressing example is shown in Fig. 9. In this example, in-memory address is “2”, so we skip 256 hashes in the hash file and scan the next block of 128 hashes. Since the hash with index “1” in the block has matched, we can read the 257th block of the disk image to get the data.

Hash file addressing.
This approach allows a single bit to address as much as one megabyte of disk space (21 * 128 * 4096). C0 and C1 cache entries use 19 bits to address up to 256 GB of space. C2 cache entries use 24 bits to address up to 8 TB of space.
2.12 Probabilistic Fingerprints
As described in Sect. 2.6, once we find a match, we can process a sequence of blocks very efficiently. However, until we find a match, we would have to perform a disk read for each cache lookup. Teleporter avoids most of such disk I/O by using probabilistic fingerprints. Fingerprint is a small 8-bit hash derived from the 256-bit hash of a block. Fingerprints are stored inside cache items (see Sect. 2.13). When doing lookup, teleporter compares fingerprints first, and if they don’t match there is no need to do disk I/O. Since an item can be placed in 8 possible cache locations (two buckets with 4 entries per bucket, Sects. 2.7 and 2.8), probability of a fingerprint collision is 3% (8/28).
Fingerprints are useful not just for reduction in disk I/O. They also help to implement cuckoo hashing. Cuckoo hashing relies on storing full keys in order to calculate an item’s alternate location. Since we store fingerprints instead of full hashes, we utilize the partial-key cuckoo hashing technique [4] to figure out an item’s alternate bucket index i2 from the current bucket index i1 and the fingerprint stored in this bucket:
The xor operation (⊕) allows to calculate bucket index i1 from i2 using the same formula. This allows to relocate an item between buckets without fetching full hash from the hash file. Fingerprint is hashed to help distribute the items more uniformly in the cache. If the fingerprint wasn’t hashed, the items kicked out from nearby buckets would land close to each other in the cache. Since we use 8-bit fingerprints, the items kicked out from the bucket would be placed into buckets that are at most 256 buckets away, because the xor operation would alter the eight low order bits of the bucket index while the higher order bits would not change. Since there are only 256 fingerprints, their hashes can be precomputed and stored in an array to improve performance.
2.13 Cache Entry Structure
C0/C1 cache entry structure (4 bytes) is shown in Fig. 10. 1st byte is a fingerprint. Next 5 bits specify one of the 32 most recently teleported files. Last 19 bits is the address inside the file. C2 cache entry structure (Fig. 11) is lacking File ID, because it points into a sequence cache instead (Sect. 2.14). Because C2 cache entry structure is incompatible with C0/C1, we can’t evict items from C2 back to C0/C1.

C0/C1 cache entry.

C2 cache entry.
Cache entries can be sized differently to address specific requirements. Fingerprint size, file ID size, and address size can all be increased or decreased. The only limitation is that cuckoo bucket size (16 bytes in our design) must not exceed the cache line (typically 64 bytes). We chose our design to demonstrate that 4-byte entries are quite practical.
2.14 Sequence Cache
Sequence cache is an on-disk collection of all the block sequences ever matched for a given destination. Sequence cache consists of a hash file and a data file, and is backing C2 cache. The hash file is located on the teleporter, while the data file is located on the destination. In fact, data blocks are never sent to the teleporter, only directly from the source to the destination. Maximum size of the data file of the sequence cache (8 TB in our setup) is only limited by the amount of disk space addressable by the C2 cache entry (Sect. 2.11). However, most of the blocks in the data file would not use any extra space if destination uses deduplicating storage, because these blocks are also present in one or more disk images located on the destination. Copying matched data into sequence cache allows teleporter to stay performant even if the teleported files are modified or deleted (see Sect. 2.16).
Whenever items are evicted from the C2 cache, corresponding sequences are evicted from the sequence cache. In order to be able to do it, teleporter maintains a sequence bitmap file (each bit represents a sequence cache entry) with sequence starts set to “1”.
2.15 Promotion Process
Once a match is found in C0/C1, we promote it to C2. After that we trace two block sequences forward until a mismatch is found. References to the first mismatched blocks are added to C1. Every strong head in the sequence is promoted to C2 as well.
