
Abstract
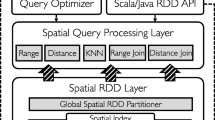
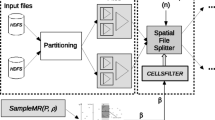
Based on Spark platform, we propose an efficient top-k spatial join query processing algorithm on big spatial data, in which, the whole data space is divided into same-sized cells by using a grid partitioning method. Then spatial objects in two data sets are projected and replicated to these cells by projection and replication operations respectively, meanwhile a filtering operation is used to speed up the processing. After that, an R-tree based local top-k spatial join algorithm is proposed to compute the top-k candidate results in each cell, which extends the traditional R-tree index and combines threshold filtering techniques to reduce the communication and computation costs, therefore speeding up the query processing. Experimental results on synthetic data sets show that the proposed algorithm is significantly better than the existing top-k spatial join query processing algorithms in performance.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Zhu, M., Papadias, D., Lun Lee, D., Zhang, J.: Top-k spatial joins. IEEE Trans. Knowl. Data Eng. 17(4), 567–579 (2005)
Govindarajan, S., Agarwal, P.K., Arge, L.: CRB-tree: an efficient indexing scheme for range-aggregate queries. In: Calvanese, D., Lenzerini, M., Motwani, R. (eds.) ICDT 2003. LNCS, vol. 2572, pp. 143–157. Springer, Heidelberg (2003). https://doi.org/10.1007/3-540-36285-1_10
Tao, Y., Papadias, D.: Range aggregate processing in spatial databases. IEEE Trans. Knowl. Data Eng. 16(12), 1555–1570 (2004)
Ljosa, V., Singh, A.K.: Top-k spatial joins of probabilistic objects. In: Proceedings of the 24th International Conference on Data Engineering, pp. 566–575 (2008)
Aji, A., et al.: Hadoop-GIS: a high performance spatial data warehousing system over MapReduce. PVLDB 6(11), 1009–1020 (2013)
Eldawy, A., Mokbel, M.F.: Spatialhadoop: a mapreduce framework for spatial data. In: ICDE Conference, pp. 1352–1363 (2015)
You, S., Zhang, J., Gruenwald, L.: Large-scale spatial join query processing in cloud. In: ICDE Workshops, pp. 34–41 (2015)
Yu, J., Wu, J., Sarwat, M.: Geospark: a cluster computing framework for processing large-scale spatial data. In: SIGSPATIAL Conference, pp. 70:1–70:4 (2015)
Tang, M., Yu, Y., Malluhi, Q.M., Ouzzani, M., Aref, W.G.: Locationspark: a distributed in-memory data management system for big spatial data. PVLDB 9(13), 1565–1568 (2016)
You-Zhong, M.A., Xiang, C.I., Meng, X.-F.: Parallel top-k join on massive high-dimensional vectors. Chin. J. Comput. 38(1), 86–98 (2015). (in Chinese)
Kim, Y., Shim, K.: Parallel top-k similarity join algorithms using MapReduce. In: Proceedings of the 28th International Conference on Data Engineering, pp. 510–521 (2012)
Xu, H., Ding, X., Jin, H., Jiang, W.: Parallel top-k, query processing on uncertain strings using MapReduce. In: Proceedings of the 20th International Conference on Database Systems for Advanced Applications, pp. 89–103 (2015)
Liu, Y., Chen, L., Jing, N., Liu, L.: Parallel top-k spatial join query processing on massive spatial data. J. Comput. Res. Dev. 48(1), 163–172 (2011). (in Chinese)
Zhang, S., Han, J., Liu, Z., Wang, K., Xu, Z.: SJMR: parallelizing spatial join with Mapreduce on clusters. In: Proceedings of the IEEE International Conference on Cluster Computing, pp. 1–8 (2009)
Acknowledgements
This research was supported by the National Key R&D Program of China (NO. 2016YFC1401900 and 2018YFB1004402) and National Natural Science Foundation of China (No. 61872072 and 61073063).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Qiao, B., Hu, B., Qiao, X., Yao, L., Zhu, J., Wu, G. (2019). An Efficient Top-k Spatial Join Query Processing Algorithm on Big Spatial Data. In: Shao, J., Yiu, M., Toyoda, M., Zhang, D., Wang, W., Cui, B. (eds) Web and Big Data. APWeb-WAIM 2019. Lecture Notes in Computer Science(), vol 11642. Springer, Cham. https://doi.org/10.1007/978-3-030-26075-0_21
Download citation
DOI: https://doi.org/10.1007/978-3-030-26075-0_21
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-26074-3
Online ISBN: 978-3-030-26075-0
eBook Packages: Computer ScienceComputer Science (R0)