
Abstract
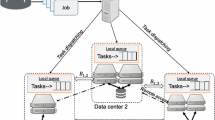
Geo-distributed data processing is affected by many factors, some countries or regions prohibit the transmission of original user data abroad. Therefore, it is necessary to adopt a non-centralized processing method for these data, but at the same time, many problems will arise. Firstly, it is unavoidable to transfer job’s intermediate data across regions, which will result in data transmission cost. Secondly, the WAN bandwidth is often much smaller than the bandwidth within clusters, which makes it easier to become the bottleneck of geo-distributed job. In addition, because the idle computing resources in the cluster may change with time, it will also cause some difficulties in task scheduling. Therefore, this paper considers the problem of task scheduling for big data jobs on geo-distributed data, considering the budget constraints on intermediate data trans-regional transmission, and without moving the original data. we design a budget-constrained task scheduling strategy CETS. Through the experimental analysis of different scenarios, the effectiveness of the proposed algorithm strategy is verified.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Pu, Q., et al.: Low latency geo-distributed data analytics. ACM SIGCOMM Comput. Commun. Rev. 45(4), 421–434 (2015)
Vulimiri, A., Curino, C., Godfrey, P.B., Jungblut, T., Padhye, J., Varghese, G.: Global analytics in the face of bandwidth and regulatory constraints (2017)
Preguiça, K., Rodrigues, R.: Pixida: optimizing data parallel jobs in bandwidth-skewed environments. In: Proceedings of VLDB Endowment (2015)
Hu, Z., Li, B., Luo, J.: Flutter: scheduling tasks closer to data across geo-distributed datacenters. In: IEEE INFOCOM 2016-The 35th Annual IEEE International Conference on Computer Communications, pp. 1–9. IEEE (2016)
Zaharia, M., Chowdhury, M., Franklin, M.J., Shenker, S., Stoica, I.: Spark: cluster computing with working sets. HotCloud 10(10–10), 95 (2010)
Dean, J., Ghemawat, S.: MapReduce: simplified data processing on large clusters. Commun. ACM 51(1), 107–113 (2008)
Jayalath, C., Eugster, P.: Efficient geo-distributed data processing with rout. In: 2013 IEEE 33rd International Conference on Distributed Computing Systems, pp. 470–480. IEEE (2013)
Olston, C., Reed, B., Srivastava, U., Kumar, R., Tomkins, A.: Pig Latin: a not-so-foreign language for data processing. In: Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, pp. 1099–1110. ACM (2008)
Afrati, F., Dolev, S., Sharma, S., Ullman, J.D.: Meta-MapReduce: a technique for reducing communication in MapReduce computations arXiv preprint arXiv:1508.01171 (2015)
Gadre, H., Rodero, I., Parashar, M.: Investigating MapReduce framework extensions for efficient processing of geographically scattered datasets. ACM SIGMETRICS Perform. Eval. Rev. 39(3), 116–118 (2011)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Xie, L., Dai, Y., Zhu, Y., Li, X., Li, X., Qian, Z. (2019). Cost-Efficient Task Scheduling for Geo-distributed Data Analytics. In: Wang, G., Feng, J., Bhuiyan, M., Lu, R. (eds) Security, Privacy, and Anonymity in Computation, Communication, and Storage. SpaCCS 2019. Lecture Notes in Computer Science(), vol 11637. Springer, Cham. https://doi.org/10.1007/978-3-030-24900-7_8
Download citation
DOI: https://doi.org/10.1007/978-3-030-24900-7_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-24899-4
Online ISBN: 978-3-030-24900-7
eBook Packages: Computer ScienceComputer Science (R0)