Since C2 cache is backed by the sequence cache, every time a change is made to the C2 cache, corresponding change must be made to the sequence cache. Since promotion from C0/C1 is the only way to add entries into C2, data file of the sequence cache can be updated by copying data locally on the destination from the disk image pointed to by C0/C1.
When adding sequences to the hash file of the sequence cache, teleporter is trying to avoid cases when sequences cross a boundary between 4 KB hash file segments (128 hashes per segment), as this would generate extra reads during C2 matches. Instead, we maintain linked lists of gaps in the hash file - one list per gap size. If the sequence doesn’t fit into the remainder of the segment, it is instead written to the beginning of the next segment, and the resulting gap is added to the linked list of the appropriate gap size. If the linked list corresponding to the sequence size is not empty, we fill the gap and remove the entry from the list. Since teleporter does not write sequences to hash file consecutively, it must communicate information about the gaps to the destination endpoint (together with the rest of the match info), so that data blocks could be written to the correct offsets in the data file of the sequence cache.
2.16 Handling Invalidated Blocks
Destination endpoint must be able to handle the case when one of the recently teleported files was modified (or even deleted) after teleportation. Note that this is not a problem if the data is reused as a result of a C2 match - in this case block data is copied from the sequence cache, where it couldn’t be invalidated. The process that results from a C0/C1 match is shown in Fig. 12.

Handling invalidated blocks.
Destination endpoint computes the hash of each block [❶] it was instructed to reuse, and compares the newly computed hash with the hash it received from the teleporter. If the hashes didn’t match (or the file was deleted), destination endpoint requests block data from the source [❷, ❸]. When the data is received, destination endpoint writes it both to the sequence cache [❹], and to the disk image being teleported [❺]. Since most matches happen in C2, overhead of extra hashing in step [❶] is modest.
Note that no communication with the teleporter is required to handle invalidated blocks. When teleporter finds a match in C0 or C1, the matching hash is promoted to C2 (see Sect. 2.15). This is exactly what happens on the destination, whether the block data was invalidated or not.
Destination teleporter requests invalidated blocks in batches and uses the pipelining paradigm (see Sect. 2.1).
2.17 Grain Table Compression
Teleportation matches can come from 32 different recently-teleported sparse files, and keeping their grain tables in memory may consume hundreds of MBs. We have observed guest file systems frequently form long sequential or reverse-sequential ranges of grains. Source endpoint encodes grain tables as a sorted sequence of grain ranges before sending it to the destination endpoint. Such representation is typically hundreds of times more compact. Destination endpoint keeps this compact representation in memory for recently teleported files, and uses binary search when retrieving matched blocks.
3 Evaluation
We have developed a fully functional standalone teleportation prototype in Java and used it to transfer a library of disk images between two laptops using 1 Gbps network. We have placed 30 disk images on the source laptop; the destination laptop contained no disk images. All the caches on the destination (both in-memory and on-disk) were initially empty, they were populated during teleportation. We have compared teleportation vs compression when sending disk images to the destination. When using teleportation, we have compressed the blocks which failed to teleport (Sect. 2.4).
3.1 Platform
All our experiments ran on two identical MacBook Pro laptops using 1 Gbps network:
CPU: | 1 x Intel Core i7 @ 2.5 GHz |
Cores: | 4 |
Caches: | 256 KB L2 (per core), 6 MB L3 |
Memory: | 16 GB |
Storage: | 1 TB SSD |
Storage benchmark (done with Xbench):
Random 4K Read: | 41.32 MB/sec (10,578 IOPS) |
Sequential Read: | 929.68 MB/sec |
Sequential Write: | 698.74 MB/sec |
Note that the storage we tested with is quite slow. For comparison, VMware ESX is able to exceed one million IOPS for a single NVMe device, about 100 times faster than the storage we tested with.
3.2 Disk Image Library
We have obtained 30 thinly-provisioned disk images from another team. Images ranged in size from 4.7 GB to 18.8 GB (9.9 GB on average). We have mimicked real-life image distribution by the operating system (Fig. 13) and by the file system (Fig. 14). Average image size when flattened was 41.5 GB.

Disk image library by the operating system.

Disk image library by the file system.
