
Abstract
Computational visual attention is a hot topic in computer vision. However, most efforts are devoted to model saliency, whilst the actual eye guidance problem, which brings into play the sequence of gaze shifts characterising overt attention, is overlooked. Further, in those cases where the generation of gaze behaviour is considered, stimuli of interest are by and large static (still images) rather than dynamic ones (videos). Under such circumstances, the work described in this note has a twofold aim: (i) addressing the problem of estimating and generating visual scan paths, that is the sequences of gaze shifts over videos; (ii) investigating the effectiveness in scan path generation offered by features dynamically learned on the base of human observers attention dynamics as opposed to bottom-up derived features. To such end a probabilistic model is proposed. By using a publicly available dataset, our approach is compared against a model of scan path simulation that does not rely on a learning step.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



Keywords
1 Introduction
Real world contains a huge amount of visual information. Indeed, our brain is very skillful in selecting the relevant one so that visual attention is guided to scene regions and events in real time. The same competence would be desirable for machine vision systems, so that relevant information could be gathered and treated with the highest priority.
To such end the fundamental problem concerning what factors guide attention within scenes can be articulated in two related questions: (i) where do we look within the scene and (ii) how we visit regions where attention will be allocated.
The latter issue, which involves the actual mechanism of shifting the gaze from one location of the scene to another (i.e., producing a scan path), is seldom taken into account in computational models of visual attention. By overviewing the field [4, 5, 7, 8, 18], computational modelling of attention has been mainly concerned with the where issue.
As to the latter, at the most general level, approaches span an horizon defined by two theoretical frameworks [15]. On the one side, image guidance theories posit that attention basically is a reaction to the image properties of the stimulus confronting the viewer. The most prominent approach of this type is based on visual salience: resources are allocated to visually salient regions in the scene, relying on a saliency map computed from basic image features such as luminance contrast, colour and edge orientation and motion [5, 7, 8].
On the other side cognitive guidance theories suggest that attention is directed to scene regions that are semantically informative. Visual resources are deployed to scene’s meaningful regions based on experience with general scene concepts and the specific scene instance currently in view. A remarkable early example of cognitive guidance modelling was provided by Chernyak and Stark [9]; more recent works are described in [12, 15, 20,21,22].
In this note, we present a preliminary attempt at balancing image and cognitive guidance of gaze on dynamic stimuli. The main contribution of the work presented here lies in the following:
-
modelling the gaze evolution taking into account three peculiar component: perceptual, cognitive, and motor.
-
exploiting the actual behaviour of eye-tracked observers to learn dynamically which semantically meaningful regions are gazed, and adopt this knowledge to generate new scan paths on unseen videos with the same semantic content.
-
bridging the gap between perceptual features, such as low-level spatial and temporal features, and the cognitive elements captured through semantic components gathered inter-videos.
The remainder of the paper is organized as follows. Sect. 2 introduces the probabilistic model, Sect. 3 gives the implementative details. Experiments are reported in Sect. 4, and Sect. 5 is left to conclusions.
2 Proposed Model
Visual attention deployment in time can be considered as the allocation of visual resources on regions of the viewed scene. In overt attention the signature of such process can be represented by gaze dynamics. Consider such dynamics as described by the stochastic process \(\{ G_t, t>0\}\) and let the time series \(g_1,g_2,\cdots ,g_T\) be a realisation of the process. In the following with some abuse of notation we will use lower case g for both the realisation and the time-varying random variable G; also we adopt the compact notation \(g_{1:T} = \{g_1,g_2,\cdots ,g_T \}\).
Under Markov assumption the joint probability \(p \left( g_{1:T} \right) \) can be written:
Gaze evolution \(g_t \rightarrow g_{t+1}\) can be conceived as the consequence of the evolution of an ensemble of time-varying random variables accounting for the fundamental aspects of attention deployment: (1) the gaze-dependent perception of the external world, (2) the internal cognition state-space (the mind’s eye), (3) the motor behaviour grounding actual gaze dynamics. More precisely, to characterize this dynamic random process, let us define the following random variables.
-
1.
Perceptual component
-
 \(f_t^\text {spatial}\) and \(f_t^\text {temporal}\) collect low-level features accounting for both spatial and temporal domains, respectively.
