
Abstract
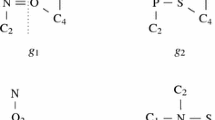
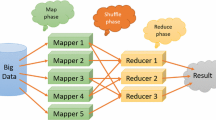
A multi-graph is a set consisting of multiple graphs. Multi-graph similarity search aims to find the multi-graphs similar to the query multi-graphs from the multi-graph datasets. It plays important role in a wide range of application fields, such as finding similar drugs, searching similar molecule groups and so on. However, existing algorithms of multi-graph similarity search are memory-based algorithms, which are not suitable for the large amount of multi-graph scenarios. In this paper, we propose a parallel algorithm based on the MapReduce programming model to solve the problem of the large-scale multi-graph similarity search. Our proposed algorithm consists of two MapReduce jobs, one for indexing and the other for filtering and validation. Specially, we adapt the localization strategy to further improve the performance of our algorithm, which not only reduces the communication cost, but also mitigates the load imbalance. Extensive experimental results show that our algorithm is effective and efficient.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
References
Wu, J., Hong, Z., Pan, S., et al.: Multi-graph learning with positive and unlabeled bags. In: SDM, pp. 217–225 (2014)
Wu, J., Zhu, X., Zhang, C., et al.: Bag constrained structure pattern mining for multi-graph classification. IEEE Trans. Knowl. Data Eng. 26(10), 2382–2396 (2014)
Wu, J., Pan, S., Zhu, X., et al.: Boosting for multi-graph classification. Trans. Cybern. 45(3), 430–443 (2015)
Pang, J., Gu, Y., Yu, G.: A similarity search technique for graph set. J. Northeast. Univ. (Nat. Sci.) 38(5), 625–629 (2017)
Pang, J., Gu, Y., Xu, J., et al.: Parallel multi-graph classification using extreme learning machine and MapReduce. Neurocomputing 261, 171–183 (2017)
Pang, J., Zhao, Y., Xu, J., et al.: Super-graph classification based on composite subgraph features and extreme learning machine. Cogn. Comput. 10(6), 922–936 (2018)
Pang, J., Gu, Y., Xu, J., et al.: Semi-supervised multi-graph classification using optimal feature selection and extreme learning machine. Neurocomputing 277, 89–100 (2018)
Zheng, Z., Tung, A.K.H., Wang, J., et al.: Comparing stars: on approximating graph edit distance. In: Proceedings of International Conference on Very Large Databases (VLDB) Endowment, vol. 2, no. 1, pp. 25–36 (2009)
Wang, G., Wang, B., Yang, X., et al.: Efficiently indexing large sparse graphs for similarity search. IEEE Trans. Knowl. Data Eng. 24(3), 440–451 (2012)
Zhao, X., Xiao, C., Lin, X., et al.: A partition-based approach to structure similarity search. In: Proceedings of International Conference on Very Large Databases (VLDB) Endowment, vol. 7, no. 3, pp. 169–180 (2013)
Zheng, W., Zou, L., Lian, X., et al.: Efficient graph similarity search over large graph databases. IEEE Trans. Knowl. Data Eng. 27(4), 964–978 (2015)
Zhao, P.: Similarity search in large-scale graph databases. In: Zomaya, A.Y., Sakr, S. (eds.) Handbook of Big Data Technologies, pp. 507–529. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-49340-4_15
Sun, Z., Huo, H., Chen, X.: Fast top-k graph similarity search via representative matrices. IEEE Access 6, 21408–21417 (2018)
Roy, S.B., Eliassi-Rad, T., Papadimitriou, S.: Fast best-effort search on graphs with multiple attributes. In: Proceedings of International Conference on Data Engineering (ICDE), pp. 1574–1575 (2016)
Fang, Y., Cheng, R., Li, X., et al.: Effective community search over large spatial graphs. In: Proceedings of International Conference on Very Large Databases (VLDB) Endowment, vol. 10, no. 6, pp. 709–720 (2017)
Yu, W., Wang, F.: Fast exact CoSimRank search on evolving and static graphs. In: Proceedings of WWW, pp. 599–608 (2018)
Achanta, R., Shaji, A., Smith, K., et al.: SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 34(11), 2274–2282 (2012)
Viktor, M.S., Kenneth, C.: Big Data: A Revolution that Will Transform How We Live, Work and Think, pp. 9–10. Houghton Mifflin Harcourt, Boston (2013)
Cao, L., Cho, B., Kim, H., et al.: Delta-SimRank computing on MapReduce. In: Proceedings of International Workshop on Big Data, pp. 28–35 (2012)
Lim, B., Chung, Y.: A parallel maximal matching algorithm for large graphs using Pregel. IEICE Trans. Inf. Syst. 97–D(7), 1910–1913 (2014)
Xiong, X., Zhang, M., Zheng, J., Liu, Y.: Social network user recommendation method based on dynamic influence. In: Meng, X., Li, R., Wang, K., Niu, B., Wang, X., Zhao, G. (eds.) WISA 2018. LNCS, vol. 11242, pp. 455–466. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-02934-0_42
Jamour, F., Skiadopoulos, S., Kalnis, P.: Parallel algorithm for incremental betweenness centrality on large graphs. IEEE Trans. Parallel Distrib. Syst. 29(3), 659–672 (2018)
Afrati, N.F., Sarma, D., et al.: Fuzzy joins using MapReduce. In: Proceedings of International Conference on Data Engineering (ICDE), pp. 498–509 (2012)
Acknowledgment
The work is partially supported by the National Natural Science Foundation of China (No. 61702381, No. 61872070, No. 61772124), the Hubei Natural Science Foundation (No. 2017CFB196), Guangdong Province Key Laboratory of Popular High Performance Computers (No. 2017B030314073), Liao Ning Revitalization Talents Program (XLYC1807158), the Scientific Research Foundation of Wuhan University of Science and Technology (2017xz015), and the Fundamental Research Funds for the Central Universities (N171605001).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Pang, J., Yu, M., Gu, Y. (2019). Efficient Large-Scale Multi-graph Similarity Search Using MapReduce. In: Ni, W., Wang, X., Song, W., Li, Y. (eds) Web Information Systems and Applications. WISA 2019. Lecture Notes in Computer Science(), vol 11817. Springer, Cham. https://doi.org/10.1007/978-3-030-30952-7_23
Download citation
DOI: https://doi.org/10.1007/978-3-030-30952-7_23
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-30951-0
Online ISBN: 978-3-030-30952-7
eBook Packages: Computer ScienceComputer Science (R0)