3.3 Head Recognition
We have manually constructed the database of “magic numbers” based on one Windows and one Linux disk image. Checking for one or two zeroes at the end of a block worked poorly in practice due to an excessive number of false positives (for example, every block containing Unicode text at the end would end with a zero). We have experimentally determined that checking for 5 or more zeroes works well. In our experiments, head recognition reduced memory requirements by 90.4%, while reducing teleportation rate by only 5%.
3.4 Compression
The most commonly used compression algorithm DEFLATE [5] compresses at only 0.6 Gbps, which is too slow for our needs. We have used LZ4 compression algorithm [6]. LZ4 is compressing at the speed of 3.2 Gbps. We have only used 1 thread for compression, but have tested LZ4 compression running on 4 threads running in parallel, with linear increase in performance. LZ4 compression ratio is not as good as DEFLATE - it reduces the typical VM content by about 35%.
3.5 Network Throughput
Teleporter effectiveness depends on the rate of teleportation matches. Fortunately for us, this rate is exactly the same as the rate of storage deduplication for disk images - an area which was extensively studied before. Overlap between pairs of different installations of either Windows or the same distribution of Linux was studied in [7] - it turned out to be roughly 93% regardless of the OS. A different study [8] has applied deduplication to a set of 52 VM disk images (in VMware format) with different operating systems and application environments, and reported space savings of over 80%. Yet another study [9] has analyzed sets of VM disk images across 36 different tenants and concluded that applying deduplication across tenants has resulted in 80% savings. Finally, a VMware study [10] has applied deduplication to a randomly chosen set of 113 VM disk images (1.3 TB) and realized 80% space savings.
Our sample library didn’t quite reach 80% deduplication rate, it maxed out at 75%. We attribute this to its small size. Moreover, since the head recognition is not 100% effective, we could only match about 70% of the blocks. However, compressing the blocks which failed to teleport have increased the effective teleportation rate (defined as “reduction in the amount of data sent over the network”) up to 80.7% (see Fig. 15). This number includes the overhead of sending hashes, bit arrays, sparse file headers, etc. When compared to compression, this is an improvement of 3.4x.

Teleportation rate.
3.6 Hashing Performance
Out of 256-bit cryptographic hashes we chose BLAKE2 [11], because it is optimized for speed in software (as opposed to hardware). BLAKE2b is further optimized for 64-bit platforms. BLAKE2b operates at 7.12 Gbps, which was fast enough for our needs. We have only used 1 thread for hashing, but have tested BLAKE2b running on 4 threads in parallel, with linear increase in performance.
3.7 Disk I/O Amplification
Strong and weak heads combined represent approximately 10% of all blocks, the rest of the blocks are not looked up in the cache. First, let’s look at the worst case - no blocks got matched. 3% of the unsuccessful lookups generate one unnecessary disk read. Since we lookup 10% of the blocks, completely unsuccessful teleportation would generate 0.3% read amplification. Next, let’s look at the best case - all blocks got matched. In our experiments we have observed that the length of the average teleported sequence is 86 blocks (we are fairly confident in this number, as it strongly correlates with the average file size in the guest file system). Completely successful teleportation would generate 100/86 = 1.16% read amplification.
In summary, teleporter produces between 0.3% and 1.16% read amplification, closer to the upper bound for datasets which teleport better and closer to the lower bound for datasets which teleport worse. Teleporter writes out hashes for every transferred 4 KB block, which is 0.78% write amplification.
3.8 Memory Footprint
Comparing to the conventional LRU implementation with double-linked lists, Cuckoo LRU (Sect. 2.9) allowed us to save three 8-byte pointers per cache entry. In combination with hash file addressing (Sect. 2.11), and 1-byte fingerprint replacing 32-byte hash, this allowed us to use 15x less memory per cache entry (4 bytes instead of 60 bytes).
The size of the short-term caches (C0, C1) is a largely driven by head recognition filtering out 90.4% of the hashes (see Sect. 3.3) and the fact that only teleportation failures (30%, see Sect. 3.5) remain in short-term caches. Teleporting 100 GB of disk image data would only fill 2.88 MB of short-term cache memory. Our prototype has used 4 MB for C1 and 12 MB for C0. Without the techniques we proposed, short-term caches would occupy 10 * 15 = 150x more memory.