\(f_t^\text {spatial}\) and \(f_t^\text {temporal}\) collect low-level features accounting for both spatial and temporal domains, respectively. -
 \(w_t{:}\) starting from the spatial features \(f_t^{spatial}\), the semantic components \(w_t\) are derived to describe semantic concepts/objects [13] within the scene independently from their spatial positions.
\(w_t{:}\) starting from the spatial features \(f_t^{spatial}\), the semantic components \(w_t\) are derived to describe semantic concepts/objects [13] within the scene independently from their spatial positions. -
 \(y_t{:}\) starting from \(f_t^\text {temporal}\), they are responsible for capturing where the movements within a scene drive the attention of an observer independently from either the semantic or the task.
\(y_t{:}\) starting from \(f_t^\text {temporal}\), they are responsible for capturing where the movements within a scene drive the attention of an observer independently from either the semantic or the task.
-
-
2.
Cognitive component
-
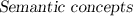 \(z_t{:}\) since an observer progressively allocate the attention to the most relevant parts of the scene depending on either implicit or explicit tasks, \(z_t\) captures high-level semantic contents, such as \(\{\)Person, Car, Street\(\}\). Due to the difficulties to make explicit this cognitive components, they lie in a latent space of categories.
\(z_t{:}\) since an observer progressively allocate the attention to the most relevant parts of the scene depending on either implicit or explicit tasks, \(z_t\) captures high-level semantic contents, such as \(\{\)Person, Car, Street\(\}\). Due to the difficulties to make explicit this cognitive components, they lie in a latent space of categories. -
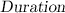 \(s_t{:}\) this is conceived as a “switch” variable controlling the duration of permanence in the latent state \(z_t\), i.e., it approximately regulates gaze dwell time.
\(s_t{:}\) this is conceived as a “switch” variable controlling the duration of permanence in the latent state \(z_t\), i.e., it approximately regulates gaze dwell time.
-
-
3.
Motor component
-
 \(u_t{:}\) this variable denotes the actual spatial point of gaze, accounting for the how problem of overt attention deployment. It is important to note that the prior \(p(u_{t+1}|u_t)\) is useful to incorporate oculomotor biases [16, 19]. For instance it has been shown that saccade amplitudes are likely to follow heavy-tailed laws [1,2,3, 6].
\(u_t{:}\) this variable denotes the actual spatial point of gaze, accounting for the how problem of overt attention deployment. It is important to note that the prior \(p(u_{t+1}|u_t)\) is useful to incorporate oculomotor biases [16, 19]. For instance it has been shown that saccade amplitudes are likely to follow heavy-tailed laws [1,2,3, 6].
-



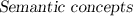
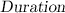

To sum up, the time-varying gaze shift random variable \(g_t=\{ u_t, z_t, s_t, w_t, y_t\}\)Footnote 1 has conditional distribution
Thanks to suitable conditional independence assumptions, Eq. (2) can be simplified as follows:
In other words, in our model of human vision dynamics, gaze brings together low level perceptual components acting as saliency maps, with latent cognitive components playing a central role in task-driven attention [10, 25], together with the prior knowledge of the oculomotor behaviour. The PGM in Fig. 1 represents graphically this idea, highlighting the above conditional probability.

Probabilistic graphical model including conditional independence assumptions established in Eq. (3).
After model learning, gaze shift simulation is obtained by the following generative/sampling process having distribution as in Eq. (3):
Concerning the transition probability \(z_t\rightarrow z_{t+1}\) between (discrete) semantic concepts of the scene conditioned on state duration \(s_{t+1}\), we have
This should be implemented via latent dynamical models, such as HMM [11] or recurrent neural networks (see Sect. 3.2), in which the generation of semantic elements depend on the sampling
In particular, the set of semantic elements assumed by \(w_t\) is determined from low level spatial features \(f_t^\text {spatial}\) adopting either clustering, learning sparse dictionaries [14] or other ensemble techniques as discussed in Sect. 3.1.
From the side of temporal features we simply have
where \(y_t\) is derived from low level temporal features \(f_t^\text {temporal}\) such as optical flow or temporal saliency maps (Sect. 3.1).
The state duration distribution is conditioned on its previous state and on the semantic concept gazed at time t
This can be modelled by computing the empirical distribution of fixations duration on training data and, at test time, by sampling from it.
