
Abstract
Recent work has integrated semantics into the 3D scene models produced by visual SLAM systems. Though these systems operate close to real time, there is lacking a study of the ways to achieve real-time performance by trading off between semantic model accuracy and computational requirements. ORB-SLAM2 provides good scene accuracy and real-time processing while not requiring GPUs [1]. Following a ‘single view’ approach of overlaying a dense semantic map over the sparse SLAM scene model, we explore a method for automatically tuning the parameters of the system such that it operates in real time while maximizing prediction accuracy and map density.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

Notes
- 1.
We use pydensecrf, available at github.com/lucasb-eyer/pydensecrf.
- 2.
To measure conditional mutual information, we used the scikit-feature feature selection library available at github.com/jundongl/scikit-feature.
References
Bodin, B., et al.: SLAMBench2: multi-objective head-to-head benchmarking for visual SLAM. In: 2018 IEEE International Conference on Robotics and Automation (ICRA), pp. 1–8 (2018)
Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Semantic image segmentation with deep convolutional nets and fully connected CRFs. In: ICLR (2015). http://arxiv.org/abs/1412.7062
Dai, A., Chang, A.X., Savva, M., Halber, M., Funkhouser, T., Nießner, M.: ScanNet: richly-annotated 3D reconstructions of indoor scenes. In: Proceedings of the Computer Vision and Pattern Recognition (CVPR). IEEE (2017)
Häne, C., Zach, C., Cohen, A., Angst, R., Pollefeys, M.: Joint 3D scene reconstruction and class segmentation. In: 2013 IEEE Conference on Computer Vision and Pattern Recognition, pp. 97–104, June 2013. https://doi.org/10.1109/CVPR.2013.20
Hinton, G.E.: Training products of experts by minimizing contrastive divergence. Neural Comput. 14(8), 1771–1800 (2002). https://doi.org/10.1162/089976602760128018
Howard, A.G., et al.: MobileNets: efficient convolutional neural networks for mobile vision applications. CoRR abs/1704.04861 (2017). http://arxiv.org/abs/1704.04861
Krähenbühl, P., Koltun, V.: Efficient inference in fully connected CRFs with Gaussian edge potentials. In: Shawe-Taylor, J., Zemel, R.S., Bartlett, P.L., Pereira, F., Weinberger, K.Q. (eds.) Advances in Neural Information Processing Systems 24, pp. 109–117. Curran Associates, Inc. (2011). http://papers.nips.cc/paper/4296-efficient-inference-in-fully-connected-crfs-with-gaussian-edge-potentials.pdf
Kundu, A., Li, Y., Dellaert, F., Li, F., Rehg, J.M.: Joint semantic segmentation and 3D reconstruction from monocular video. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8694, pp. 703–718. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10599-4_45
Li, X., Belaroussi, R.: Semi-dense 3D semantic mapping from monocular SLAM. CoRR abs/1611.04144 (2016). http://arxiv.org/abs/1611.04144
McCormac, J., Handa, A., Davison, A.J., Leutenegger, S.: SemanticFusion: dense 3D semantic mapping with convolutional neural networks. In: 2017 IEEE International Conference on Robotics and Automation (ICRA), pp. 4628–4635 (2017)
Mur-Artal, R., Tardós, J.D.: ORB-SLAM2: an open-source SLAM system for monocular, stereo and RGB-D cameras. IEEE Trans. Robot. 33(5), 1255–1262 (2017). https://doi.org/10.1109/TRO.2017.2705103
Pillai, S., Leonard, J.: Monocular SLAM supported object recognition. In: Proceedings of Robotics: Science and Systems (RSS), Rome, Italy, July 2015
Rublee, E., Rabaud, V., Konolige, K., Bradski, G.: ORB: an efficient alternative to SIFT or SURF. In: 2011 IEEE International Conference on Computer Vision (ICCV), pp. 2564–2571. IEEE (2011)
Sünderhauf, N., et al.: Place categorization and semantic mapping on a mobile robot. In: IEEE International Conference on Robotics and Automation (ICRA 2016), Stockholm, Sweden. IEEE, May 2016
Vineet, V., et al.: Incremental dense semantic stereo fusion for large-scale semantic scene reconstruction. In: 2015 IEEE International Conference on Robotics and Automation (ICRA), pp. 75–82, May 2015. https://doi.org/10.1109/ICRA.2015.7138983
Whelan, T., Leutenegger, S., Moreno, R.S., Glocker, B., Davison, A.: ElasticFusion: dense SLAM without a pose graph. In: Proceedings of Robotics: Science and Systems, Rome, Italy, July 2015. https://doi.org/10.15607/RSS.2015.XI.001
Zheng, S., et al.: Conditional random fields as recurrent neural networks. In: ICCV, pp. 1529–1537 (2015)
Acknowledgements
The authors gratefully acknowledge the support of the EPSRC grants LAMBDA (EP/N035127/1), PAMELA (EP/K008730/1), and RAIN (EP/R026084/1).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
A Appendix: Multi-view Semantic Map Construction with Feature-Based SLAM
A Appendix: Multi-view Semantic Map Construction with Feature-Based SLAM
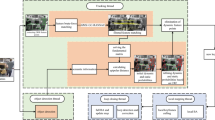
In this section we describe a multi-view approach to associating semantic predictions with the 3D scene model of ORB-SLAM2, by using the correspondence between keypoints in different frames recorded by the SLAM system to combine predictions. We show that this approach—similar to SemanticFusion [10]—has drawbacks when used with sparse, feature-based SLAM systems.