Since the long-term cache C2 only contains sequences, its size is a factor of an average sequence length. In our experiments average sequence length was 86 blocks (Sect. 3.7), so in order to support 8 TB sequence cache (Sect. 2.14) using 93 MB for the C2 cache would be sufficient. Our prototype has used 16 MB for C2. Without the techniques we proposed, C2 cache would occupy 86 * 15 = 1,290x more memory.
Together, our caches have occupied (1290 + 150)/2 = 720x less memory than a conventional implementation, or 32 MB instead of 23 GB. Such a dramatic decrease in memory footprint is what makes teleportation commercially viable.
3.9 Transfer Speed
Our test environment had atypically fast network (we used 1 Gbps LAN instead of a WAN), and atypically slow storage (see Sect. 3.1). In our experiments, teleportation has reduced network traffic enough that writing blocks to disk at the destination became a bottleneck and capped potential gains in copy time. We did teleportation in two phases. During the 1st phase (“network”), data stream that failed to teleport was written (while still compressed) to a delta file on the destination, and match info was written into a write-ahead log on the destination. During the 2nd phase (“merge”), teleported file was assembled from the delta file and the sequence cache. We have measured the network phase time separately from the total time. Network phase of teleporting our sample disk image library (Fig. 16, gray) was 4 times faster than a regular network copy. Full teleportation (Fig. 16, orange) was twice faster than a network copy and 24% faster than compression.

Time savings: network phase (gray) and total (orange). (Color figure online)
We estimate that in a typical scenario storage is fast enough that even when sending several times less data over the network, network would remain a bottleneck. If this is the case, we expect teleportation to be up to 3.4x faster than compression and up to 5x faster than a regular network copy (see Sect. 3.5).
4 Related Work
Rsync [12] was one of the inspirations for us. Rsync starts with identifying two files a and b which are likely to be different versions of the same file. Rsync then hashes 4 KB segments of file a and uses a rolling checksum to find them in file b. Rolling checksum is guarding against inserting or removing bytes near the start of the file.
LBFS [13] builds on the ideas of Rsync and extends them to a file system. LBFS divides the files into variable-size chunks using Rabin fingerprints and indexes the chunks by hash value. LBFS is geared towards networks slower than 10 Mbps.
More recently, a number of papers [18,19,20,21] were written on the topic of using compare-by-hash to improve transfers of VMs over a WAN. To the best of our knowledge, we are the first to call attention to the memory footprint of such systems. The techniques we proposed allowed us to reduce the memory footprint by a factor of 720x (Sect. 3.8), while keeping disk I/O amplification (Sect. 3.7) under 2%.
Valerie Aurora has suggested in [14] that compare-by-hash should not be used for certain applications, such as file systems (but applications like Rsync are OK). Valerie’s paper is using SHA-1 hash as an example. Rebuttal paper [15] was published specifically to addresses Valerie’s concerns. Many papers [12, 13, 16, 19] were written with an explicit assumption to ignore cryptographic hash collisions.
We further address compare-by-hash concerns by using a stronger hash - 256-bit BLAKE2 [11] is 296 times stronger than SHA-1. For the cache sizes we are proposing (up to 228 entries), collisions in 256-bit hashes reduce teleporter reliability only down to 99.9999999999999999999999999999992% (32 nines), which favorably compares to reliability guarantee of Amazon’s AWS S3 of 99.9999999991 (11 nines) [17].
5 Conclusion
In this paper we have shown that teleportation can improve network throughput of VM transfers over WAN by a factor of 3.4x (when comparing to compression). In addition to the use cases of edge computing and hybrid clouds, teleportation would improve VM mobility across clusters and datacenters, large-scale load-balancing, hardware upgrades (including whole datacenter upgrades and datacenters with shared-nothing storage architectures), and disaster preparedness testing. Teleportation would also improve use cases when VMs are not transferred live, such as VM template distribution, onboarding and backup/restore.
