
Abstract
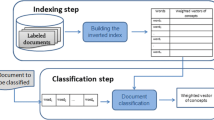
Traditional multi-label text classifiers suffer from the high dimensionality of feature space, label imbalance, and training overhead. In this work, we depart from traditional approaches with intensive feature engineering and linguistic analysis by introducing a novel ontology-based training-less multi-label text classifier. We transform the classification task into a graph matching problem to have a training-less classifier. The experiment results, using the EUR-Lex dataset, proved that our method offers competitive performance with respect to the above-mentioned approaches in terms of \(F1_{macro}\) giving fair performance over the different labels despite of the training-less configurations.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Alkhatib, W., Rensing, C., Silberbauer, J.: Multi-label text classification using semantic features and dimensionality reduction with autoencoders. In: Gracia, J., Bond, F., McCrae, J.P., Buitelaar, P., Chiarcos, C., Hellmann, S. (eds.) LDK 2017. LNCS (LNAI), vol. 10318, pp. 380–394. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-59888-8_32
Alkhatib, W., Sabrin, S., Neitzel, S., Rensing, C.: Towards ontology-based training-less multi-label text classification. In: Silberztein, M., Atigui, F., Kornyshova, E., Métais, E., Meziane, F. (eds.) NLDB 2018. LNCS, vol. 10859, pp. 389–396. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-91947-8_40
Bojanowski, P., Grave, E., Joulin, A., Mikolov, T.: Enriching word vectors with subword information. arXiv preprint arXiv:1607.04606 (2016)
Hearst, M.A.: Automatic acquisition of hyponyms from large text corpora. In: Proceedings of the 14th conference on Computational linguistics-Volume 2, pp. 539–545. Association for Computational Linguistics (1992)
Janik, M.G.: Training-less ontology-based text categorization. Ph.D. thesis, UGA (2008)
Mahdisoltani, F., Biega, J., Suchanek, F.: Yago3: a knowledge base from multilingual wikipedias. In: 7th Biennial Conference on Innovative Data Systems Research, CIDR Conference (2014)
Miller, G.A.: WordNet: a lexical database for english. Commun. ACM 38(11), 39–41 (1995)
Speer, R., Havasi, C.: Representing general relational knowledge in ConceptNet 5. In: LREC, pp. 3679–3686 (2012)
Uschold, M., King, M., Moralee, S., Zorgios, Y.: The enterprise ontology. Knowl. Eng. Rev. 13(1), 31–89 (1998)
Zhou, P., El-Gohary, N.: Ontology-based multilabel text classification of construction regulatory documents. J. Comput. Civil Eng. 30(4), 04015058 (2015)
Acknowledgment
This work has been co-funded by the German Federal Ministry of Education and Research (BMBF) within in the framework of the Software Campus project “PIOBRec” [01IS17050].
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Alkhatib, W., Schnitzer, S., Rensing, C. (2019). Training-Less Multi-label Text Classification Using Knowledge Bases and Word Embeddings. In: Douligeris, C., Karagiannis, D., Apostolou, D. (eds) Knowledge Science, Engineering and Management. KSEM 2019. Lecture Notes in Computer Science(), vol 11776. Springer, Cham. https://doi.org/10.1007/978-3-030-29563-9_10
Download citation
DOI: https://doi.org/10.1007/978-3-030-29563-9_10
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-29562-2
Online ISBN: 978-3-030-29563-9
eBook Packages: Computer ScienceComputer Science (R0)