Finally, we can draw the next gaze shift \(g_t\rightarrow g_{t+1}\) by sampling the distribution
3 Model Implementation
In order to derive the gaze shift generation according to the model outlined in Sect. 2, several implementative choices should be put in place.
3.1 Perceptual and Semantic Components
Spatial perceptual components (\(f^{spatial}\)) should be discriminative and able to consistently describe the local semantic content of image portions (cells), even between videos.
This goal is achieved by resorting to convolutional neural networks (CNN) as feature extractors: given a pool of videos with coherent semantic content (e.g. dialogue between people), we characterize each frame applying the pretrained AlexNet CNNFootnote 2, and extracting the activation produced by the deepest convolutional layer (conv5). More specifically, each frame is scanned by the CNN using overlapping windowsFootnote 3, in order to discard the activation coefficient produced with padding, and keeping only the central activation coefficients. This way, each frame \(v_t\) of a video \(v \in RGB\), s.t. \(|v|=(h \times w \times T)\) is mapped in a \((n \times m)\) grid \(y_t^{spatial}\), where each cell is characterized by a 256-dimensional feature vector. Here, \(n = h/f\) and \(m = w/f\); f being the decimation factor, responsible for the spatial resolution of the scan path generation process.
A succinct vocabulary \(\mathcal {W}=\{w_1,\dots ,w_M\}\), corresponding to the semantic components, is derived applying the k-means algorithm to the \(f^{spatial}\) features.
Quantizing \(y_t^{spatial}\) according to \(\mathcal {W}\) gives rise to the desired semantic content \(w_t\) (Fig. 2).

Examples of \(w_t\) characterizations, obtained quantizing two frames of two different videos, while referring to the same dictionary \(\mathcal {W}\). Notice in the zooms that cells are clustered according to a coherent semantic.
Analogously, \(y_t\) is obtained by averaging over the \((n \times m)\) cells the dense \(f_t^{temporal}\) computed as the video optical flow.
3.2 Latent Cognitive Components
Our approach relies on a supervised method in which the cognitive components lie in a latent space and provide a substantial contribute to estimate gaze shifts. We instantiate the cognitive components in the shape of the hidden space \(z_t\) of an HMM whose emissions \(w_t\) are a finite set of “gazed” visual words, i.e., the semantics providing visible clues of the scene. This allows to accomplish the generation steps described in Eq. (4) for the hidden state, and in Eq. (5) for the visual cues.
Naturally, also in case of indirect task-driven attention, the training phase requires that videos in training and test share a common content (e.g., people or faces, animals, cars), in order to learn visual attention patterns guided by semantics. To such end, the training process requires a collection of saccadic scan paths samples eye-tracked from several observers while viewing the set of videos.
The generation phase uses ancestral sampling directly from the HMM trained on gazed visual words. This gives rise to a frame-based prediction of a new word \(w_{t}\) for each frame t directly sampling from learnt conditional distribution \(p(w_{t}|z_{t})\).
3.3 Motor Component
As proposed in [6] the saccade amplitude distribution is well described by heavy tailed distributions. As a consequence, the motor component can be modeled as a Levy flight or a Markovian process with the shifts following a \(\alpha \)-stable distribution. Following this rationale, the shift prior probability \(p(u_{t+1}|u_t)\) is modelled as a Cauchy 2D distribution (\(\alpha =1\), [1, 6]).
4 Simulation
In the following we present results so far achieved by a preliminary simulation of the model outlined in Sect. 2. In particular we compare with the baseline method described in [3],Footnote 4 which only relies on reactive guidance with respect to the stimulus, while accounting for oculomotor biases (long-tailed distribution of gaze shift amplitudes) much like as we do. It is worth noting that few models are available to compare with that, going beyond classic saliency models, account for the actual generation of gaze shifts; by and large, further available models limit to static stimuli processing [1, 17, 23].
4.1 Dataset
The adopted dataset is the one presented in [24]. It includes fixations of 39 subjects, recorded with an eye tracker at 60 Hz, viewing 65 videos gathered from YouTube and Youku. The database is specialized for multiple-face videos, which contain various numbers of faces varying from 1 to 27. The duration of each video was cut down to be around 20 s and the subjects were asked to free-view videos displayed at random order.
4.2 Experimental Setup
In this preliminary test series, we used several randomly chosen video pairs, one for training e one for test. Both are taken into account for the dictionary construction \(\mathcal {W}\), while only the scan paths of the first video are employed to train the HMM via gazed visual words.