References
VMware Virtual Disk Format 5.0. https://www.vmware.com/support/developer/vddk/vmdk_50_technote.pdf. Accessed 26 Dec 2018
Pagh, R., Rodler, F.: Cuckoo hashing. J. Algorithms 2, 122–144 (2004)
Erlingsson, U., Manasse, M., Mcsherry, F.: A cool and practical alternative to traditional hash tables. In: Proceedings of 7th Workshop on Distributed Data and Structures (2006)
Fan, B., Andersen, D.G., Kaminsky, M., Mitzenmacher, M.D.: Cuckoo filter: practically better than Bloom. In: Proceedings of the 10th ACM International on Conference on Emerging Networking Experiments and Technologies, pp. 75–88. ACM (2014)
Deutsch, P.: DEFLATE Compressed Data Format Specification version 1.3. https://tools.ietf.org/html/rfc1951. Accessed 26 Dec 2018
LZ4 - Extremely fast compression. http://www.lz4.org. Accessed 26 Dec 2018
Liguori, A., Van Hensbergen, E.: Experiences with content addressable storage and virtual disks. In: Proceedings of the First Workshop on I/O Virtualization (2008)
Jin, K., Miller, E.: The effectiveness of deduplication on virtual machine disk images. In: Proceedings of SYSTOR 2009: The Israeli Experimental Systems Conference (2009)
Nath, P., Kozuch, M., O’Hallaron, D., Harkes, J., Satyanarayanan, M.: Design tradeoffs in applying content addressable storage to enterprise-scale systems based on virtual machines. In: Proceedings of the 2006 USENIX Annual Technical Conference (2006)
Clements, A., Ahmad, I., Vilayannur, M., Li, J.: Decentralized deduplication in SAN cluster file systems. In: Proceedings of USENIX Annual Technical Conference (2009)
Aumasson, J.-P., Neves, S., Wilcox-O’Hearn, Z., Winnerlein, C.: BLAKE2: simpler, smaller, fast as MD5. In: Jacobson, M., Locasto, M., Mohassel, P., Safavi-Naini, R. (eds.) ACNS 2013. LNCS, vol. 7954, pp. 119–135. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-38980-1_8
Tridgell, A., Mackerras, P.: The Rsync algorithm. In: Technical Report TR-CS-96-05, Department of Computer Science, The Australian National University, Canberra (1996)
Muthitacharoen, A., Chen, B., Mazieres, D.: A low-bandwidth network file system. In: Proceedings of 18th ACM Symposium Operating Systems Principles. ACM Press (2001)
Henson, V.: An analysis of compare-by-hash. In: Workshop on Hot Topics in Operating Systems (HotOS) (2003)
Black, J.: Compare-by-hash: a reasoned analysis. In: Proceedings of the Systems and Experience Track: 2006 USENIX Annual Technical Conference (2006)
Quinlan, S., Dorward, S.: Venti: a new approach to archival storage. In: Proceedings of the USENIX Conference on File And Storage Technologies (FAST) (2002)
Amazon S3 Storage Classes. https://aws.amazon.com/s3/storage-classes/. Accessed 26 Dec 2018
Zhang, X., Huo, Z., Ma, J., Meng, D.: Exploiting data deduplication to accelerate live virtual machine migration. In: IEEE International Conference on Cluster Computing (2010)
Riteau, P., Morin, C., Priol, T.: Shrinker: improving live migration of virtual clusters over WANs with distributed data deduplication and content-based addressing. In: Jeannot, E., Namyst, R., Roman, J. (eds.) Euro-Par 2011. LNCS, vol. 6852, pp. 431–442. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-23400-2_40
Wood, T., et al.: CloudNet: dynamic pooling of cloud resources by live WAN migration of virtual machines. IEEE/ACM Trans. Netw. 23, 1568–1583 (2015)
Ha, K., et al.: You can teach elephants to dance: agile VM handoff for edge computing. In: Proceedings of the Second ACM/IEEE Symposium on Edge Computing (2017)
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Zaydman, O., Zhirin, R. (2019). Teleportation of VM Disk Images Over WAN. In: Da Silva, D., Wang, Q., Zhang, LJ. (eds) Cloud Computing – CLOUD 2019. CLOUD 2019. Lecture Notes in Computer Science(), vol 11513. Springer, Cham. https://doi.org/10.1007/978-3-030-23502-4_7
Download citation
DOI: https://doi.org/10.1007/978-3-030-23502-4_7
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-23501-7
Online ISBN: 978-3-030-23502-4
eBook Packages: Computer ScienceComputer Science (R0)