We have modified ORB-SLAM2 to, for each keyframe, pass the (x, y) positions of keypoints to the code implementing the segmentation network. The segmentation network performs inference on each keyframe, and passes the prediction probability vector for each keypoint back to ORB-SLAM2. ORB-SLAM2 then computes an aggregate prediction for each MapPoint by combining the predictions of the associated keypoints. This setup is illustrated in Fig. 6. The aggregate MapPoint prediction probabilities were computed by taking the element-wise product of the keypoint prediction probabilities and then renormalizing. This is like a product of experts in ensemble machine learning methods [5]. Other aggregation methods were tried, such as taking the arithmetic mean or a maximum vote, with similar results.

Class label predictions from a deep network for semantic segmentation are made based on multiple views of the same objects and then associated with parts of the 3D model constructed by the SLAM system.
We report the accuracy of the segmentation network across all pixels and across all keypoints in the test set, and the accuracy of the 3D semantic map based on multi-view (aggregate) feature predictions. For each of these, we compute the ‘overall accuracy’, which is the total proportion of correctly classified pixels or MapPoints, and the ‘per-class accuracy’, which is the mean of the proportion of correctly classified pixels or MapPoints for each class.
These results are shown in Table 3. The first three rows show the accuracies computed for various settings of the parameters described in Sect. 5.1. The first row gives the results for setting the parameters to maximize accuracy at the cost of increased computation; the full network is used, with width multiplier \(w=1.0\), there is no cropping, rescaling, or frame skipping, and we apply \(I=5\) CRF iterations. The second row shows the results with the same parameters, but without any CRF post-processing. For the third row the parameters are the same as the first, but with the ‘half width’ network, with \(w=0.5\).
The multi-view per-feature predictions consistently give a two to three percentage point improvement in accuracy over the per-frame per-feature accuracy; combining predictions does result in increased accuracy. This low improvement—compared to the three to seven percentage point improvement seen from multiview predictions in SemanticFusion—seems to be due to low diversity amongst predictions based on multiple views; in cases where the multiview predictions are wrong, the corresponding pairwise single view predictions (i.e., the predictions being combined) are the same in approximately \(75\%\) of cases, and the KL-divergence of the pairwise prediction probabilities are low. These diversity measures are shown in Table 4. This low diversity may in turn be due to ORB features being invariant under only small changes in orientation and scale, so that the multiple views that are combined are very similar.
Another feature of the results is that restricting predictions to only keypoints—as we are required to in order to take advantage of ORB-SLAM2 to combine predictions from multiple views—results in a reduction in accuracy by around 3–6 percentage points compared to the accuracy measured over all pixels; this drop in accuracy more than compensates for the increase in accuracy that comes from combining predictions from multiple views. This may be because ORB features are likely to be found on corners and edges, and so may be likely to be found on the boundary between objects. These points will be harder to classify, and a lower accuracy will result if the segmentation edges do not align well with object edges. Some evidence is lent to this interpretation by the fact that the drop in accuracy when restricting predictions to keypoints is higher when no CRF iterations are applied, as seen in Table 3, and that the use of the CRF drastically reduces the KL-divergence between predictions associated with the same MapPoint, as shown in Table 4; the CRF, by aligning segmentation edges with object edges, has removed a major source of uncorrelated errors between predictions.
In the multiview setting, a surprisingly small number of observations/predictions are associated with each MapPoint; the mean number of observations per MapPoint is a little over four. It is possible to modify ORB-SLAM2 to create more keyframes per frame. The final row of Tables 3 and 4 give the results for a modified version of ORB-SLAM2, with a mean number of 7.0 observations per MapPoint. This modified version still shows only a small improvement in accuracy for multiview predictions over single view predictions.
In this section, we have shown that the popular method of combining predictions from multiple views in conjunction with a SLAM system to build a 3D semantic map is not suitable in the sparse, feature-based SLAM setting. Restricting predictions to ORB-SLAM2 keypoints, as is required for the multiview approach, reduces the semantic map accuracy by more than the increase in accuracy from combining predictions from multiple views can compensate for, suggesting that multiview semantic map construction using a sparse, feature-based SLAM system is not viable if the features are likely to appear on object boundaries, as will often be the case. It may be possible to do multiview prediction with a feature-based SLAM system by modifying the features such that they are more likely to appear in object interiors, but this is likely to affect SLAM tracking performance.
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Webb, A.M., Brown, G., Luján, M. (2019). ORB-SLAM-CNN: Lessons in Adding Semantic Map Construction to Feature-Based SLAM. In: Althoefer, K., Konstantinova, J., Zhang, K. (eds) Towards Autonomous Robotic Systems. TAROS 2019. Lecture Notes in Computer Science(), vol 11649. Springer, Cham. https://doi.org/10.1007/978-3-030-23807-0_19
Download citation
DOI: https://doi.org/10.1007/978-3-030-23807-0_19
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-23806-3
Online ISBN: 978-3-030-23807-0
eBook Packages: Computer ScienceComputer Science (R0)