The simulation process is concerned with both the baseline and the proposed approach providing the generation of 50 scan paths for each test video. The whole model has mainly three parameters that affect the performance, namely the grid granularity f, the number of visual words, i.e. number of cluster for the K-means algorithm (M) and the number of hidden states of the HMM (N). These values have been chosen experimentally: optimal values in terms of both quantitative evaluation (section below) and computational cost have been found with \(f=17\), \(M=20\) and \(N=4\). A qualitative assessment of the proposed model can be carried out via the comparison of the fixation density maps.

Visualization of different fixation density maps from human data, baseline method and our proposed approach. The density maps refers to the same frames of three different considered videos in the dataset.
In Fig. 3 we show three examples, extracted from as many videos, of fixation density maps obtained by aggregating all the fixations (either artificial or human) performed in the corresponding frames. At a glance it can be noted that the baseline approach is more attracted by locations that include movements or, more generally, low-level features, despite their semantic value. Differently, the proposed approach seeks the locations that include relevant features in terms of their visual word representation.
4.3 Results
The proposed model is validated quantitatively by comparing the ground truth and generated distributions of observer’s fixations. In particular, for each video frame, a fixation density map is computed by aggregating spatially the fixations of all the available observers, either real or artificial, yielding at each time t, the result exemplified in Fig. 3. The proposed model is then compared to the baseline by computing the Kullback-Leibler Divergence (KLD) between the real and generated density maps. In Fig. 4 the empirical distribution of KL values for both proposed and baseline models is depicted. As can be observed, the proposed model produces on average much lower KLD values if compared to the baseline with a remarkable difference in terms of uncertainty of the distributions.

Histogram plot of the distribution of Kullback-Leibler Divergence values between density maps of real and generated scan paths, using the proposed and baseline methods
5 Conclusions
In this work we propose a model for estimating human scan paths by modeling visual attention over videos. We find that to be effective the generation process should leverage on three primary factors: low-level saliency features, semantic objects identified through cognitive guidance, and oculomotor eye movements. In our model the main role is played by a supervised method focusing on gazed semantic objects that attract the attention during either free or task oriented viewing. This allows to conclude that the ability to reproduce gaze shifts is mainly yielded by a prior distribution on hidden states describing the semantic content of the scenes. Future work will investigate the applicability of our method to other datasets with different semantic contents. Furthermore, other techniques could be adopted to implement the different parts of model. For example clustering could be substituted by learning sparse dictionaries, and HMM by recurrent neural networks. An investigation in these directions should allow us to optimize the implementation in term of both efficiency and efficacy.
Notes
- 1.
Naturally, it holds that \(p\left( w_t |f_t^\text {spatial} \right) \) and \(p\left( y_t|f_t^\text {temporal} \right) \). For sake of simplicity we omit to recall these dependencies.
- 2.
- 3.
Window is 227-by-227 pixel size, according to the AlexNet input.
- 4.
Matlab source code available at http://boccignone.di.unimi.it/Ecological_Sampling.html.
References
Boccignone, G., Ferraro, M.: Modelling gaze shift as a constrained random walk. Physica A 331(1–2), 207–218 (2004)
Boccignone, G., Ferraro, M.: Gaze shift behavior on video as composite information foraging. Signal Process. Image Commun. 28(8), 949–966 (2013)
Boccignone, G., Ferraro, M.: Ecological sampling of gaze shifts. IEEE Trans. Cybern. 44(2), 266–279 (2014)
Boccignone, G., Cuculo, V., D’Amelio, A., Grossi, G., Lanzarotti, R.: Give ear to my face: modelling multimodal attention to social interactions. In: Leal-Taixé, L., Roth, S. (eds.) ECCV 2018. LNCS, vol. 11130, pp. 331–345. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-11012-3_27
Borji, A., Itti, L.: State-of-the-art in visual attention modeling. IEEE Trans. Pattern Anal. Mach. Intell. 35(1), 185–207 (2013)
Brockmann, D., Geisel, T.: The ecology of gaze shifts. Neurocomputing 32(1), 643–650 (2000)
Bruce, N.D., Wloka, C., Frosst, N., Rahman, S., Tsotsos, J.K.: On computational modeling of visual saliency: examining what’s right, and what’s left. Vision Res. 116, 95–112 (2015)
Bylinskii, Z., DeGennaro, E., Rajalingham, R., Ruda, H., Zhang, J., Tsotsos, J.: Towards the quantitative evaluation of visual attention models. Vision. Res. 116, 258–268 (2015)
Chernyak, D.A., Stark, L.W.: Top-down guided eye movements. IEEE Trans. Syst. Man Cybern. B 31, 514–522 (2001)
Clavelli, A., Karatzas, D., Lladós, J., Ferraro, M., Boccignone, G.: Towards modelling an attention-based text localization process. In: Sanches, J.M., Micó, L., Cardoso, J.S. (eds.) IbPRIA 2013. LNCS, vol. 7887, pp. 296–303. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-38628-2_35
Coen-Cagli, R., Coraggio, P., Napoletano, P., Boccignone, G.: What the draughtsman’s hand tells the draughtsman’s eye: a sensorimotor account of drawing. Int. J. Pattern Recognit Artif Intell. 22(05), 1015–1029 (2008)
Cuculo, V., D’Amelio, A., Lanzarotti, R., Boccignone, G.: Personality gaze patterns unveiled via automatic relevance determination. In: Mazzara, M., Ober, I., Salaün, G. (eds.) STAF 2018. LNCS, vol. 11176, pp. 171–184. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-04771-9_14
Fei-Fei, L., Perona, P.: A Bayesian hierarchical model for learning natural scene categories. In: IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), vol. 2, pp. 524–531. IEEE (2005)
Grossi, G., Lanzarotti, R., Lin, J.: Orthogonal procrustes analysis for dictionary learning in sparse linear representation. PLoS ONE 12(1), 1–16 (2017). https://doi.org/10.1371/journal.pone.0169663
Henderson, J.M., Hayes, T.R., Rehrig, G., Ferreira, F.: Meaning guides attention during real-world scene description. Sci. Rep. 8, 10 (2018)
Le Meur, O., Coutrot, A.: Introducing context-dependent and spatially-variant viewing biases in saccadic models. Vision Res. 121, 72–84 (2016)
Le Meur, O., Liu, Z.: Saccadic model of eye movements for free-viewing condition. Vision Res. 116, 152–164 (2015)
Tatler, B., Hayhoe, M., Land, M., Ballard, D.: Eye guidance in natural vision: reinterpreting salience. J. Vision 11(5), 5 (2011)
Tatler, B., Vincent, B.: The prominence of behavioural biases in eye guidance. Vis. Cogn. 17(6–7), 1029–1054 (2009)
Torralba, A.: Contextual priming for object detection. Int. J. Comput. Vis. 53, 153–167 (2003)
Torralba, A.: Modeling global scene factors in attention. JOSA A 20(7), 1407–1418 (2003)
Torralba, A., Oliva, A., Castelhano, M., Henderson, J.: Contextual guidance of eye movements and attention in real-world scenes: the role of global features in object search. Psychol. Rev. 113(4), 766 (2006)
Xia, C., Han, J., Qi, F., Shi, G.: Predicting human saccadic scanpaths based on iterative representation learning. IEEE Trans. Image Process., 1 (2019)
Xu, M., Liu, Y., Hu, R., He, F.: Find who to look at: turning from action to saliency. IEEE Trans. Image Process. 27(9), 4529–4544 (2018)
Yang, S.C.H., Wolpert, D.M., Lengyel, M.: Theoretical perspectives on active sensing. Curr. Opin. Behav. Sci. 11, 100–108 (2016)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Cuculo, V., D’Amelio, A., Grossi, G., Lanzarotti, R. (2019). Worldly Eyes on Video: Learnt vs. Reactive Deployment of Attention to Dynamic Stimuli. In: Ricci, E., Rota Bulò, S., Snoek, C., Lanz, O., Messelodi, S., Sebe, N. (eds) Image Analysis and Processing – ICIAP 2019. ICIAP 2019. Lecture Notes in Computer Science(), vol 11751. Springer, Cham. https://doi.org/10.1007/978-3-030-30642-7_12
Download citation
DOI: https://doi.org/10.1007/978-3-030-30642-7_12
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-30641-0
Online ISBN: 978-3-030-30642-7
eBook Packages: Computer ScienceComputer Science (R0)
